T2VPhysBench: A First-Principles Benchmark for Physical Consistency in Text-to-Video Generation
作者: Xuyang Guo, Jiayan Huo, Zhenmei Shi, Zhao Song, Jiahao Zhang, Jiale Zhao
分类: cs.LG, cs.AI, cs.CL, cs.CV
发布日期: 2025-05-01
💡 一句话要点
T2VPhysBench:首个用于评估文本生成视频物理一致性的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本生成视频 物理一致性 基准测试 人工评估 第一性原理
📋 核心要点
- 现有文本生成视频模型缺乏对物理定律的有效评估,导致生成内容不符合物理常识。
- 提出T2VPhysBench基准,通过人工评估,从第一性原理出发,系统评估模型对物理定律的遵守程度。
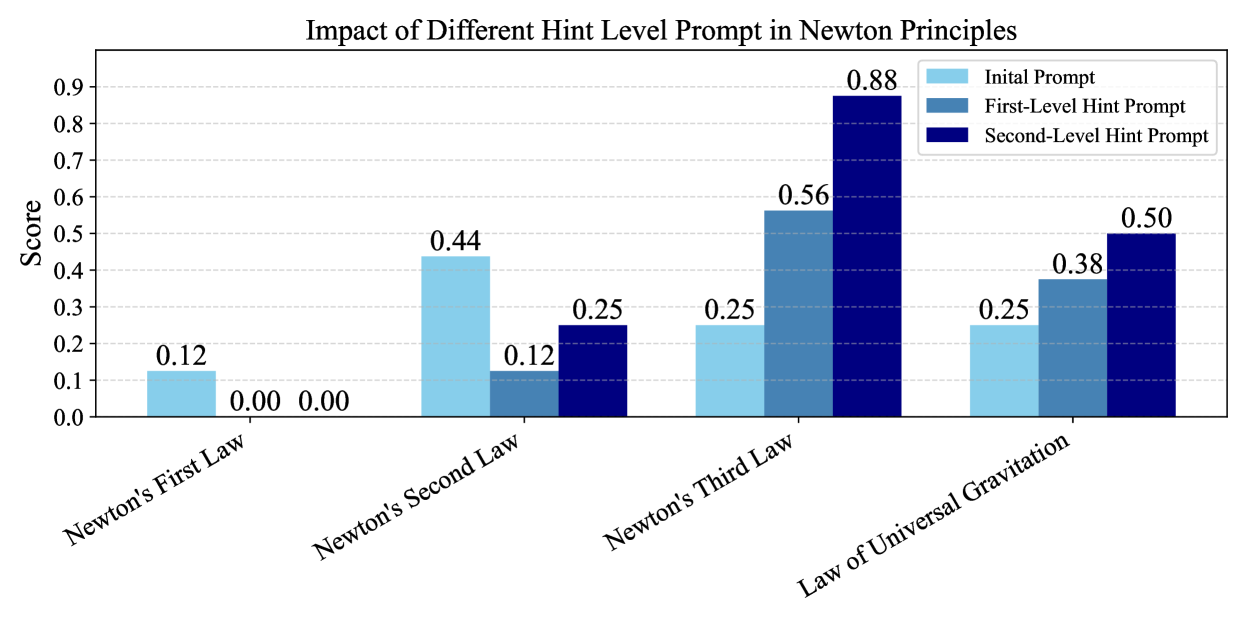
- 实验表明,现有模型在物理定律遵守方面表现不佳,即使加入提示也难以改善,反事实测试更易出错。
📝 摘要(中文)
近年来,文本生成视频模型取得了显著进展,在美学吸引力和准确遵循指令方面表现出色,成为数字艺术创作和在线用户互动的重要组成部分。然而,它们在遵守基本物理定律方面的能力在很大程度上未经测试。许多输出仍然违反刚体碰撞、能量守恒和引力动力学等基本约束,导致不真实甚至具有误导性的内容。现有的物理评估基准通常依赖于应用于简单生活场景提示的自动像素级指标,因此忽略了人类判断和第一性原理物理。为了填补这一空白,我们引入了T2VPhysBench,这是一个基于第一性原理的基准,系统地评估了最先进的文本生成视频系统(包括开源和商业系统)是否遵守包括牛顿力学、守恒定律和唯象效应在内的十二个核心物理定律。我们的基准采用严格的人工评估协议,并包括三项有针对性的研究:(1)总体合规性评估,表明所有模型在每个定律类别中的平均得分均低于0.60;(2)提示-提示消融实验,表明即使是详细的、特定于定律的提示也无法弥补物理违规行为;(3)反事实鲁棒性测试,表明模型在被指示这样做时,通常会生成明确违反物理规则的视频。结果揭示了当前架构的持续局限性,并为指导未来研究朝着真正具有物理意识的视频生成提供了具体的见解。
🔬 方法详解
问题定义:现有文本生成视频模型在生成视频时,往往忽略了基本的物理定律,例如能量守恒、刚体碰撞等,导致生成的内容不真实,甚至违反常识。现有的物理评估基准主要依赖于自动化的像素级指标,无法准确评估模型对复杂物理现象的理解,并且缺乏人工评估的参与。
核心思路:T2VPhysBench的核心思路是构建一个基于第一性原理的基准测试,通过人工评估的方式,系统地评估文本生成视频模型对一系列核心物理定律的遵守程度。该基准侧重于评估模型是否能够理解和模拟基本的物理现象,而不是仅仅关注生成视频的视觉效果。
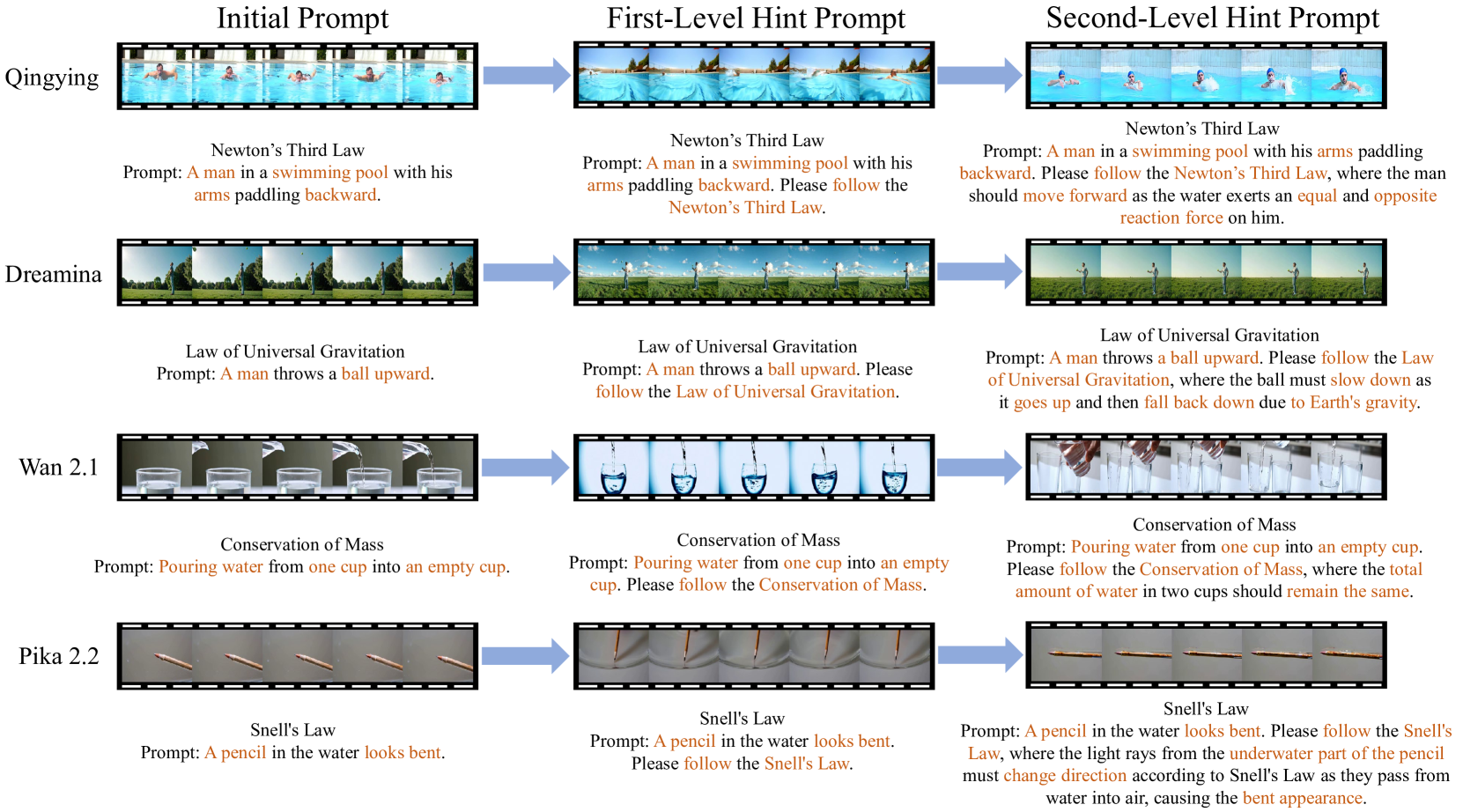
技术框架:T2VPhysBench包含以下几个主要组成部分: 1. 物理定律选择:选择了12个核心物理定律,包括牛顿力学、守恒定律和唯象效应等。 2. 提示设计:设计了一系列文本提示,用于引导模型生成包含特定物理现象的视频。 3. 人工评估协议:制定了严格的人工评估协议,用于评估模型生成的视频是否符合物理定律。 4. 实验研究:进行了三项有针对性的研究,包括总体合规性评估、提示-提示消融实验和反事实鲁棒性测试。
关键创新:T2VPhysBench的关键创新在于: 1. 第一性原理评估:从基本的物理定律出发,评估模型对物理现象的理解和模拟能力。 2. 人工评估:采用人工评估的方式,避免了自动化指标的局限性,能够更准确地评估模型的物理一致性。 3. 系统性评估:系统地评估了模型对一系列核心物理定律的遵守程度,提供了全面的评估结果。
关键设计:T2VPhysBench的关键设计包括: 1. 物理定律的选择:选择了12个具有代表性的物理定律,涵盖了力学、能量守恒等多个方面。 2. 提示的设计:设计了清晰、明确的文本提示,避免了歧义,能够有效地引导模型生成包含特定物理现象的视频。 3. 评估协议的设计:制定了详细的评估标准,确保评估结果的客观性和一致性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有文本生成视频模型在T2VPhysBench上的表现普遍较差,平均合规性得分低于0.60。即使提供详细的、特定于定律的提示,也无法显著改善模型的物理一致性。反事实鲁棒性测试表明,模型在被指示违反物理规则时,更容易生成不符合物理规律的视频。
🎯 应用场景
T2VPhysBench可用于评估和改进文本生成视频模型的物理一致性,提高生成视频的真实感和可信度。该基准可以促进开发更符合物理规律的视频生成算法,应用于虚拟现实、游戏开发、教育等领域,例如生成更真实的物理模拟动画,或创建更具沉浸感的虚拟环境。
📄 摘要(原文)
Text-to-video generative models have made significant strides in recent years, producing high-quality videos that excel in both aesthetic appeal and accurate instruction following, and have become central to digital art creation and user engagement online. Yet, despite these advancements, their ability to respect fundamental physical laws remains largely untested: many outputs still violate basic constraints such as rigid-body collisions, energy conservation, and gravitational dynamics, resulting in unrealistic or even misleading content. Existing physical-evaluation benchmarks typically rely on automatic, pixel-level metrics applied to simplistic, life-scenario prompts, and thus overlook both human judgment and first-principles physics. To fill this gap, we introduce \textbf{T2VPhysBench}, a first-principled benchmark that systematically evaluates whether state-of-the-art text-to-video systems, both open-source and commercial, obey twelve core physical laws including Newtonian mechanics, conservation principles, and phenomenological effects. Our benchmark employs a rigorous human evaluation protocol and includes three targeted studies: (1) an overall compliance assessment showing that all models score below 0.60 on average in each law category; (2) a prompt-hint ablation revealing that even detailed, law-specific hints fail to remedy physics violations; and (3) a counterfactual robustness test demonstrating that models often generate videos that explicitly break physical rules when so instructed. The results expose persistent limitations in current architectures and offer concrete insights for guiding future research toward truly physics-aware video generation.