Representation Learning Preserving Ignorability and Covariate Matching for Treatment Effects
作者: Praharsh Nanavati, Ranjitha Prasad, Karthikeyan Shanmugam
分类: cs.LG, stat.ME
发布日期: 2025-04-29
💡 一句话要点
提出一种新的表征学习方法,同时解决因果效应估计中的混淆偏差和协变量失配问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 因果推断 表征学习 协变量匹配 隐藏混淆 治疗效果估计
📋 核心要点
- 从观察数据估计因果效应面临隐藏混淆和协变量失配两大挑战,现有方法通常仅解决其一。
- 论文提出一种新的神经架构,学习同时满足有效调整和协变量匹配约束的预处理协变量表征。
- 实验结果表明,该方法在多个因果基准数据集上,显著优于现有基线方法,降低了ATE和PEHE误差。
📝 摘要(中文)
由于(a)隐藏的混淆因素和(b)协变量失配(控制组和治疗组不具有相同的分布),从观察数据中估计治疗效果具有挑战性。现有的工作主要集中于解决其中一个问题。传统技术需要因果图等详细知识来解决前者。对于后者,通常使用协变量匹配和重要性加权方法。最近,在结合可测试的独立性与部分辅助信息来解决隐藏混淆方面取得了一些进展。目前缺乏一个通用的框架来同时解决隐藏混淆和选择偏差。我们提出了一种神经架构,旨在学习预处理协变量的表征,该表征是一个有效的调整,并且满足协变量匹配约束。我们结合了两种不同的神经架构:一种基于跨域梯度匹配,该域是通过对假设因果辅助信息的锚变量进行子抽样创建的;另一种是协变量匹配转换。我们证明了近似不变的表征产生近似有效的调整集,这将能够围绕真实因果效应产生一个区间。与通常的敏感性分析(其中未知干扰参数是变化的)相比,我们有一个可测试的近似,可以产生效应估计的界限。在包括IHDP、Jobs、Cattaneo和一个基于图像的Crowd Management数据集在内的因果基准上,我们的方法在ATE和PEHE误差方面优于各种基线。
🔬 方法详解
问题定义:论文旨在解决从观察数据中估计治疗效果时,由于隐藏的混淆因素和协变量失配导致的偏差问题。现有方法要么需要详细的因果图知识来处理混淆,要么侧重于协变量匹配,缺乏一个统一的框架同时解决这两个问题。
核心思路:论文的核心思路是学习一个预处理协变量的表征,该表征既能作为有效的调整集,消除混淆偏差,又能满足协变量匹配约束,使得治疗组和控制组的分布更加相似。通过学习这样的表征,可以更准确地估计治疗效果。
技术框架:整体框架包含两个主要的神经架构模块。第一个模块基于跨域梯度匹配,利用锚变量的子抽样创建多个域,并学习在这些域上梯度相似的表征。第二个模块是一个协变量匹配转换,进一步调整表征,使其满足协变量匹配约束。这两个模块串联在一起,共同学习最终的表征。
关键创新:论文的关键创新在于将因果推断中的有效调整集概念与协变量匹配方法相结合,通过学习表征的方式,同时解决隐藏混淆和协变量失配问题。此外,论文还提出了一个可测试的近似方法,用于估计因果效应的界限,避免了传统敏感性分析中对未知干扰参数的依赖。
关键设计:论文使用了梯度匹配损失函数来学习在不同域上梯度相似的表征,这有助于消除混淆偏差。同时,使用了协变量匹配损失函数来约束表征,使得治疗组和控制组的分布更加相似。具体的网络结构和参数设置需要根据具体的数据集进行调整,但整体框架保持不变。
🖼️ 关键图片

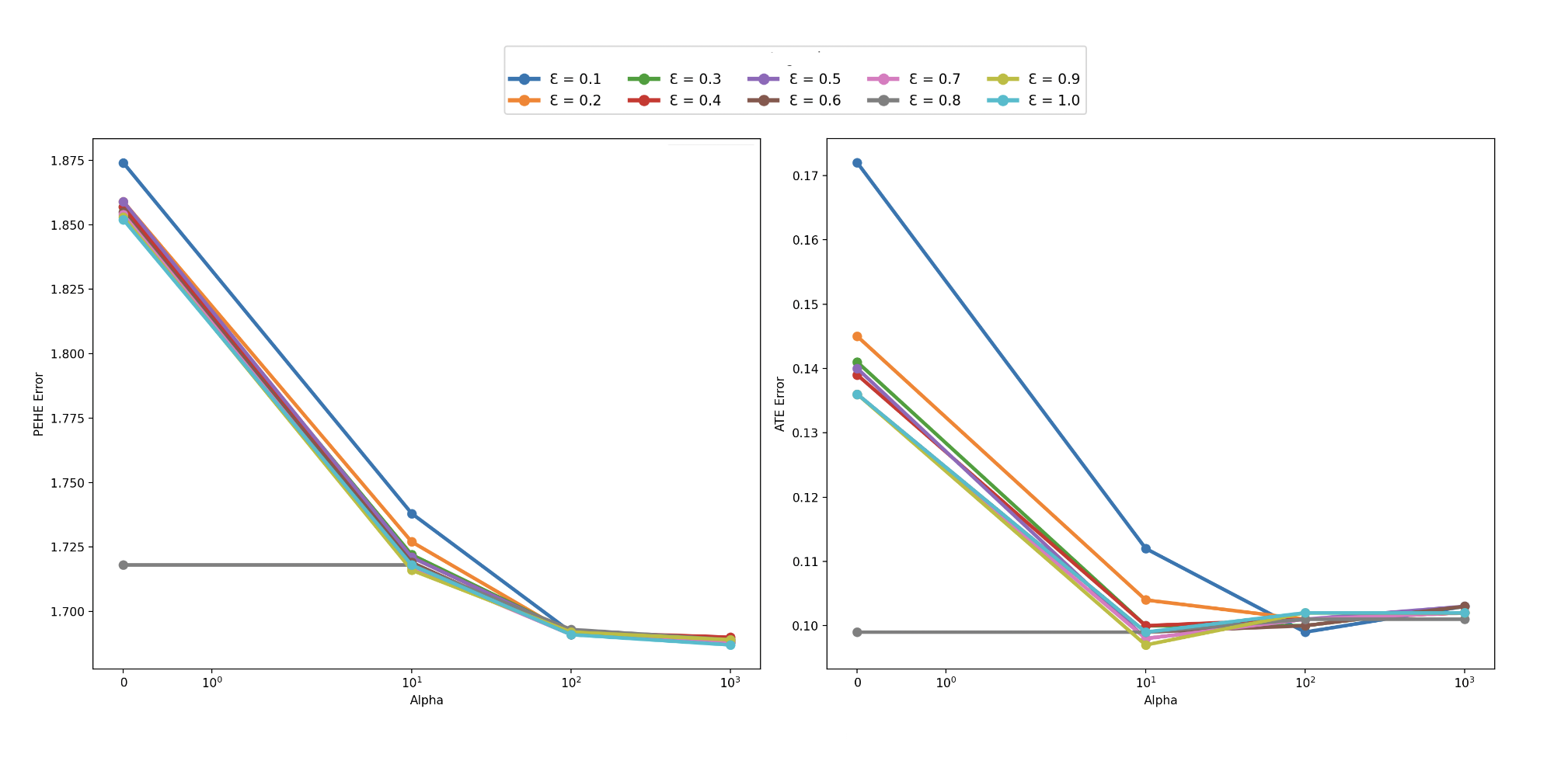
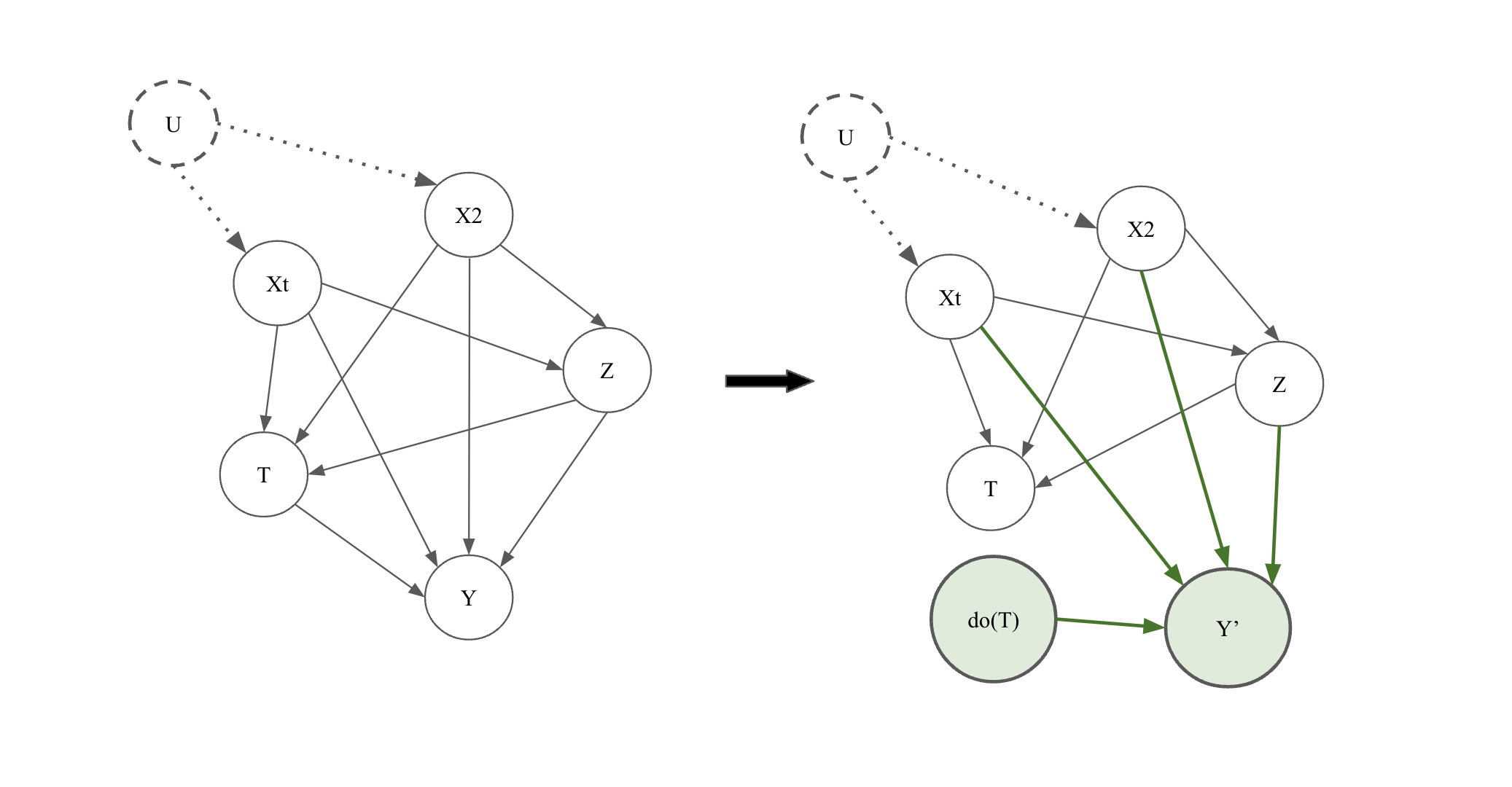
📊 实验亮点
该方法在IHDP、Jobs、Cattaneo和Crowd Management等多个因果基准数据集上进行了评估,实验结果表明,该方法在ATE(平均治疗效应)和PEHE(个体治疗效果异质性)误差方面均优于现有的基线方法,证明了其有效性。
🎯 应用场景
该研究成果可广泛应用于医疗健康、市场营销、公共政策等领域,在这些领域中,从观察数据中估计干预措施(如药物、广告、政策)的因果效应至关重要。例如,可以用于评估新药的疗效,优化营销策略,或评估政策的影响。
📄 摘要(原文)
Estimating treatment effects from observational data is challenging due to two main reasons: (a) hidden confounding, and (b) covariate mismatch (control and treatment groups not having identical distributions). Long lines of works exist that address only either of these issues. To address the former, conventional techniques that require detailed knowledge in the form of causal graphs have been proposed. For the latter, covariate matching and importance weighting methods have been used. Recently, there has been progress in combining testable independencies with partial side information for tackling hidden confounding. A common framework to address both hidden confounding and selection bias is missing. We propose neural architectures that aim to learn a representation of pre-treatment covariates that is a valid adjustment and also satisfies covariate matching constraints. We combine two different neural architectures: one based on gradient matching across domains created by subsampling a suitable anchor variable that assumes causal side information, followed by the other, a covariate matching transformation. We prove that approximately invariant representations yield approximate valid adjustment sets which would enable an interval around the true causal effect. In contrast to usual sensitivity analysis, where an unknown nuisance parameter is varied, we have a testable approximation yielding a bound on the effect estimate. We also outperform various baselines with respect to ATE and PEHE errors on causal benchmarks that include IHDP, Jobs, Cattaneo, and an image-based Crowd Management dataset.