EntroLLM: Entropy Encoded Weight Compression for Efficient Large Language Model Inference on Edge Devices
作者: Arnab Sanyal, Gourav Datta, Prithwish Mukherjee, Sandeep P. Chinchali, Michael Orshansky
分类: cs.LG
发布日期: 2025-05-05 (更新: 2026-01-26)
备注: 4 pages, 1 reference page
💡 一句话要点
EntroLLM:面向边缘设备,通过熵编码压缩LLM权重以实现高效推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型压缩 边缘计算 量化 熵编码 Huffman编码 推理加速
📋 核心要点
- 现有LLM在边缘设备上部署面临存储和计算资源限制,需要有效的模型压缩方法。
- EntroLLM结合混合量化和熵编码,利用张量级量化降低熵,提高权重可压缩性。
- 实验表明,EntroLLM在边缘设备上实现了显著的存储节省和推理加速,无需重新训练。
📝 摘要(中文)
大型语言模型(LLM)在各项任务中表现出色,但在边缘设备上面临存储和计算的挑战。我们提出了EntroLLM,一个结合了混合量化和熵编码的压缩框架,旨在减少存储空间的同时保持准确性。我们采用无符号和非对称量化的组合。张量级量化产生熵减少效应,提高了权重的可压缩性,并且相比于最先进的方法,Huffman编码的压缩率提高了7倍(8-bit)和11.3倍(4-bit)。Huffman编码进一步降低了内存带宽需求,而并行解码策略能够以最小的延迟实现高效的权重检索。在边缘规模的LLM(smolLM-1.7B、phi3-mini-4k、mistral-7B)上的实验表明,相比于uint8模型,存储节省高达30%,相比于uint4模型,存储节省高达65%,并且在NVIDIA JETSON P3450等内存受限的设备上,推理速度提高了31.9-146.6%。EntroLLM不需要重新训练,并且与现有的后训练量化流程兼容,使其适用于边缘LLM部署。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在边缘设备上部署时面临的存储空间和计算资源受限的问题。现有方法,如传统的量化技术,虽然可以减少模型大小,但在压缩率和精度保持方面存在局限性,并且可能无法充分利用权重中的冗余信息。
核心思路:EntroLLM的核心思路是结合混合量化和熵编码,充分利用量化过程产生的熵减少效应,进一步提高权重的可压缩性。通过张量级别的量化,使得权重分布更加集中,从而更有利于后续的熵编码。同时,采用并行解码策略,保证权重检索的效率。
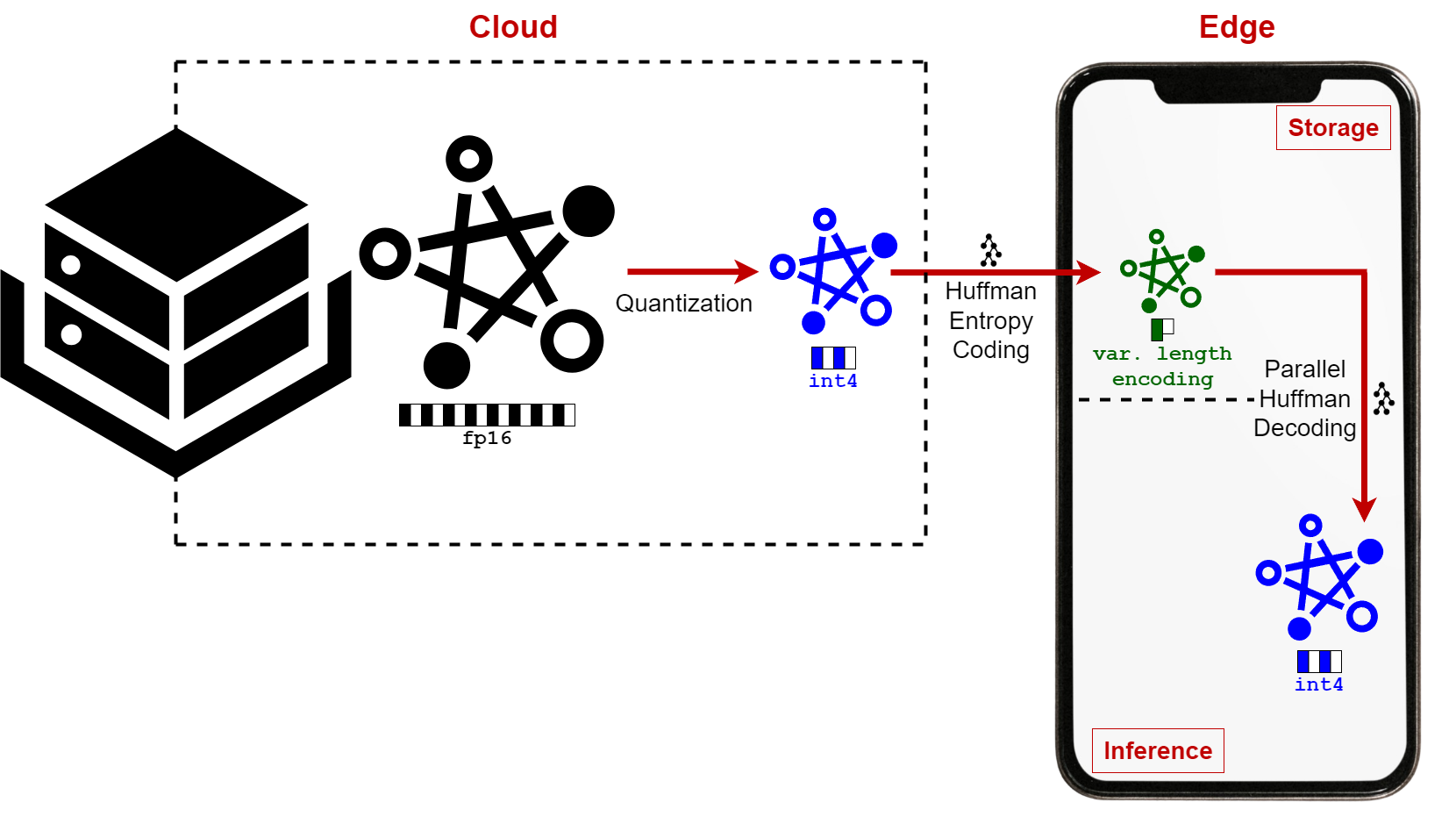
技术框架:EntroLLM框架主要包含以下几个阶段:1) 权重量化:采用混合量化策略,包括无符号和非对称量化,将浮点数权重转换为低比特整数。2) 熵编码:使用Huffman编码对量化后的权重进行编码,进一步压缩模型大小。3) 并行解码:设计并行解码策略,加速权重检索过程。整个流程无需重新训练,可以作为后训练量化流程的一部分。
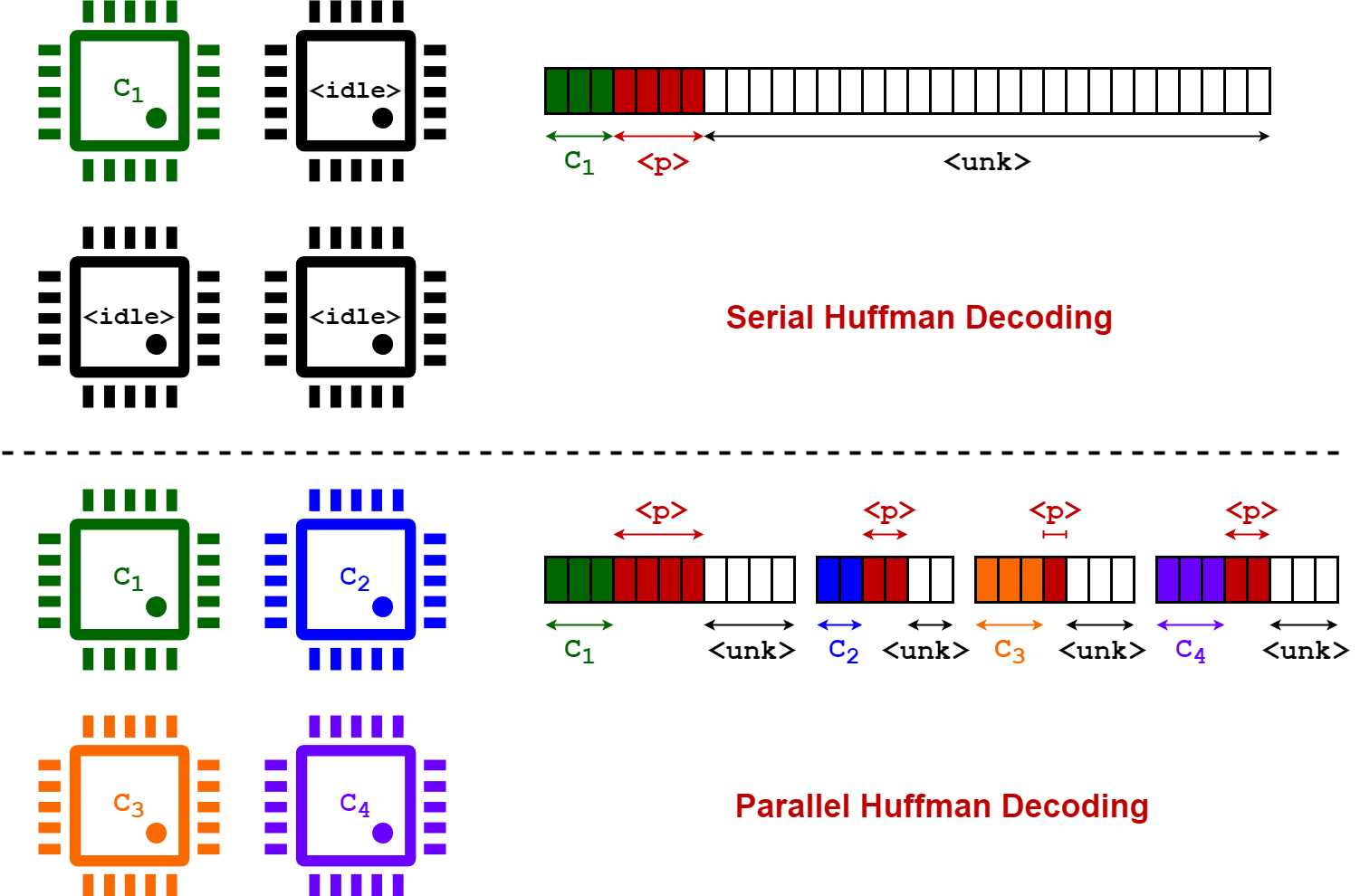
关键创新:EntroLLM的关键创新在于:1) 结合了混合量化和熵编码,充分利用量化过程产生的熵减少效应,实现了更高的压缩率。2) 提出了张量级别的量化方法,使得权重分布更加集中,更有利于熵编码。3) 设计了并行解码策略,保证了权重检索的效率,降低了推理延迟。与现有方法相比,EntroLLM在压缩率和推理速度方面都取得了显著的提升。
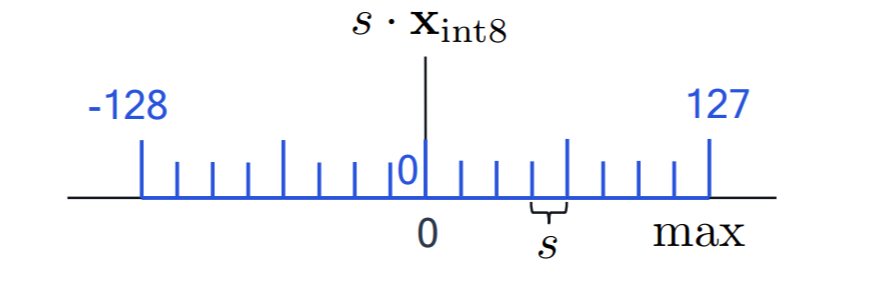
关键设计:EntroLLM的关键设计包括:1) 混合量化策略:根据权重的分布特点,选择合适的量化方法,例如无符号量化或非对称量化。2) Huffman编码:根据量化后权重的频率分布,构建Huffman树,实现高效的熵编码。3) 并行解码策略:将编码后的权重分成多个块,并行解码,加速权重检索过程。具体的参数设置和网络结构与原始模型保持一致,无需修改。
🖼️ 关键图片
📊 实验亮点
EntroLLM在边缘规模的LLM(smolLM-1.7B、phi3-mini-4k、mistral-7B)上进行了实验,结果表明,相比于uint8模型,存储节省高达30%,相比于uint4模型,存储节省高达65%。在NVIDIA JETSON P3450等内存受限的设备上,推理速度提高了31.9-146.6%。这些结果表明EntroLLM在压缩率和推理速度方面都取得了显著的提升。
🎯 应用场景
EntroLLM适用于各种需要在边缘设备上部署大型语言模型的场景,例如智能手机、物联网设备、自动驾驶汽车等。通过降低模型大小和提高推理速度,EntroLLM能够使这些设备在本地运行复杂的LLM,从而提高响应速度、保护用户隐私,并降低对云端服务器的依赖。该技术有望推动LLM在资源受限环境下的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) achieve strong performance across tasks, but face storage and compute challenges on edge devices. We propose EntroLLM, a compression framework combining mixed quantization and entropy coding to reduce storage while preserving accuracy. We use a combination of unsigned and asymmetric quantization. Tensor-level quantization produces an entropy-reducing effect, increasing weight compressibility, and improving downstream Huffman encoding by $7\times$ (8-bit) and $11.3\times$ (4-bit) over state-of-the-art methods. Huffman coding further reduces memory bandwidth demands, while a parallel decoding strategy enables efficient weight retrieval with minimal latency. Experiments on edge-scale LLMs (smolLM-1.7B, phi3-mini-4k, mistral-7B) show up to $30\%$ storage savings over uint8 and $65\%$ over uint4 models, with $31.9-146.6\%$ faster inference on memory-limited devices like the NVIDIA JETSON P3450. EntroLLM requires no retraining and is compatible with existing post-training quantization pipelines, making it practical for edge LLM deployment.