Synergy-CLIP: Extending CLIP with Multi-modal Integration for Robust Representation Learning
作者: Sangyeon Cho, Jangyeong Jeon, Mingi Kim, Junyeong Kim
分类: cs.LG
发布日期: 2025-04-30
备注: Multi-modal, Multi-modal Representation Learning, Missing Modality, Missing Modality Reconstruction, Speech and Multi-modality, Vision and Language
💡 一句话要点
Synergy-CLIP:通过多模态融合扩展CLIP,实现鲁棒的表征学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多模态学习 CLIP 对比学习 跨模态融合 表征学习 零样本分类 音频视觉文本 VGG-sound+
📋 核心要点
- 现有方法主要关注双模态交互,无法充分利用多模态数据的丰富性,且缺乏在同等规模环境下整合多模态的研究。
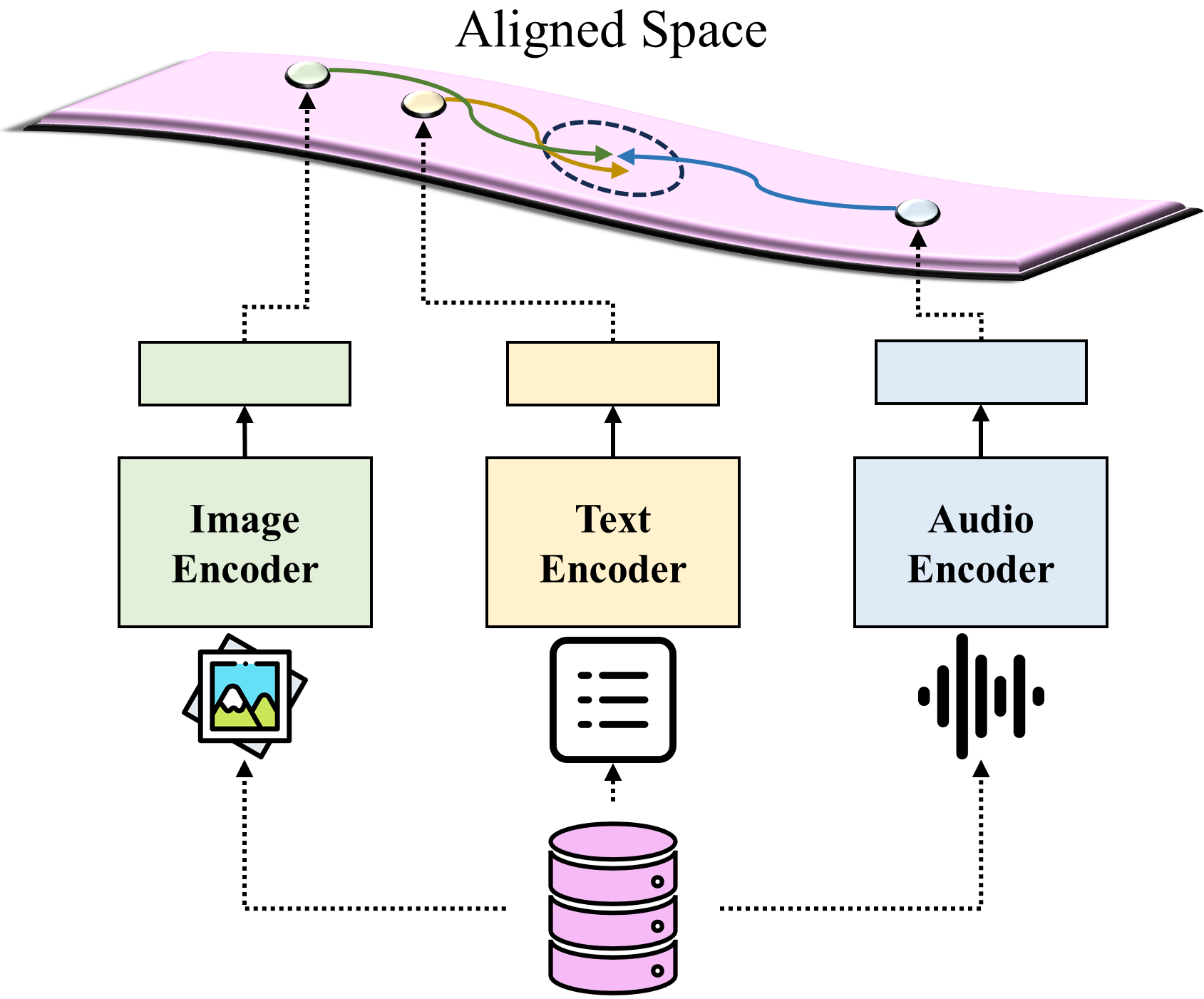
- Synergy-CLIP通过扩展CLIP架构,整合视觉、文本和音频三种模态,同等地对齐和捕获它们的潜在信息。
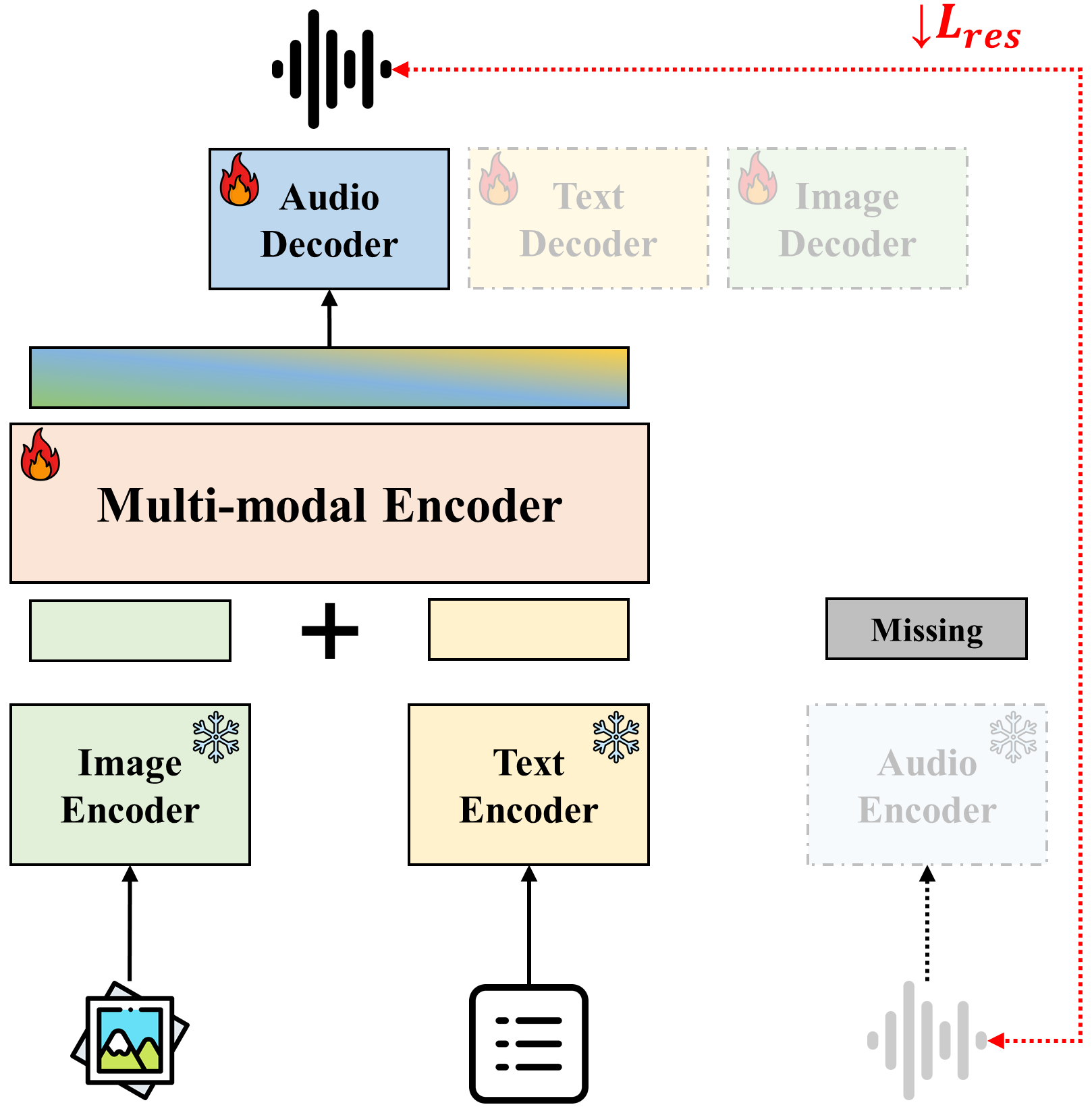
- 通过VGG-sound+数据集和缺失模态重建任务,验证了Synergy-CLIP在零样本分类等下游任务上的优越性能。
📝 摘要(中文)
多模态表征学习已成为人工智能的关键领域,它能够整合视觉、文本和音频等多种模态来解决复杂问题。然而,现有方法主要关注双模态交互(如图像-文本对),限制了它们充分利用多模态数据的丰富性。此外,由于构建大规模平衡数据集的挑战,在同等规模环境中整合模态的研究仍然不足。本研究提出了Synergy-CLIP,一种新颖的框架,它扩展了对比语言-图像预训练(CLIP)架构,通过整合视觉、文本和音频模态来增强多模态表征学习。与现有专注于将单个模态适配到vanilla-CLIP的方法不同,Synergy-CLIP同等地对齐和捕获三种模态的潜在信息。为了解决构建大规模多模态数据集的高成本问题,我们引入了VGG-sound+,一个旨在提供视觉、文本和音频数据的同等规模表征的三模态数据集。Synergy-CLIP在各种下游任务(包括零样本分类)上进行了验证,并优于现有基线。此外,我们引入了一个缺失模态重建任务,展示了Synergy-CLIP在实际应用场景中提取模态之间协同作用的能力。这些贡献为推进多模态表征学习和探索新的研究方向提供了坚实的基础。
🔬 方法详解
问题定义:现有方法在多模态表征学习中主要关注图像-文本等双模态交互,忽略了音频等其他模态,并且难以构建大规模平衡的多模态数据集,导致模型无法充分学习不同模态之间的协同效应。
核心思路:Synergy-CLIP的核心思路是扩展CLIP模型,使其能够同时处理视觉、文本和音频三种模态,并设计相应的训练策略,使得模型能够学习到三种模态之间更深层次的关联和互补信息。通过构建一个三模态数据集VGG-sound+,保证了各模态数据的平衡性,从而避免了模型对某些模态的偏好。
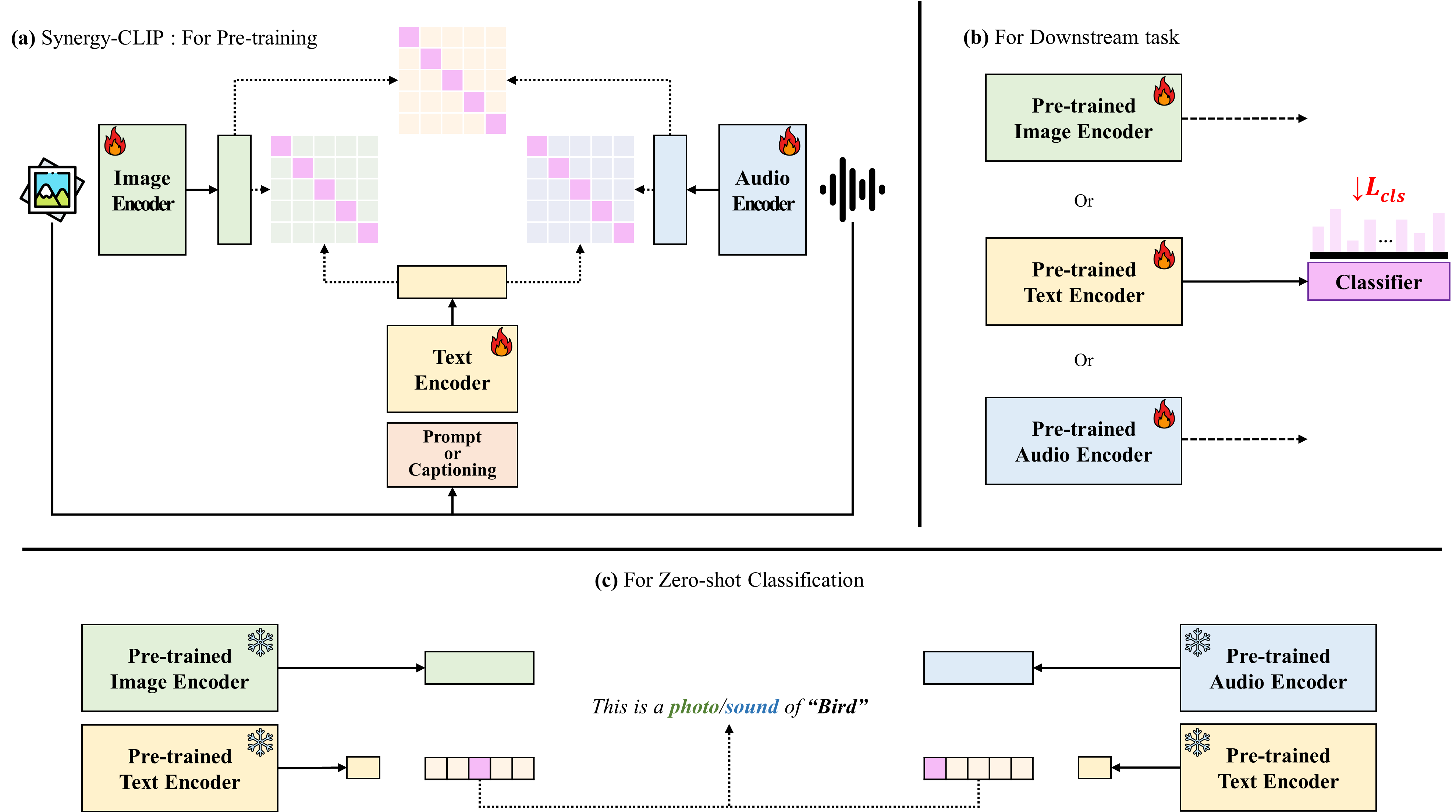
技术框架:Synergy-CLIP的整体架构基于CLIP,包含三个编码器分别处理视觉、文本和音频数据。这三个编码器的输出被映射到一个共享的潜在空间,然后通过对比学习的方式进行训练。具体来说,模型的目标是最大化同一场景下视觉、文本和音频表征之间的相似度,同时最小化不同场景下表征之间的相似度。
关键创新:Synergy-CLIP的关键创新在于它将CLIP扩展到了三模态,并且设计了相应的训练策略,使得模型能够学习到三种模态之间的协同效应。此外,VGG-sound+数据集的构建也为三模态表征学习提供了数据基础。与现有方法相比,Synergy-CLIP能够更好地利用多模态数据,从而获得更鲁棒的表征。
关键设计:在具体实现上,视觉编码器可以使用ResNet等常用的图像特征提取网络,文本编码器可以使用Transformer等语言模型,音频编码器可以使用VGGish等音频特征提取网络。损失函数采用对比学习损失,例如InfoNCE。为了平衡不同模态的贡献,可以对不同模态的损失进行加权。VGG-sound+数据集包含等量的视觉、文本和音频数据,并且对数据进行了清洗和标注,保证了数据的质量。
🖼️ 关键图片
📊 实验亮点
Synergy-CLIP在零样本分类等下游任务上取得了显著的性能提升,超越了现有的CLIP模型和其他基线方法。通过引入缺失模态重建任务,验证了Synergy-CLIP能够有效地提取不同模态之间的协同效应。VGG-sound+数据集的发布为多模态研究提供了宝贵的数据资源。
🎯 应用场景
Synergy-CLIP在多媒体内容理解、智能助手、跨模态检索等领域具有广泛的应用前景。例如,可以用于根据一段视频和文字描述生成相应的音频,或者根据一段音频和文字描述生成相应的视频。此外,还可以用于提高语音识别、图像识别等任务的准确率,通过结合多种模态的信息来提高模型的鲁棒性。
📄 摘要(原文)
Multi-modal representation learning has become a pivotal area in artificial intelligence, enabling the integration of diverse modalities such as vision, text, and audio to solve complex problems. However, existing approaches predominantly focus on bimodal interactions, such as image-text pairs, which limits their ability to fully exploit the richness of multi-modal data. Furthermore, the integration of modalities in equal-scale environments remains underexplored due to the challenges of constructing large-scale, balanced datasets. In this study, we propose Synergy-CLIP, a novel framework that extends the contrastive language-image pre-training (CLIP) architecture to enhance multi-modal representation learning by integrating visual, textual, and audio modalities. Unlike existing methods that focus on adapting individual modalities to vanilla-CLIP, Synergy-CLIP aligns and captures latent information across three modalities equally. To address the high cost of constructing large-scale multi-modal datasets, we introduce VGG-sound+, a triple-modal dataset designed to provide equal-scale representation of visual, textual, and audio data. Synergy-CLIP is validated on various downstream tasks, including zero-shot classification, where it outperforms existing baselines. Additionally, we introduce a missing modality reconstruction task, demonstrating Synergy-CLIP's ability to extract synergy among modalities in realistic application scenarios. These contributions provide a robust foundation for advancing multi-modal representation learning and exploring new research directions.