Recursive KL Divergence Optimization: A Dynamic Framework for Representation Learning
作者: Anthony D Martin
分类: cs.LG, cs.AI, cs.CV, cs.IT, cs.NE
发布日期: 2025-04-30
💡 一句话要点
提出递归KL散度优化框架RKDO,提升表征学习效率与稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 表征学习 对比学习 KL散度 递归优化 动态邻域
📋 核心要点
- 现有表征学习方法忽略了学习过程中固有的递归结构,导致效率和稳定性不足。
- RKDO将表征学习视为数据邻域间KL散度的动态演变,捕捉对比聚类等方法。
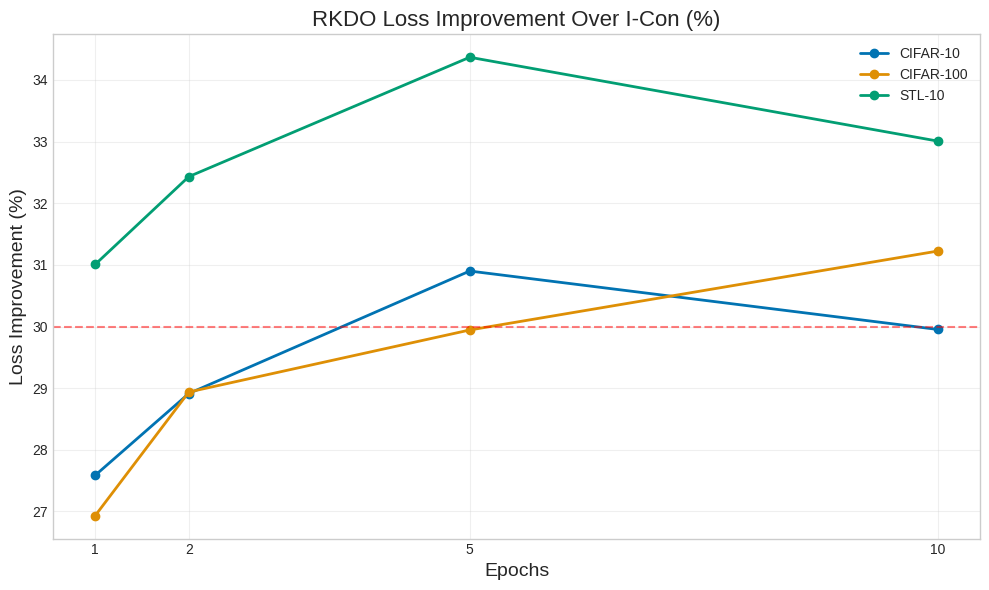
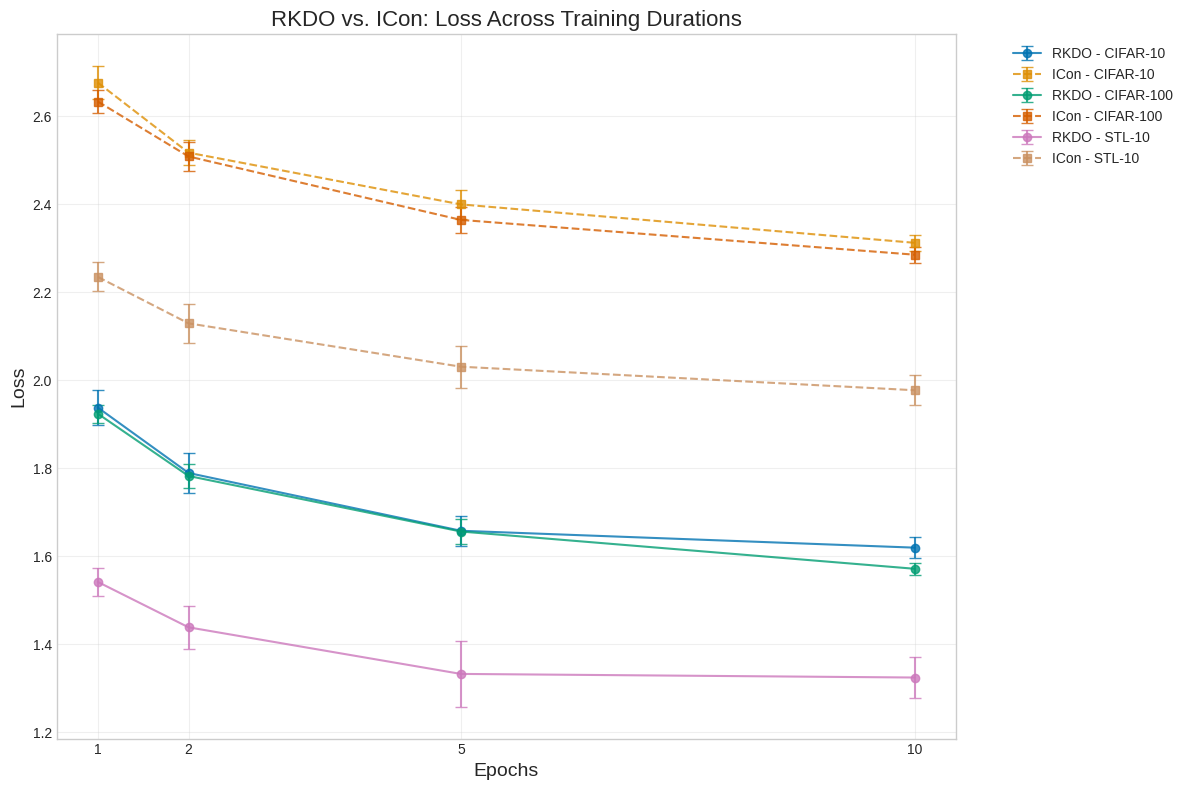
- 实验表明,RKDO能显著降低损失值并减少计算资源需求,提升表征学习效率。
📝 摘要(中文)
本文提出了一种现代表征学习目标函数的泛化方法,将其重新定义为局部条件分布上的递归散度对齐过程。虽然诸如信息对比学习(I-Con)等框架通过固定邻域条件分布之间的KL散度统一了多种学习范式,但我们认为这种观点低估了学习过程中固有的关键递归结构。我们引入了递归KL散度优化(RKDO),这是一个动态形式体系,其中表征学习被构建为数据邻域间KL散度的演变。该公式将对比聚类和降维方法捕捉为静态切片,同时为模型稳定性和局部自适应提供了一条新途径。实验表明,RKDO提供了双重效率优势:在三个不同的数据集上,损失值比静态方法降低约30%,并且实现可比结果所需的计算资源减少60%到80%。这表明RKDO的递归更新机制为表征学习提供了一个从根本上更有效的优化环境,对资源受限的应用具有重大意义。
🔬 方法详解
问题定义:现有表征学习方法,如对比学习,通常基于静态的邻域关系和固定的损失函数进行优化。这些方法忽略了表征学习过程本身是一个动态演化的过程,缺乏对局部信息和全局信息的有效整合,导致学习效率低下,模型泛化能力受限。尤其是在资源受限的场景下,如何高效地学习高质量的表征是一个关键问题。
核心思路:RKDO的核心思路是将表征学习过程建模为一个递归的KL散度优化过程。通过动态地调整数据邻域间的关系,并递归地优化KL散度,使得模型能够更好地捕捉数据的局部结构和全局一致性。这种递归的优化方式能够更有效地利用数据中的信息,从而提高学习效率和模型性能。
技术框架:RKDO框架主要包含以下几个关键模块:1) 邻域构建模块:用于构建数据点的局部邻域,可以采用KNN等方法。2) 条件分布估计模块:用于估计每个数据点在其邻域内的条件概率分布。3) KL散度计算模块:用于计算不同数据点之间的KL散度,衡量它们之间的相似度。4) 递归优化模块:通过递归地更新邻域关系和条件分布,优化整体的KL散度,从而学习到更好的数据表征。整个流程可以看作是在不断地调整数据空间中的“引力”和“斥力”,使得相似的数据点更加靠近,不相似的数据点更加远离。
关键创新:RKDO最重要的创新在于其递归的优化机制。与传统的静态方法不同,RKDO能够动态地调整邻域关系和条件分布,从而更好地适应数据的复杂结构。这种递归的优化方式能够更有效地利用数据中的信息,从而提高学习效率和模型性能。此外,RKDO将对比学习、聚类和降维等方法统一到一个框架下,提供了一个更广阔的视角来理解表征学习。
关键设计:RKDO的关键设计包括:1) 邻域大小的选择:邻域大小的选择会影响模型的性能,需要根据具体的数据集进行调整。2) KL散度的计算方式:可以选择不同的KL散度计算方式,如对称KL散度等。3) 递归的停止条件:需要设置合适的停止条件,以避免过度优化。4) 损失函数的设计:损失函数的设计需要考虑到模型的稳定性和收敛速度,可以采用正则化等技术来提高模型的泛化能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RKDO在三个不同的数据集上,损失值比静态方法降低约30%,并且实现可比结果所需的计算资源减少60%到80%。这些结果表明,RKDO的递归更新机制能够显著提高表征学习的效率和性能,为资源受限的应用提供了新的解决方案。
🎯 应用场景
RKDO具有广泛的应用前景,例如图像识别、自然语言处理、推荐系统等。尤其是在资源受限的场景下,RKDO能够以更低的计算成本学习到高质量的表征,具有重要的实际价值。未来,RKDO可以应用于移动设备、嵌入式系统等资源受限的平台,为这些平台提供更强大的AI能力。
📄 摘要(原文)
We propose a generalization of modern representation learning objectives by reframing them as recursive divergence alignment processes over localized conditional distributions While recent frameworks like Information Contrastive Learning I-Con unify multiple learning paradigms through KL divergence between fixed neighborhood conditionals we argue this view underplays a crucial recursive structure inherent in the learning process. We introduce Recursive KL Divergence Optimization RKDO a dynamic formalism where representation learning is framed as the evolution of KL divergences across data neighborhoods. This formulation captures contrastive clustering and dimensionality reduction methods as static slices while offering a new path to model stability and local adaptation. Our experiments demonstrate that RKDO offers dual efficiency advantages approximately 30 percent lower loss values compared to static approaches across three different datasets and 60 to 80 percent reduction in computational resources needed to achieve comparable results. This suggests that RKDOs recursive updating mechanism provides a fundamentally more efficient optimization landscape for representation learning with significant implications for resource constrained applications.