How Transformers Learn Regular Language Recognition: A Theoretical Study on Training Dynamics and Implicit Bias
作者: Ruiquan Huang, Yingbin Liang, Jing Yang
分类: cs.LG, cs.CL, stat.ML
发布日期: 2025-05-02 (更新: 2025-05-28)
备注: accepted by ICML 2025
💡 一句话要点
理论分析Transformer学习正则语言识别:训练动态与隐式偏差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer 正则语言识别 训练动态 隐式偏差 梯度下降 注意力机制 理论分析
📋 核心要点
- 现有方法难以解释Transformer学习正则语言的内在机制,尤其是在训练动态和隐式偏差方面。
- 本文通过理论分析单层Transformer在梯度下降下的训练过程,揭示其学习正则语言的内在机制。
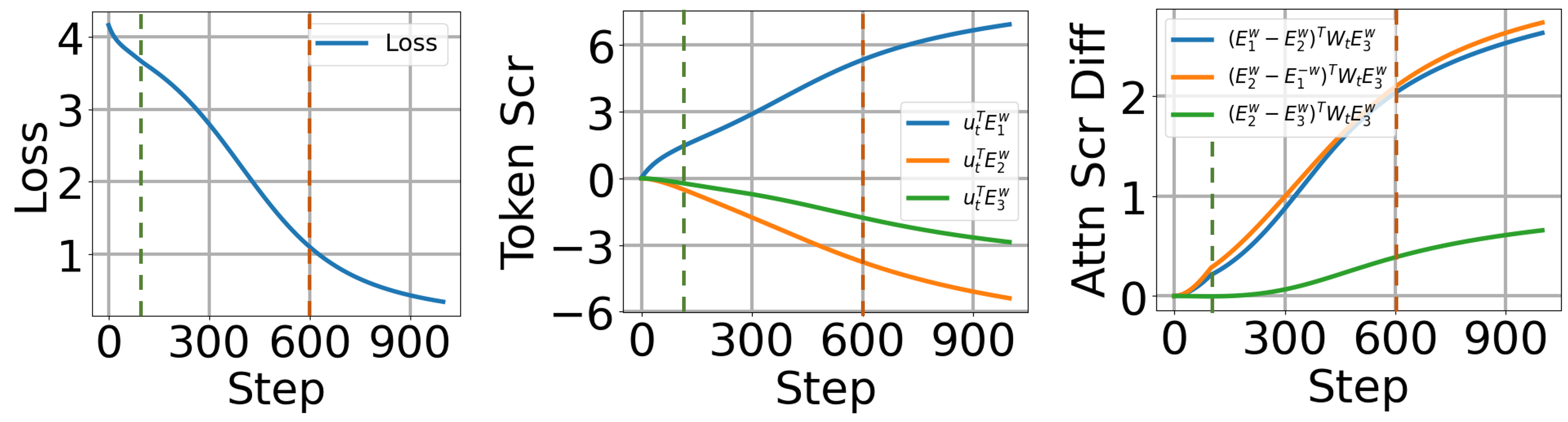
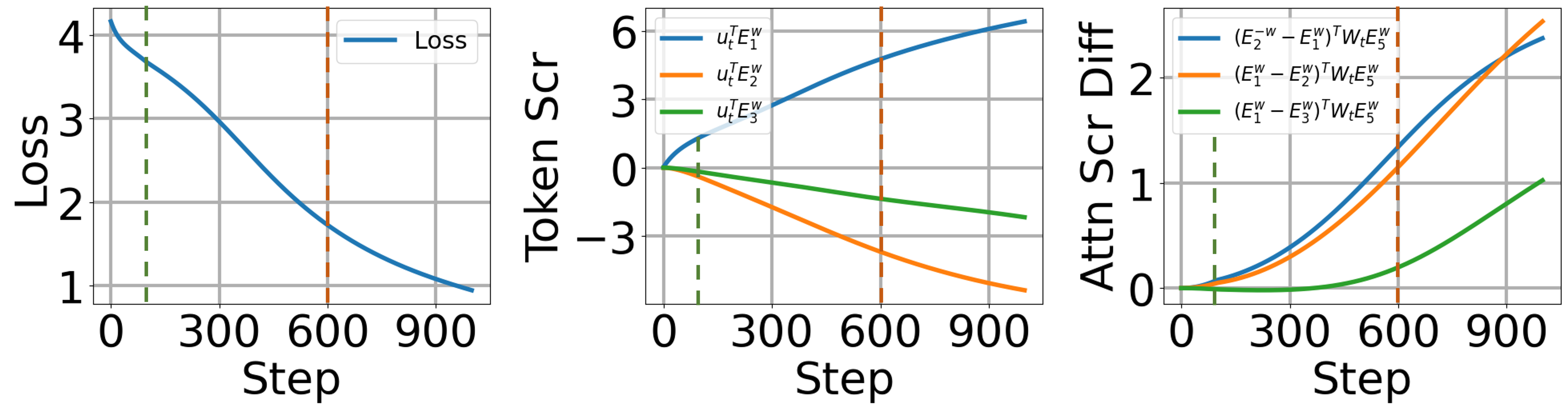
- 实验验证了理论分析结果,表明注意力层和线性层的训练存在两个阶段,并符合特定的增长模式。
📝 摘要(中文)
本文着重研究了Transformer如何学习正则语言识别任务,这类任务在自然语言处理(NLP)中至关重要,并被广泛用于评估大型语言模型(LLM)的性能。同时,这些任务在解释Transformer的工作机制方面也发挥着关键作用。本文关注“偶数对”和“奇偶校验”这两个具有代表性的正则语言识别任务,其目标是确定给定序列中某些子序列的出现次数是否为偶数。我们的目标是通过理论分析单层Transformer在梯度下降下的训练动态,来探索其如何解决这些任务。虽然单层Transformer可以直接解决偶数对问题,但奇偶校验问题需要通过整合思维链(CoT)来解决,可以将其融入到为偶数对任务训练良好的Transformer的推理阶段,或者融入到单层Transformer的训练中。对于这两个问题,我们的分析表明,注意力和线性层的联合训练表现出两个不同的阶段。在第一阶段,注意力层快速增长,将数据序列映射到可分离的向量。在第二阶段,注意力层变得稳定,而线性层以对数方式增长,并在方向上接近最大间隔超平面,该超平面将注意力层输出正确地分离为正样本和负样本,并且损失以O(1/t)的速度下降。我们的实验验证了这些理论结果。
🔬 方法详解
问题定义:论文旨在理解单层Transformer如何学习正则语言识别任务,特别是“偶数对”和“奇偶校验”问题。现有方法缺乏对Transformer训练动态和隐式偏差的理论分析,难以解释其工作机制。
核心思路:论文的核心思路是通过理论分析梯度下降优化下单层Transformer的训练过程,揭示注意力层和线性层在不同阶段的学习行为。通过数学建模和推导,分析参数的增长模式和收敛性质,从而理解Transformer如何隐式地学习到正则语言的规则。
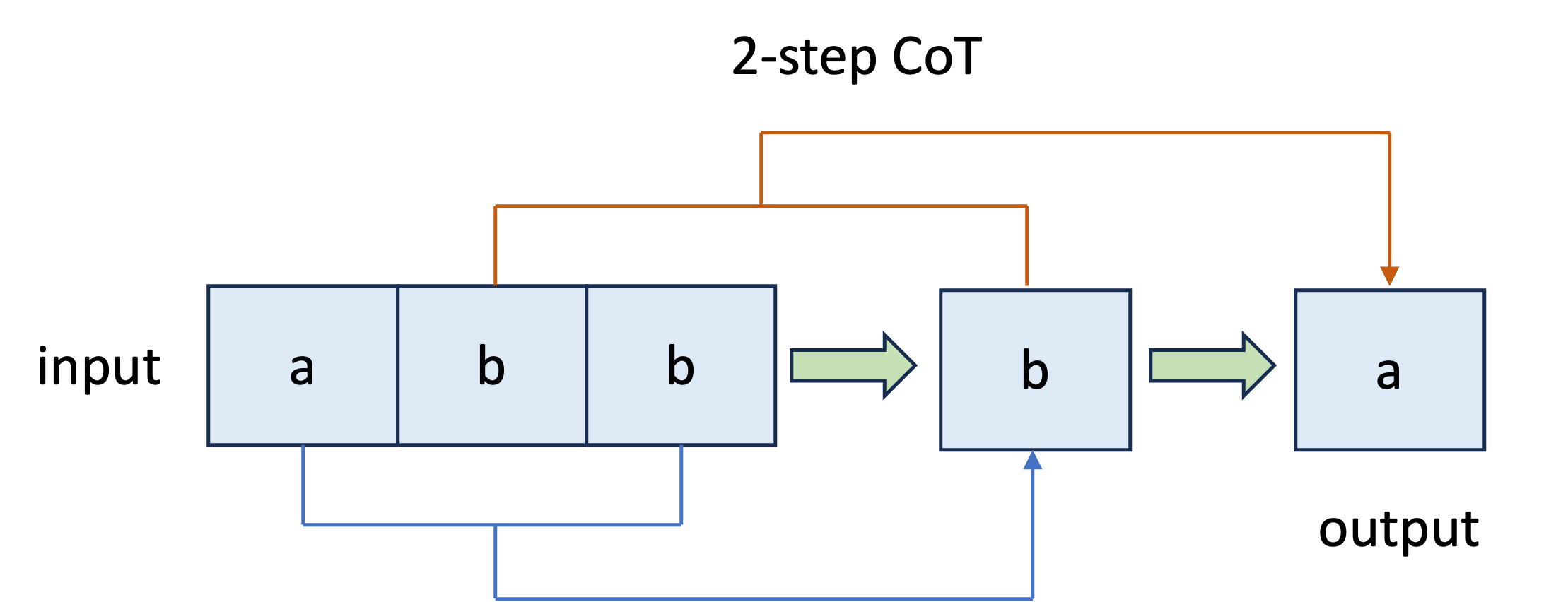
技术框架:论文主要研究单层Transformer,包含一个注意力层和一个线性层。对于“奇偶校验”问题,引入了思维链(CoT)机制,将其整合到推理或训练阶段。整体流程包括:1) 定义正则语言识别任务;2) 构建单层Transformer模型;3) 使用梯度下降算法进行训练;4) 理论分析训练过程中注意力层和线性层的参数变化;5) 实验验证理论分析结果。
关键创新:论文最重要的创新在于对Transformer学习正则语言的训练动态进行了理论分析,揭示了注意力层和线性层在训练过程中不同的学习阶段和增长模式。此外,还分析了Transformer的隐式偏差,即模型在训练过程中倾向于学习最大间隔超平面。
关键设计:论文的关键设计包括:1) 使用梯度下降作为优化算法;2) 针对“奇偶校验”问题,探索了两种CoT整合方式:推理阶段和训练阶段;3) 通过数学推导分析损失函数的下降速率和参数的增长模式;4) 实验中,精心设计了数据集和评估指标,以验证理论分析的有效性。
🖼️ 关键图片
📊 实验亮点
实验结果验证了理论分析的正确性,表明注意力层和线性层的训练过程存在两个阶段:注意力层快速增长阶段和线性层对数增长阶段。实验还验证了损失函数以O(1/t)的速度下降,以及线性层参数趋向于最大间隔超平面的结论。这些结果为理解Transformer的学习行为提供了重要的实验证据。
🎯 应用场景
该研究成果有助于深入理解Transformer的工作机制,为设计更高效、更可解释的Transformer模型提供理论指导。此外,该研究还可以应用于其他序列建模任务,例如语音识别、机器翻译等,并为开发更强大的自然语言处理系统奠定基础。未来,可以进一步研究多层Transformer的学习动态,以及更复杂的正则语言识别任务。
📄 摘要(原文)
Language recognition tasks are fundamental in natural language processing (NLP) and have been widely used to benchmark the performance of large language models (LLMs). These tasks also play a crucial role in explaining the working mechanisms of transformers. In this work, we focus on two representative tasks in the category of regular language recognition, known as
even pairs' andparity check', the aim of which is to determine whether the occurrences of certain subsequences in a given sequence are even. Our goal is to explore how a one-layer transformer, consisting of an attention layer followed by a linear layer, learns to solve these tasks by theoretically analyzing its training dynamics under gradient descent. While even pairs can be solved directly by a one-layer transformer, parity check need to be solved by integrating Chain-of-Thought (CoT), either into the inference stage of a transformer well-trained for the even pairs task, or into the training of a one-layer transformer. For both problems, our analysis shows that the joint training of attention and linear layers exhibits two distinct phases. In the first phase, the attention layer grows rapidly, mapping data sequences into separable vectors. In the second phase, the attention layer becomes stable, while the linear layer grows logarithmically and approaches in direction to a max-margin hyperplane that correctly separates the attention layer outputs into positive and negative samples, and the loss decreases at a rate of $O(1/t)$. Our experiments validate those theoretical results.