Restoring Calibration for Aligned Large Language Models: A Calibration-Aware Fine-Tuning Approach
作者: Jiancong Xiao, Bojian Hou, Zhanliang Wang, Ruochen Jin, Qi Long, Weijie J. Su, Li Shen
分类: cs.LG, cs.AI, stat.ML
发布日期: 2025-05-04 (更新: 2025-10-16)
期刊: ICML 2025
💡 一句话要点
提出校准感知微调方法,恢复对齐后大语言模型的校准性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 校准 偏好对齐 微调 预期校准误差
📋 核心要点
- 现有大语言模型在偏好对齐后,校准性显著下降,导致模型过度自信,影响可靠性。
- 论文提出校准感知微调方法,针对可校准和不可校准两种状态,分别设计微调策略。
- 实验结果表明,该方法能有效恢复大语言模型的校准性,同时保持甚至提升模型性能。
📝 摘要(中文)
大语言模型(LLM)成功的关键技术之一是偏好对齐。然而,偏好对齐的一个显著副作用是校准性变差:预训练模型通常具有良好的校准性,但LLM在与人类偏好对齐后往往变得校准不良。本文研究了偏好对齐影响校准的原因以及如何解决这个问题。对于第一个问题,我们观察到对齐中的偏好崩溃问题会不利地泛化到校准场景,导致LLM表现出过度自信和不良校准。为了解决这个问题,我们证明了使用领域特定知识进行微调以缓解过度自信问题的重要性。为了进一步分析这是否影响模型的性能,我们将模型分为两种状态:可校准和不可校准,由预期校准误差(ECE)的界限定义。在可校准状态下,我们提出了一种校准感知微调方法,以在不影响LLM性能的情况下实现适当的校准。然而,随着模型为了更好的性能而进一步微调,它们进入不可校准状态。对于这种情况,我们开发了一种基于EM算法的ECE正则化方法,用于微调损失,以保持较低的校准误差。大量的实验验证了所提出方法的有效性。
🔬 方法详解
问题定义:大语言模型在经过偏好对齐后,其校准性会显著下降,表现为过度自信,即模型给出的概率预测与其真实准确率不符。现有方法缺乏对这一问题的有效解决,导致模型在实际应用中可能产生误导性结果。
核心思路:论文的核心思路是针对不同校准状态的模型,采用不同的微调策略。对于可校准状态的模型,采用校准感知微调,在保证模型性能的同时,优化校准性。对于不可校准状态的模型,采用基于EM算法的ECE正则化方法,直接优化校准误差。
技术框架:整体框架包含两个主要阶段:首先,根据ECE值将模型分为可校准和不可校准两种状态。然后,对于可校准状态的模型,采用校准感知微调,具体方法未知。对于不可校准状态的模型,在微调损失函数中加入基于EM算法的ECE正则化项,以约束模型的校准误差。
关键创新:论文的关键创新在于提出了针对不同校准状态的自适应微调策略。通过区分可校准和不可校准状态,并采用不同的优化目标,能够更有效地恢复模型的校准性,同时避免对模型性能产生负面影响。
关键设计:ECE正则化项的设计是关键。论文采用基于EM算法的方法来估计ECE,并将其作为正则化项加入到微调损失函数中。具体的EM算法实现细节和超参数设置未知。
🖼️ 关键图片
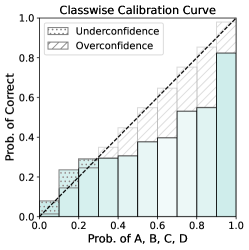


📊 实验亮点
论文通过实验验证了所提出方法的有效性。具体性能数据未知,但实验结果表明,该方法能够显著降低大语言模型的ECE值,恢复其校准性,同时保持甚至提升模型在各项任务上的性能。与现有方法相比,该方法在校准性和性能之间取得了更好的平衡。
🎯 应用场景
该研究成果可应用于各种需要可靠概率预测的大语言模型应用场景,例如医疗诊断、金融风险评估、自动驾驶等。通过提高模型的校准性,可以提升决策的准确性和可靠性,降低潜在风险,增强用户信任度。未来,该方法可以推广到其他类型的机器学习模型,并与其他校准技术相结合,进一步提升校准效果。
📄 摘要(原文)
One of the key technologies for the success of Large Language Models (LLMs) is preference alignment. However, a notable side effect of preference alignment is poor calibration: while the pre-trained models are typically well-calibrated, LLMs tend to become poorly calibrated after alignment with human preferences. In this paper, we investigate why preference alignment affects calibration and how to address this issue. For the first question, we observe that the preference collapse issue in alignment undesirably generalizes to the calibration scenario, causing LLMs to exhibit overconfidence and poor calibration. To address this, we demonstrate the importance of fine-tuning with domain-specific knowledge to alleviate the overconfidence issue. To further analyze whether this affects the model's performance, we categorize models into two regimes: calibratable and non-calibratable, defined by bounds of Expected Calibration Error (ECE). In the calibratable regime, we propose a calibration-aware fine-tuning approach to achieve proper calibration without compromising LLMs' performance. However, as models are further fine-tuned for better performance, they enter the non-calibratable regime. For this case, we develop an EM-algorithm-based ECE regularization for the fine-tuning loss to maintain low calibration error. Extensive experiments validate the effectiveness of the proposed methods.