Coupled Distributional Random Expert Distillation for World Model Online Imitation Learning
作者: Shangzhe Li, Zhiao Huang, Hao Su
分类: cs.LG, cs.AI
发布日期: 2025-05-04 (更新: 2026-01-04)
备注: NeurIPS 2025 Workshop of Embodied World Models; Code Available at: https://github.com/TobyLeelsz/CDRED-WM
💡 一句话要点
提出耦合分布随机专家蒸馏,用于世界模型在线模仿学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 世界模型 随机网络蒸馏 在线学习 机器人控制
📋 核心要点
- 现有模仿学习方法在世界模型框架下,依赖对抗性奖励时存在不稳定性问题。
- 提出一种基于随机网络蒸馏(RND)的奖励模型,联合估计专家和行为分布,提升模仿学习的稳定性。
- 在DMControl、Meta-World和ManiSkill2等基准测试中,验证了该方法在运动和操作任务中的有效性和稳定性。
📝 摘要(中文)
模仿学习(IL)通过使智能体从专家演示中学习复杂行为,在机器人、自动驾驶和医疗保健等多个领域取得了显著成功。然而,现有的IL方法常常面临不稳定性挑战,尤其是在世界模型框架中依赖对抗性奖励或价值函数时。本文提出了一种新的在线模仿学习方法,通过基于随机网络蒸馏(RND)的奖励模型进行密度估计,解决了这些限制。我们的奖励模型建立在世界模型潜在空间内专家和行为分布的联合估计之上。我们在包括DMControl、Meta-World和ManiSkill2在内的各种基准上评估了我们的方法,展示了其在运动和操作任务中提供稳定性能并达到专家水平结果的能力。我们的方法展示了相对于对抗方法的改进的稳定性,同时保持了专家水平的性能。
🔬 方法详解
问题定义:现有的模仿学习方法,尤其是在世界模型框架下,依赖对抗性奖励或价值函数时,训练过程容易出现不稳定性。这种不稳定性导致智能体学习到的策略次优,难以达到专家水平,限制了模仿学习在复杂任务中的应用。
核心思路:论文的核心思路是利用随机网络蒸馏(RND)来构建一个奖励模型,该模型能够准确地估计专家和智能体行为在世界模型潜在空间中的分布。通过联合估计这两个分布,可以更有效地指导智能体学习,并提高训练的稳定性。RND作为一种密度估计方法,能够提供更可靠的奖励信号,避免了对抗性方法中常见的模式崩溃问题。
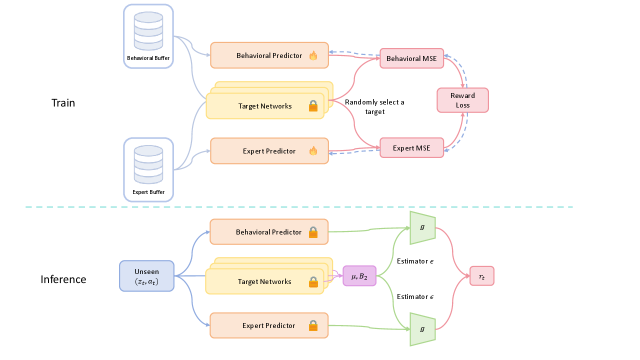
技术框架:整体框架包含一个世界模型和一个奖励模型。世界模型负责学习环境的动态特性,将原始观测映射到潜在空间。奖励模型则基于RND,对专家和智能体的潜在状态分布进行建模。智能体通过最大化奖励来学习策略,奖励由奖励模型提供,鼓励智能体的行为与专家行为相似。训练过程是在线的,智能体在与环境交互的同时不断学习和改进。
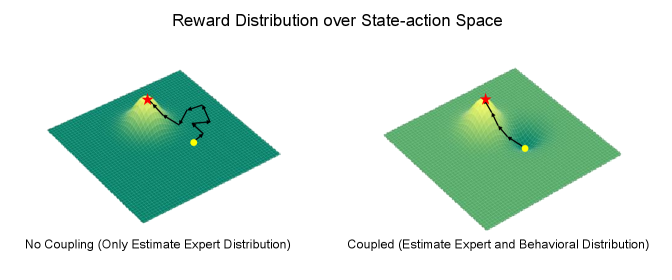
关键创新:最重要的技术创新点在于使用耦合分布的随机专家蒸馏。传统的RND通常用于探索,而本文将其应用于模仿学习,并将其与专家数据耦合,实现了更有效的奖励信号生成。此外,通过在世界模型的潜在空间中进行分布估计,可以更好地利用环境的结构信息,提高学习效率。
关键设计:奖励模型由两个随机初始化的神经网络组成,一个用于专家数据,一个用于智能体数据。这两个网络接收来自世界模型的潜在状态作为输入,并输出一个预测值。奖励信号定义为两个网络输出之间的差异,鼓励智能体的潜在状态分布与专家的潜在状态分布相匹配。损失函数包括模仿学习损失和世界模型的重构损失,通过联合优化这两个损失来提高学习效果。
🖼️ 关键图片
📊 实验亮点
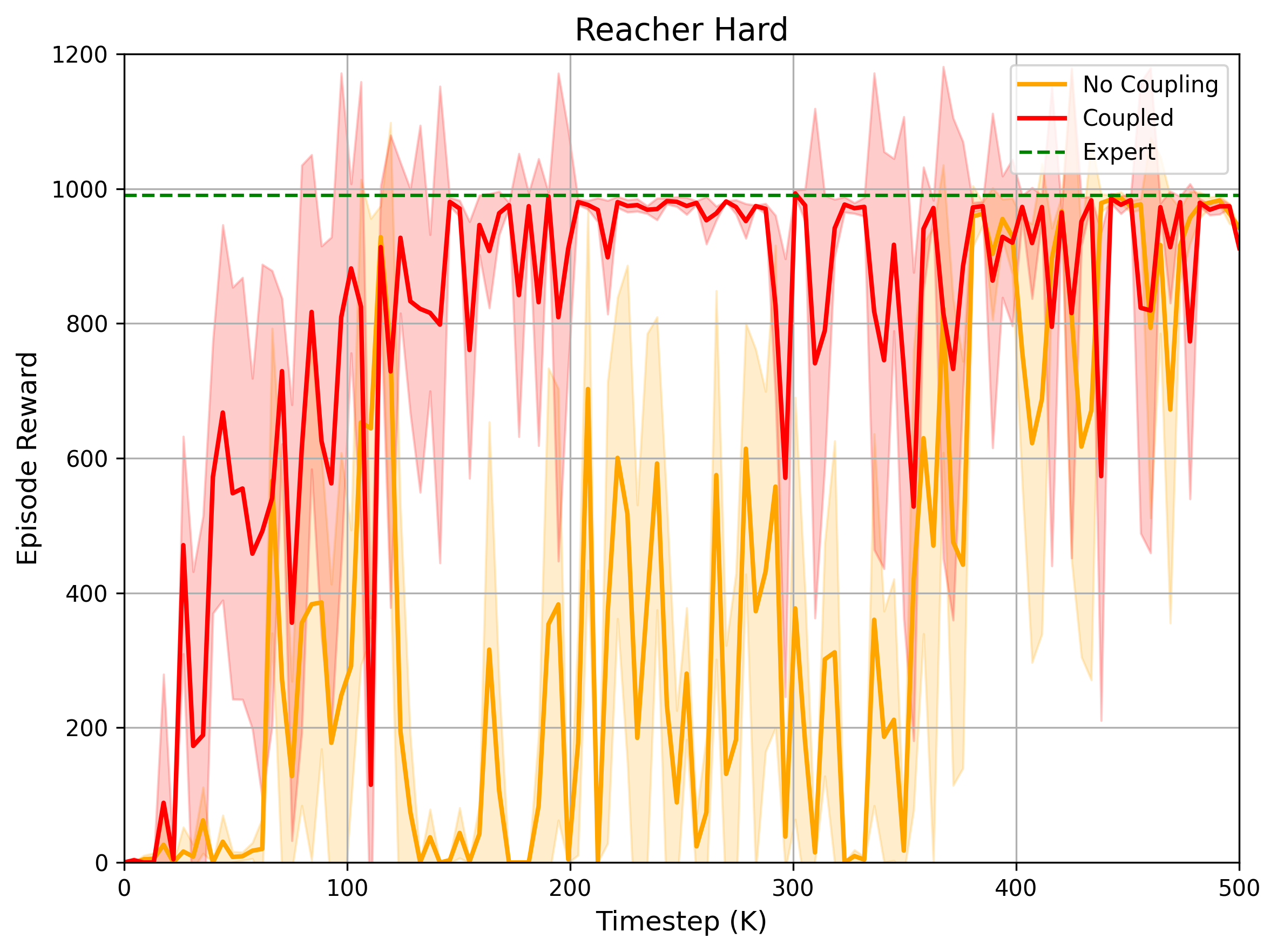
该方法在DMControl、Meta-World和ManiSkill2等多个基准测试中取得了显著成果。实验结果表明,该方法在稳定性和性能方面均优于现有的对抗性模仿学习方法,并在运动和操作任务中达到了专家水平。具体性能数据和提升幅度在论文中详细展示。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过模仿学习,智能体可以从人类专家或高质量的演示数据中学习复杂的行为策略,从而降低开发成本,提高智能体的性能和泛化能力。该方法在需要高稳定性和可靠性的应用场景中具有重要价值。
📄 摘要(原文)
Imitation Learning (IL) has achieved remarkable success across various domains, including robotics, autonomous driving, and healthcare, by enabling agents to learn complex behaviors from expert demonstrations. However, existing IL methods often face instability challenges, particularly when relying on adversarial reward or value formulations in world model frameworks. In this work, we propose a novel approach to online imitation learning that addresses these limitations through a reward model based on random network distillation (RND) for density estimation. Our reward model is built on the joint estimation of expert and behavioral distributions within the latent space of the world model. We evaluate our method across diverse benchmarks, including DMControl, Meta-World, and ManiSkill2, showcasing its ability to deliver stable performance and achieve expert-level results in both locomotion and manipulation tasks. Our approach demonstrates improved stability over adversarial methods while maintaining expert-level performance.