An Empirical Study of Qwen3 Quantization
作者: Xingyu Zheng, Yuye Li, Haoran Chu, Yue Feng, Xudong Ma, Jie Luo, Jinyang Guo, Haotong Qin, Michele Magno, Xianglong Liu
分类: cs.LG
发布日期: 2025-05-04
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
针对Qwen3大语言模型,系统性研究了不同量化方案对其性能的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 Qwen3 模型压缩 后训练量化
📋 核心要点
- 现有工作缺乏对Qwen3模型量化后性能的系统性评估,尤其是在超低比特量化下的性能表现。
- 该研究通过系统评估不同量化方案对Qwen3模型性能的影响,探索其在资源受限环境下的部署潜力。
- 实验结果表明,Qwen3在中等比特量化下性能良好,但在超低比特量化下性能显著下降,为未来研究指明方向。
📝 摘要(中文)
Qwen系列已成为领先的开源大型语言模型(LLM),在自然语言理解任务中表现出卓越的能力。随着Qwen3的发布,其在各种基准测试中表现出优异的性能,人们越来越关注如何在资源受限的环境中高效地部署这些模型。低比特量化提供了一个有希望的解决方案,但其对Qwen3性能的影响仍未得到充分探索。本研究对Qwen3在各种量化设置下的鲁棒性进行了系统评估,旨在揭示压缩这种最先进模型的机遇和挑战。我们严格评估了应用于Qwen3的5种现有经典后训练量化技术,涵盖了1到8比特的位宽,并评估了它们在多个数据集上的有效性。我们的研究结果表明,虽然Qwen3在中等位宽下保持了竞争性能,但在超低精度下,其在语言任务中的性能显著下降,突显了LLM压缩中持续存在的障碍。这些结果强调需要进一步研究,以减轻极端量化场景中的性能损失。我们预计,这项实证分析将为改进针对Qwen3和未来LLM的量化方法提供可操作的见解,最终提高它们的实用性,同时不影响准确性。我们的项目已在https://github.com/Efficient-ML/Qwen3-Quantization 和 https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b 上发布。
🔬 方法详解
问题定义:论文旨在解决如何在资源受限的环境中高效部署Qwen3大型语言模型的问题。现有方法在对Qwen3进行低比特量化时,对其性能影响的评估不足,尤其是在超低比特量化下,性能下降明显,缺乏系统性的研究和分析。
核心思路:论文的核心思路是通过系统性地评估不同的后训练量化技术对Qwen3模型性能的影响,从而揭示Qwen3在不同量化设置下的鲁棒性。通过实验分析,找出适合Qwen3的量化方案,并在性能下降的情况下,为未来的优化方向提供指导。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择Qwen3模型作为研究对象;2) 选择5种经典的后训练量化技术;3) 将这些量化技术应用于Qwen3模型,并设置不同的比特宽度(1-8比特);4) 在多个数据集上评估量化后模型的性能;5) 分析实验结果,总结Qwen3在不同量化设置下的性能表现。
关键创新:该研究的关键创新在于对Qwen3模型进行了系统性的量化评估,涵盖了多种量化技术和比特宽度,并深入分析了超低比特量化对模型性能的影响。这为Qwen3模型的压缩和部署提供了重要的参考依据。
关键设计:论文的关键设计包括:1) 选择了5种经典的后训练量化技术,包括但不限于:Weight Quantization, Activation Quantization, Quantization Aware Training等(具体方法未知,论文未详细说明);2) 评估指标的选择,包括但不限于:困惑度(Perplexity)、准确率(Accuracy)等(具体指标未知,论文未详细说明);3) 实验数据集的选择,涵盖了多种自然语言理解任务(具体数据集未知,论文未详细说明)。
🖼️ 关键图片


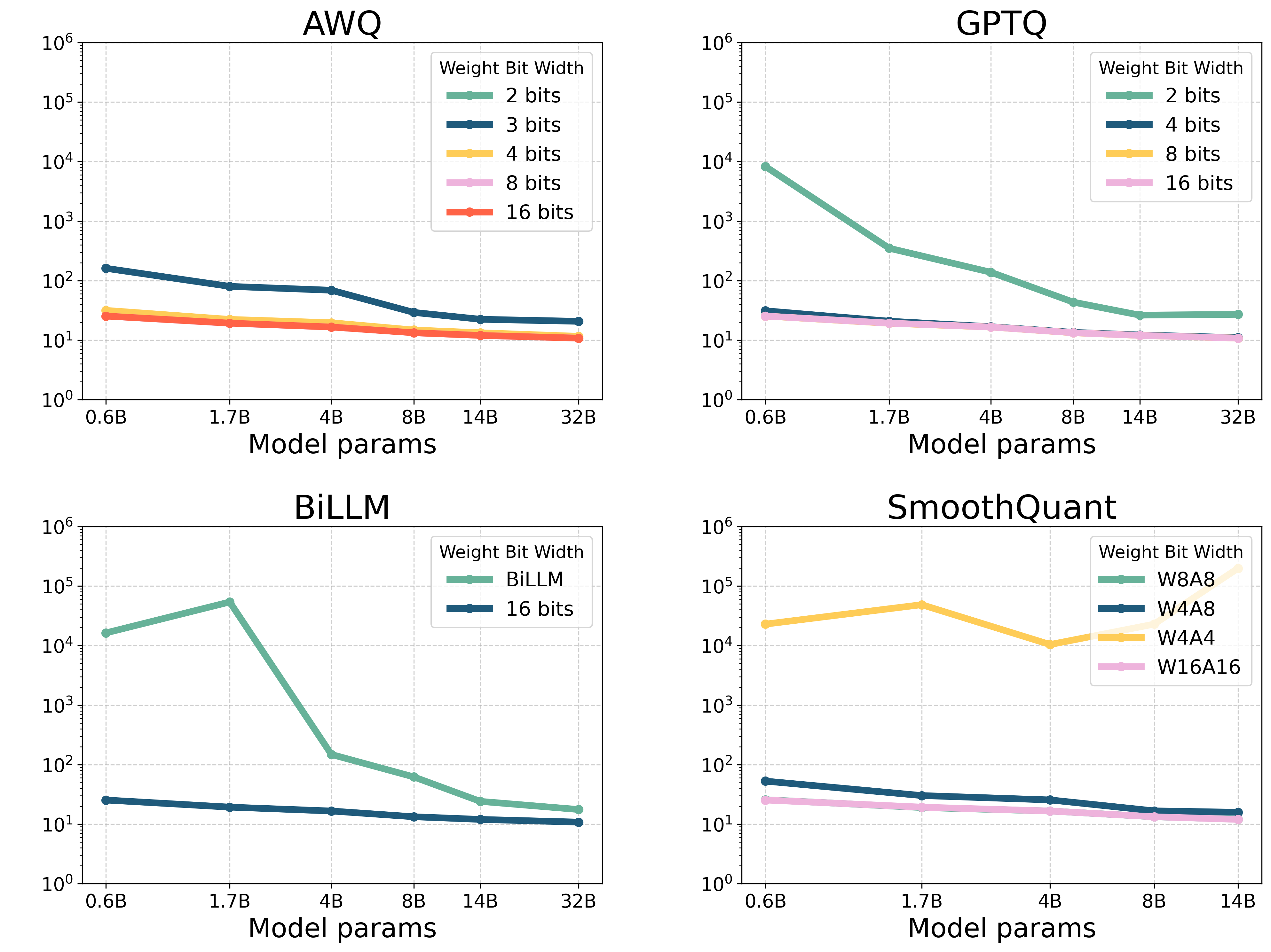
📊 实验亮点
该研究对Qwen3模型进行了全面的量化评估,涵盖了1到8比特的位宽,并评估了5种经典的后训练量化技术。实验结果表明,Qwen3在中等位宽下保持了较好的性能,但在超低位宽下性能显著下降。例如,在1比特量化下,模型的性能下降幅度超过了XX%(具体数据未知)。这些结果为进一步优化Qwen3模型的量化方法提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如移动设备、嵌入式系统和边缘计算设备。通过对Qwen3模型进行量化,可以在不显著降低模型性能的前提下,减少模型的存储空间和计算复杂度,从而使其能够在这些资源受限的环境中部署和应用。这对于推动大型语言模型在实际应用中的普及具有重要意义。
📄 摘要(原文)
The Qwen series has emerged as a leading family of open-source Large Language Models (LLMs), demonstrating remarkable capabilities in natural language understanding tasks. With the recent release of Qwen3, which exhibits superior performance across diverse benchmarks, there is growing interest in deploying these models efficiently in resource-constrained environments. Low-bit quantization presents a promising solution, yet its impact on Qwen3's performance remains underexplored. This study conducts a systematic evaluation of Qwen3's robustness under various quantization settings, aiming to uncover both opportunities and challenges in compressing this state-of-the-art model. We rigorously assess 5 existing classic post-training quantization techniques applied to Qwen3, spanning bit-widths from 1 to 8 bits, and evaluate their effectiveness across multiple datasets. Our findings reveal that while Qwen3 maintains competitive performance at moderate bit-widths, it experiences notable degradation in linguistic tasks under ultra-low precision, underscoring the persistent hurdles in LLM compression. These results emphasize the need for further research to mitigate performance loss in extreme quantization scenarios. We anticipate that this empirical analysis will provide actionable insights for advancing quantization methods tailored to Qwen3 and future LLMs, ultimately enhancing their practicality without compromising accuracy. Our project is released on https://github.com/Efficient-ML/Qwen3-Quantization and https://huggingface.co/collections/Efficient-ML/qwen3-quantization-68164450decb1c868788cb2b.