Graph Synthetic Out-of-Distribution Exposure with Large Language Models
作者: Haoyan Xu, Zhengtao Yao, Ziyi Wang, Zhan Cheng, Xiyang Hu, Mengyuan Li, Yue Zhao
分类: cs.LG
发布日期: 2025-04-29 (更新: 2025-05-17)
💡 一句话要点
提出GOE-LLM框架,利用大语言模型进行图结构OOD检测,无需真实OOD数据。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图神经网络 分布外检测 大语言模型 OOD暴露 文本属性图
📋 核心要点
- 现有图OOD检测方法依赖真实OOD数据,获取成本高昂且不切实际,限制了模型泛化能力。
- GOE-LLM利用LLM在文本属性图上生成伪OOD节点,无需真实OOD数据即可实现OOD暴露。
- 实验表明,GOE-LLM在OOD检测AUROC上提升高达23.5%,性能媲美使用真实OOD标签的方法。
📝 摘要(中文)
图结构中的分布外(OOD)检测对于确保模型在开放世界和安全敏感应用中的鲁棒性至关重要。现有的图OOD检测方法通常仅在分布内(ID)数据上训练ID分类器,然后应用事后评分来检测OOD实例。虽然OOD暴露——在训练期间添加辅助OOD样本——可以改善检测,但当前基于图的方法通常假设可以访问真实的OOD节点,这通常是不切实际或代价高昂的。本文提出了GOE-LLM,一个利用大型语言模型(LLM)在文本属性图上实现OOD暴露的框架,无需使用任何真实的OOD节点。GOE-LLM引入了两个流程:(1)使用零样本LLM注释从最初未标记的图中识别伪OOD节点,以及(2)通过LLM提示的文本生成来生成语义信息丰富的合成OOD节点。然后,这些伪OOD节点用于正则化ID分类器训练并增强OOD检测意识。在多个基准上的实验结果表明,GOE-LLM显著优于没有OOD暴露的现有方法,在OOD检测的AUROC方面提高了高达23.5%,并且达到了与依赖真实OOD标签进行暴露的方法相当的性能。
🔬 方法详解
问题定义:论文旨在解决图结构数据上的分布外(OOD)检测问题。现有方法依赖于真实的OOD数据进行训练,但在许多实际场景中,获取这些数据非常困难或成本很高。这限制了模型在开放环境下的泛化能力和鲁棒性。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大语义理解和生成能力,在没有真实OOD数据的情况下,合成具有语义信息的伪OOD节点。这些伪OOD节点可以用于OOD暴露,从而提升模型对OOD数据的识别能力。
技术框架:GOE-LLM框架包含两个主要流程:1) 伪OOD节点识别:利用零样本LLM注释,从初始未标记的图中识别出潜在的伪OOD节点。具体来说,使用LLM对图中的节点进行分类或属性标注,将与ID数据语义差异较大的节点标记为伪OOD节点。2) 合成OOD节点生成:通过LLM提示的文本生成,为每个伪OOD节点生成语义信息丰富的文本描述。这些生成的文本描述作为合成的OOD节点,用于后续的OOD暴露训练。
关键创新:该论文的关键创新在于利用LLM的强大能力,实现了在图结构数据上进行OOD暴露,而无需依赖真实的OOD数据。这极大地降低了OOD检测的成本,并提高了模型在实际应用中的可行性。
关键设计:在伪OOD节点识别阶段,需要设计合适的LLM提示,以引导LLM准确识别出与ID数据语义差异较大的节点。在合成OOD节点生成阶段,需要设计合适的LLM提示,以生成具有语义信息且与ID数据差异明显的文本描述。此外,还需要设计合适的损失函数,将合成的OOD节点纳入ID分类器的训练过程中,以增强模型对OOD数据的识别能力。具体的损失函数和网络结构细节在论文中应该有更详细的描述(未知)。
🖼️ 关键图片


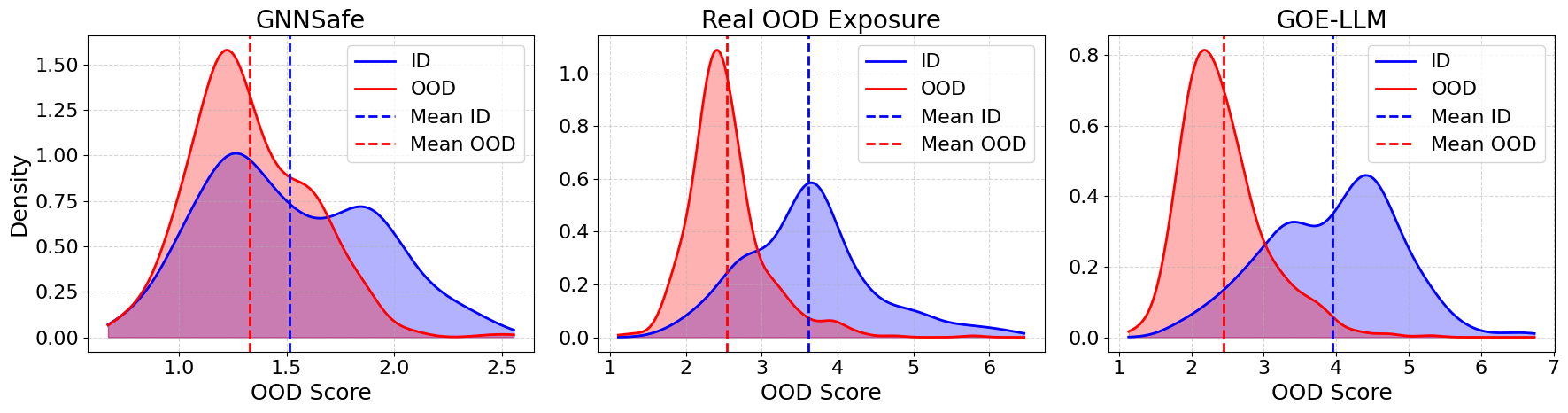
📊 实验亮点
GOE-LLM在多个基准数据集上取得了显著的性能提升,在OOD检测的AUROC指标上,相比于没有OOD暴露的现有方法,最高提升了23.5%。更重要的是,GOE-LLM的性能可以与那些依赖真实OOD标签进行暴露的方法相媲美,这充分证明了该方法在没有真实OOD数据的情况下,也能有效提升OOD检测性能。
🎯 应用场景
该研究成果可广泛应用于安全敏感的图数据分析场景,例如社交网络异常检测、金融欺诈识别、生物网络异常基因检测等。通过提高模型对未知异常数据的识别能力,可以有效降低风险,保障系统安全,具有重要的实际应用价值和潜在的社会影响。
📄 摘要(原文)
Out-of-distribution (OOD) detection in graphs is critical for ensuring model robustness in open-world and safety-sensitive applications. Existing graph OOD detection approaches typically train an in-distribution (ID) classifier on ID data alone, then apply post-hoc scoring to detect OOD instances. While OOD exposure - adding auxiliary OOD samples during training - can improve detection, current graph-based methods often assume access to real OOD nodes, which is often impractical or costly. In this paper, we present GOE-LLM, a framework that leverages Large Language Models (LLMs) to achieve OOD exposure on text-attributed graphs without using any real OOD nodes. GOE-LLM introduces two pipelines: (1) identifying pseudo-OOD nodes from the initially unlabeled graph using zero-shot LLM annotations, and (2) generating semantically informative synthetic OOD nodes via LLM-prompted text generation. These pseudo-OOD nodes are then used to regularize ID classifier training and enhance OOD detection awareness. Empirical results on multiple benchmarks show that GOE-LLM substantially outperforms state-of-the-art methods without OOD exposure, achieving up to a 23.5% improvement in AUROC for OOD detection, and attains performance on par with those relying on real OOD labels for exposure.