OpenAVS: Training-Free Open-Vocabulary Audio Visual Segmentation with Foundational Models
作者: Shengkai Chen, Yifang Yin, Jinming Cao, Shili Xiang, Zhenguang Liu, Roger Zimmermann
分类: cs.LG, cs.MM
发布日期: 2025-04-30
💡 一句话要点
提出OpenAVS,利用多媒体基础模型实现免训练的开放词汇音视频分割
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频分割 开放词汇 多模态学习 基础模型 零样本学习
📋 核心要点
- 现有音视频分割方法主要集中在封闭集场景,缺乏对新场景的泛化能力。
- OpenAVS利用文本作为桥梁,通过多媒体基础模型实现音频和视觉模态的对齐,无需训练。
- 实验表明,OpenAVS在多个数据集上显著优于现有的无监督、零样本和少样本方法。
📝 摘要(中文)
本文提出OpenAVS,一种新颖的、基于语言的免训练方法,首次使用文本作为代理,有效对齐音频和视觉模态,用于开放词汇音视频分割(AVS)。OpenAVS配备多媒体基础模型,通过1)音频到文本的提示生成,2)LLM引导的提示翻译,以及3)文本到视觉的发声对象分割,直接推断掩码。OpenAVS旨在建立一个简单而灵活的架构,通过充分利用最合适的基础模型的能力,从而更有效地将知识转移到下游AVS任务。此外,我们提出了一个模型无关的框架OpenAVS-ST,它可以通过基于伪标签的自训练将OpenAVS与任何先进的监督AVS模型集成。这种方法通过有效利用大规模无标签数据来提高性能。在三个基准数据集上的综合实验表明了OpenAVS的优越性能。它显著超越了现有的无监督、零样本和少样本AVS方法,在具有挑战性的场景中,mIoU和F-score分别实现了约9.4%和10.9%的绝对性能提升。
🔬 方法详解
问题定义:现有的音视频分割方法主要集中在封闭集场景,即模型只能识别训练集中出现过的声音对象。这限制了它们在实际应用中的泛化能力,无法处理未见过的声音对象。此外,现有方法通常直接进行音频-视觉对齐和融合,缺乏对模态之间关系的深层理解。
核心思路:OpenAVS的核心思路是利用文本作为音频和视觉模态之间的桥梁。通过将音频信息转换为文本描述,再利用大型语言模型(LLM)对文本进行理解和扩展,最后将文本描述与视觉信息对齐,从而实现开放词汇的音视频分割。这种方法充分利用了预训练的多模态基础模型的能力,避免了从头开始训练模型的需要。
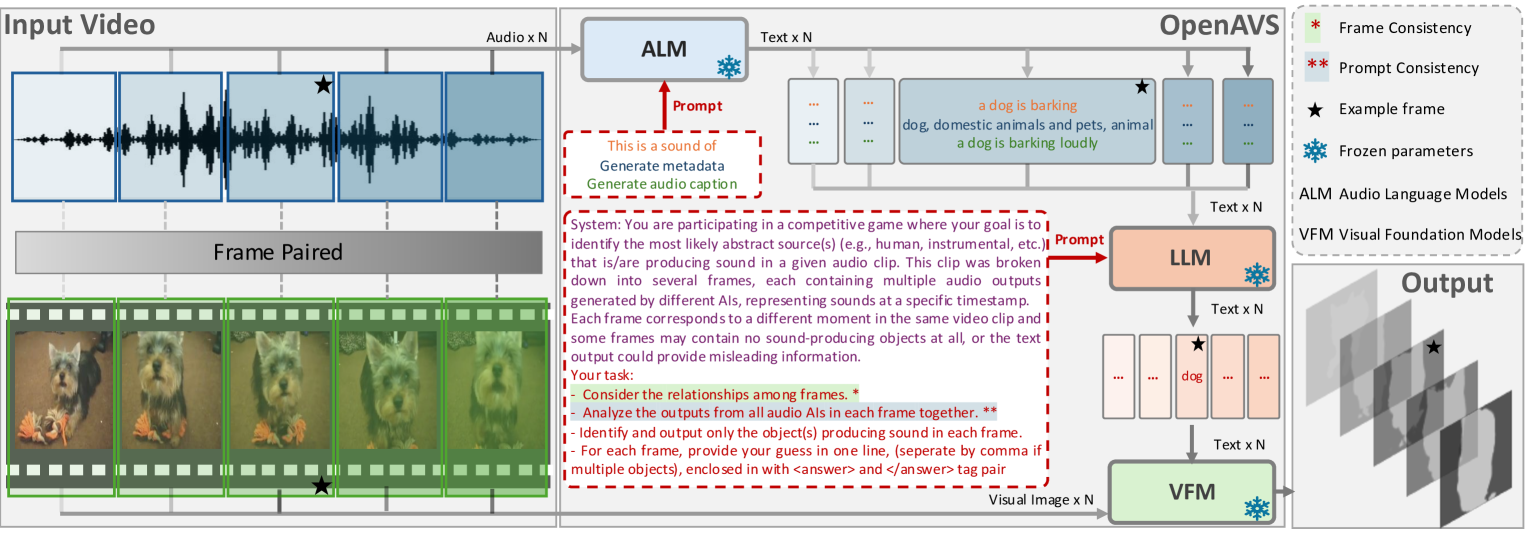
技术框架:OpenAVS的整体框架包含三个主要阶段:1) 音频到文本的提示生成:利用预训练的音频字幕模型将音频信号转换为文本描述。2) LLM引导的提示翻译:使用大型语言模型对生成的文本描述进行扩展和优化,生成更详细和准确的提示。3) 文本到视觉的发声对象分割:利用文本引导的图像分割模型,根据生成的提示在视频帧中分割出对应的发声对象。OpenAVS-ST则是在OpenAVS的基础上,利用伪标签进行自训练,从而进一步提升性能。
关键创新:OpenAVS的关键创新在于它首次将文本作为代理,实现了开放词汇的音视频分割。与现有方法相比,OpenAVS无需针对特定数据集进行训练,可以直接利用预训练的多模态基础模型,从而具有更强的泛化能力。此外,OpenAVS-ST框架可以方便地与现有的监督学习模型集成,从而进一步提升性能。
关键设计:OpenAVS的关键设计包括:选择合适的音频字幕模型、LLM和文本引导的图像分割模型。论文中没有明确说明具体的参数设置和损失函数,但强调了充分利用预训练模型的能力。OpenAVS-ST框架中,伪标签的生成和选择策略是影响自训练效果的关键因素,具体细节未知。
🖼️ 关键图片


📊 实验亮点
OpenAVS在三个基准数据集上取得了显著的性能提升,超越了现有的无监督、零样本和少样本AVS方法。在具有挑战性的场景中,mIoU和F-score分别实现了约9.4%和10.9%的绝对性能提升。这些结果表明,OpenAVS是一种有效的开放词汇音视频分割方法,具有很强的泛化能力。
🎯 应用场景
OpenAVS在视频编辑、智能监控、人机交互等领域具有广泛的应用前景。例如,可以用于自动识别视频中的发声对象,辅助视频剪辑和内容分析;在智能监控中,可以根据声音事件定位异常情况;在人机交互中,可以根据用户的语音指令控制视觉对象的行为。该研究为开发更智能、更灵活的音视频处理系统奠定了基础。
📄 摘要(原文)
Audio-visual segmentation aims to separate sounding objects from videos by predicting pixel-level masks based on audio signals. Existing methods primarily concentrate on closed-set scenarios and direct audio-visual alignment and fusion, which limits their capability to generalize to new, unseen situations. In this paper, we propose OpenAVS, a novel training-free language-based approach that, for the first time, effectively aligns audio and visual modalities using text as a proxy for open-vocabulary Audio-Visual Segmentation (AVS). Equipped with multimedia foundation models, OpenAVS directly infers masks through 1) audio-to-text prompt generation, 2) LLM-guided prompt translation, and 3) text-to-visual sounding object segmentation. The objective of OpenAVS is to establish a simple yet flexible architecture that relies on the most appropriate foundation models by fully leveraging their capabilities to enable more effective knowledge transfer to the downstream AVS task. Moreover, we present a model-agnostic framework OpenAVS-ST that enables the integration of OpenAVS with any advanced supervised AVS model via pseudo-label based self-training. This approach enhances performance by effectively utilizing large-scale unlabeled data when available. Comprehensive experiments on three benchmark datasets demonstrate the superior performance of OpenAVS. It surpasses existing unsupervised, zero-shot, and few-shot AVS methods by a significant margin, achieving absolute performance gains of approximately 9.4% and 10.9% in mIoU and F-score, respectively, in challenging scenarios.