R&B: Domain Regrouping and Data Mixture Balancing for Efficient Foundation Model Training
作者: Albert Ge, Tzu-Heng Huang, John Cooper, Avi Trost, Ziyi Chu, Satya Sai Srinath Namburi GNVV, Ziyang Cai, Kendall Park, Nicholas Roberts, Frederic Sala
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-05-01
💡 一句话要点
R&B:通过领域重组和数据混合平衡实现高效的基础模型训练
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据混合 领域重组 梯度优化 基础模型训练 语义相似性
📋 核心要点
- 现有数据混合方法依赖预定义的数据领域,无法捕捉细粒度的语义信息,导致性能瓶颈。
- R&B框架通过语义相似性重组数据领域,并利用领域梯度优化数据混合比例,提升训练效率。
- 实验表明,R&B在多种数据集上仅需极小的额外计算开销,即可达到或超越现有最佳数据混合策略的性能。
📝 摘要(中文)
数据混合策略已成功降低了训练语言模型的成本。然而,这些方法存在两个缺陷。首先,它们依赖于预先确定的数据领域(例如,数据来源、任务类型),这可能无法捕捉到关键的语义细微差别,从而影响性能。其次,这些方法的计算成本随着领域数量的增加而呈指数级增长。我们通过R&B框架解决了这些挑战,该框架基于语义相似性重新划分训练数据(Regroup)以创建更细粒度的领域,并通过利用由训练过程中获得的领域梯度导出的Gram矩阵,有效地优化数据组成(Balance)。与先前的工作不同,它无需额外的计算即可获得评估信息,例如损失或梯度。我们在标准正则性条件下分析了该技术,并提供了理论见解,证明了R&B相对于非自适应混合方法的有效性。在五个不同的数据集(从自然语言到推理和多模态任务)上,我们通过实验证明了R&B的有效性。仅需0.01%的额外计算开销,R&B即可匹配或超过最先进的数据混合策略的性能。
🔬 方法详解
问题定义:现有数据混合方法依赖于预先设定的数据领域,例如数据来源或任务类型,这忽略了数据之间更细微的语义关系。此外,随着数据领域数量的增加,确定最佳数据混合比例的计算成本会显著增加,限制了这些方法在大规模基础模型训练中的应用。
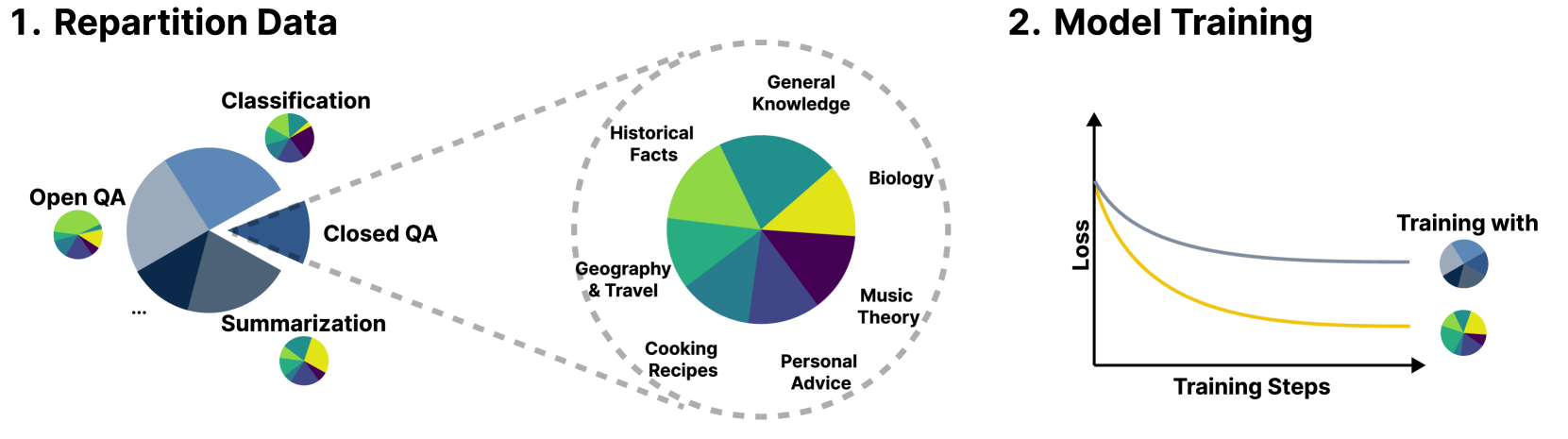
核心思路:R&B的核心思路是首先基于数据的语义相似性对数据进行重新分组,形成更细粒度的数据领域。然后,利用训练过程中获得的领域梯度信息,构建Gram矩阵,并基于此优化各个数据领域的混合比例。这种方法避免了对预定义数据领域的依赖,并能更有效地探索数据混合空间。
技术框架:R&B框架主要包含两个阶段:Regroup(领域重组)和Balance(数据平衡)。Regroup阶段使用某种聚类算法(具体算法未知)基于数据的语义相似性将训练数据划分为新的领域。Balance阶段利用训练过程中计算得到的领域梯度,构建Gram矩阵,并通过优化算法(具体算法未知)确定各个领域的最佳混合比例。整个过程无需额外的评估计算,从而降低了计算成本。
关键创新:R&B的关键创新在于其自适应的数据领域划分和高效的数据混合比例优化方法。与传统方法相比,R&B能够自动发现数据之间的语义关系,并根据这些关系动态调整数据混合比例,从而提高模型的训练效率和性能。此外,R&B利用领域梯度信息进行优化,避免了额外的评估计算,显著降低了计算成本。
关键设计:论文中没有明确说明Regroup阶段使用的具体聚类算法,以及Balance阶段使用的优化算法。领域梯度的计算方式也未详细描述。这些是需要进一步研究的细节。Gram矩阵的具体构建方式以及如何利用它来优化数据混合比例也需要更详细的解释。
🖼️ 关键图片

📊 实验亮点
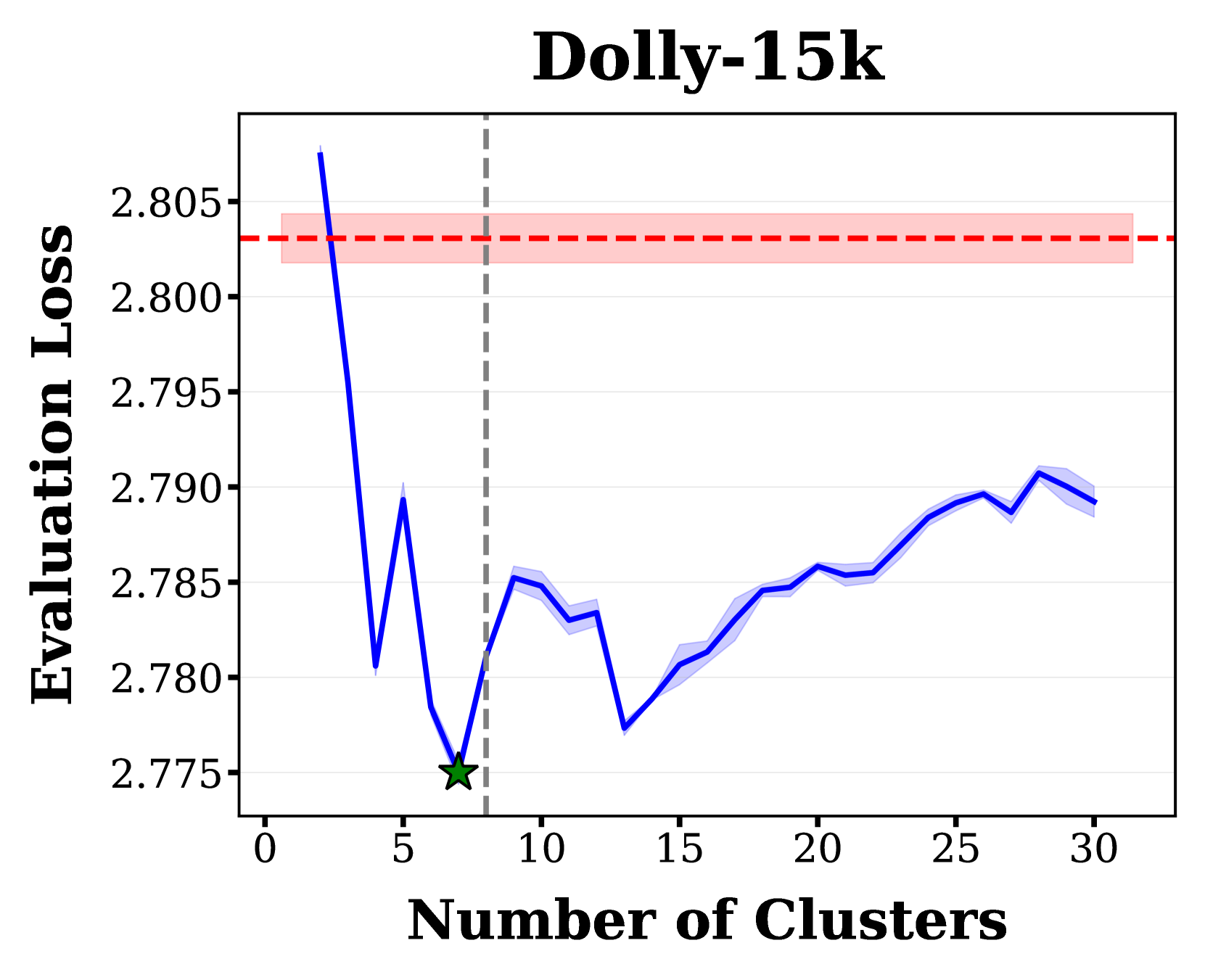
R&B在五个不同的数据集上进行了实验,涵盖自然语言、推理和多模态任务。实验结果表明,R&B仅需0.01%的额外计算开销,即可匹配或超过最先进的数据混合策略的性能。这意味着R&B在提高模型性能的同时,显著降低了训练成本,具有很高的实用价值。
🎯 应用场景
R&B框架可应用于各种需要大规模数据训练的机器学习任务,尤其是在自然语言处理、计算机视觉和多模态学习等领域。通过提高数据利用率和降低训练成本,R&B有助于加速基础模型的开发和部署,并推动人工智能技术的广泛应用。该方法在资源受限的环境下也具有重要意义,能够以较低的计算成本实现高性能的模型训练。
📄 摘要(原文)
Data mixing strategies have successfully reduced the costs involved in training language models. While promising, such methods suffer from two flaws. First, they rely on predetermined data domains (e.g., data sources, task types), which may fail to capture critical semantic nuances, leaving performance on the table. Second, these methods scale with the number of domains in a computationally prohibitive way. We address these challenges via R&B, a framework that re-partitions training data based on semantic similarity (Regroup) to create finer-grained domains, and efficiently optimizes the data composition (Balance) by leveraging a Gram matrix induced by domain gradients obtained throughout training. Unlike prior works, it removes the need for additional compute to obtain evaluation information such as losses or gradients. We analyze this technique under standard regularity conditions and provide theoretical insights that justify R&B's effectiveness compared to non-adaptive mixing approaches. Empirically, we demonstrate the effectiveness of R&B on five diverse datasets ranging from natural language to reasoning and multimodal tasks. With as little as 0.01% additional compute overhead, R&B matches or exceeds the performance of state-of-the-art data mixing strategies.