COSMOS: Predictable and Cost-Effective Adaptation of LLMs
作者: Jiayu Wang, Aws Albarghouthi, Frederic Sala
分类: cs.LG, cs.AI
发布日期: 2025-04-30
💡 一句话要点
提出COSMOS以高效预测LLMs的适应性与成本
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 适应性预测 计算成本 轻量级模型 上下文学习 资源优化 机器学习
📋 核心要点
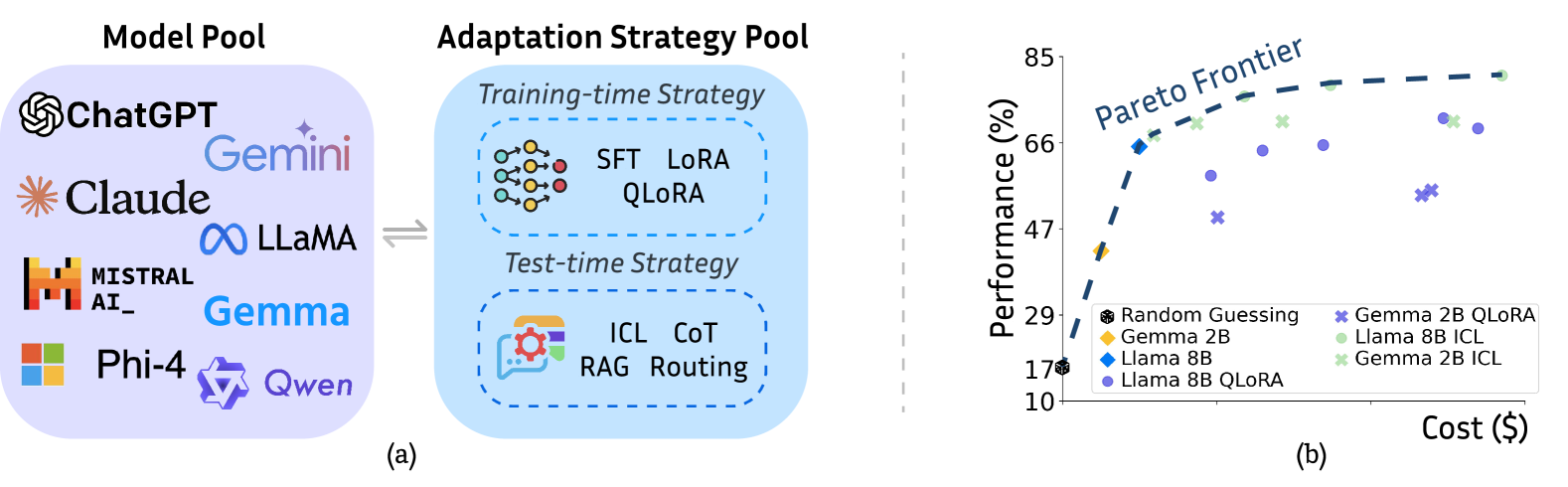
- 现有方法在资源限制下选择模型和适应策略时面临复杂性和高实验成本的挑战。
- COSMOS框架通过轻量级代理模型和低样本缩放法则,提供了一种高效的适应结果预测方法。
- COSMOS在多个基准测试中显示出高预测准确性,同时显著降低了计算成本,提升了部署效率。
📝 摘要(中文)
大型语言模型(LLMs)在众多任务中展现出卓越的性能,但在资源限制下,选择最优模型和适应策略的过程复杂且需大量实验。本文探讨了在不进行昂贵试验的情况下,是否能够准确预测性能和成本。我们提出了COSMOS,一个统一的预测框架,能够以最低成本高效估计适应结果。通过嵌入增强的轻量级代理模型预测微调性能,以及低样本缩放法则预测检索增强的上下文学习,COSMOS在八个基准测试中表现出高预测准确性,平均降低计算成本92.72%,在资源密集型场景中最高可达98.71%。
🔬 方法详解
问题定义:本文旨在解决在资源限制下,如何高效选择大型语言模型及其适应策略的问题。现有方法通常需要大量实验,导致高昂的计算成本和时间消耗。
核心思路:COSMOS框架通过建立轻量级代理模型和低样本缩放法则,能够在不进行昂贵试验的情况下,准确预测模型的适应性和成本,从而优化选择过程。
技术框架:COSMOS的整体架构包括两个主要模块:第一,嵌入增强的轻量级代理模型用于预测微调性能;第二,低样本缩放法则用于预测检索增强的上下文学习。
关键创新:COSMOS的核心创新在于其统一的预测框架,能够在不同的适应策略下提供准确的性能和成本预测,这与传统方法依赖大量实验的方式形成鲜明对比。
关键设计:在设计中,轻量级代理模型的参数设置经过精心调整,以确保其在预测微调性能时的准确性。同时,低样本缩放法则的应用使得在样本稀缺的情况下仍能有效预测性能。整体框架的损失函数和网络结构也经过优化,以提升预测效果。
🖼️ 关键图片
📊 实验亮点
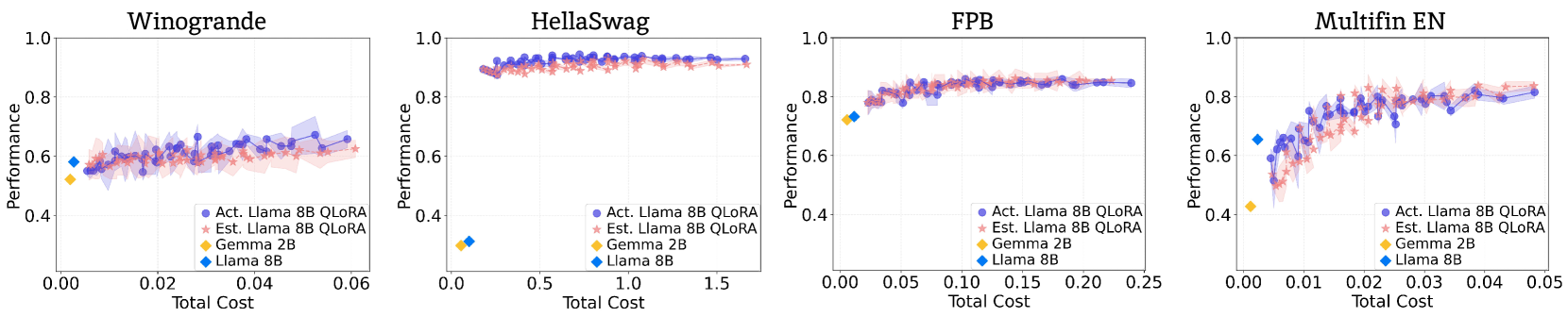
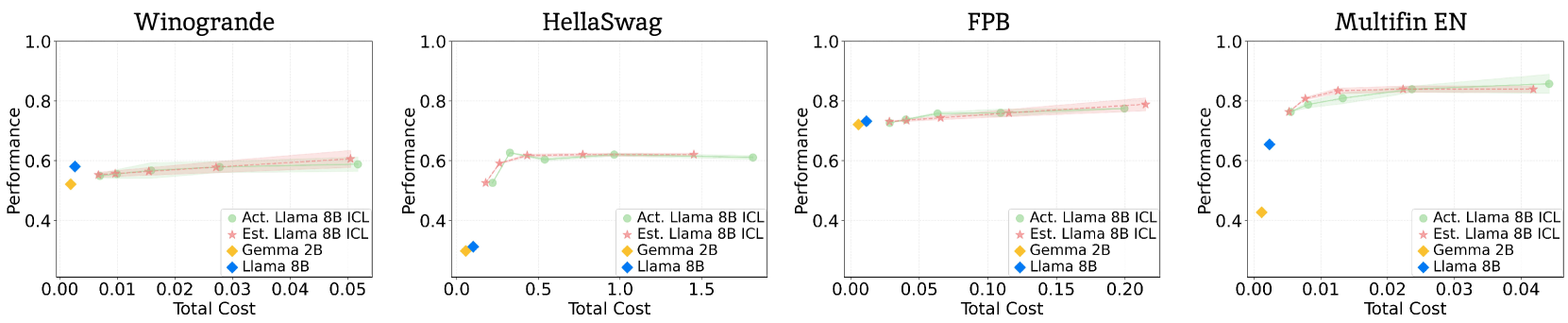
COSMOS在八个基准测试中的实验结果显示,其预测准确性显著提高,同时平均降低计算成本达92.72%,在资源密集型场景中最高可达98.71%。这些结果表明,COSMOS不仅在性能上保持了高标准,还在计算效率上实现了显著提升。
🎯 应用场景
COSMOS的研究成果在多个领域具有广泛的应用潜力,尤其是在需要快速部署和高效资源利用的场景中,如自然语言处理、对话系统和智能助手等。通过降低计算成本,COSMOS能够帮助企业和研究机构更高效地利用大型语言模型,提升其在实际应用中的价值和影响力。
📄 摘要(原文)
Large language models (LLMs) achieve remarkable performance across numerous tasks by using a diverse array of adaptation strategies. However, optimally selecting a model and adaptation strategy under resource constraints is challenging and often requires extensive experimentation. We investigate whether it is possible to accurately predict both performance and cost without expensive trials. We formalize the strategy selection problem for LLMs and introduce COSMOS, a unified prediction framework that efficiently estimates adaptation outcomes at minimal cost. We instantiate and study the capability of our framework via a pair of powerful predictors: embedding-augmented lightweight proxy models to predict fine-tuning performance, and low-sample scaling laws to forecast retrieval-augmented in-context learning. Extensive evaluation across eight representative benchmarks demonstrates that COSMOS achieves high prediction accuracy while reducing computational costs by 92.72% on average, and up to 98.71% in resource-intensive scenarios. Our results show that efficient prediction of adaptation outcomes is not only feasible but can substantially reduce the computational overhead of LLM deployment while maintaining performance standards.