GaLore 2: Large-Scale LLM Pre-Training by Gradient Low-Rank Projection
作者: DiJia Su, Andrew Gu, Jane Xu, Yuandong Tian, Jiawei Zhao
分类: cs.LG, cs.AI
发布日期: 2025-04-29
💡 一句话要点
GaLore 2:通过梯度低秩投影实现大规模LLM预训练,解决内存瓶颈。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 预训练 低秩投影 梯度压缩 内存优化
📋 核心要点
- 现有LLM训练面临内存瓶颈,限制了模型规模和训练数据量。
- GaLore 2通过梯度低秩投影,在不损失性能的前提下显著降低内存占用。
- GaLore 2成功预训练了Llama 7B模型,使用了高达5000亿的tokens,验证了其可扩展性。
📝 摘要(中文)
大型语言模型(LLMs)彻底改变了自然语言理解和生成,但在训练过程中面临着显著的内存瓶颈。GaLore(梯度低秩投影)通过利用权重梯度固有的低秩结构来解决这个问题,从而在不牺牲性能的情况下实现显著的内存节省。最近的研究进一步从各个方面扩展了GaLore,包括低比特量化和高阶张量结构。然而,GaLore仍然存在一些挑战,例如用于子空间更新的SVD的计算开销以及与最先进的训练并行化策略(例如,FSDP)的集成。在本文中,我们提出了GaLore 2,这是一个高效且可扩展的GaLore框架,它解决了这些挑战并结合了最新的进展。此外,我们通过使用高达5000亿个训练token从头开始预训练Llama 7B来展示GaLore 2的可扩展性,突出了其对实际LLM预训练场景的潜在影响。
🔬 方法详解
问题定义:大规模语言模型(LLM)的训练受到内存瓶颈的限制,尤其是在梯度计算和存储方面。传统的训练方法需要存储所有参数的梯度,这对于大型模型来说是不可行的。现有方法,如原始的GaLore,虽然通过低秩分解减少了内存占用,但在计算SVD进行子空间更新时引入了额外的计算开销,并且与先进的并行训练策略(如FSDP)的集成仍然存在挑战。
核心思路:GaLore 2的核心思路是利用权重梯度矩阵的低秩特性,通过低秩投影来近似梯度更新,从而显著减少需要存储和计算的参数量。通过更高效的算法和与FSDP等并行策略的集成,GaLore 2旨在降低计算开销,并提高训练效率和可扩展性。
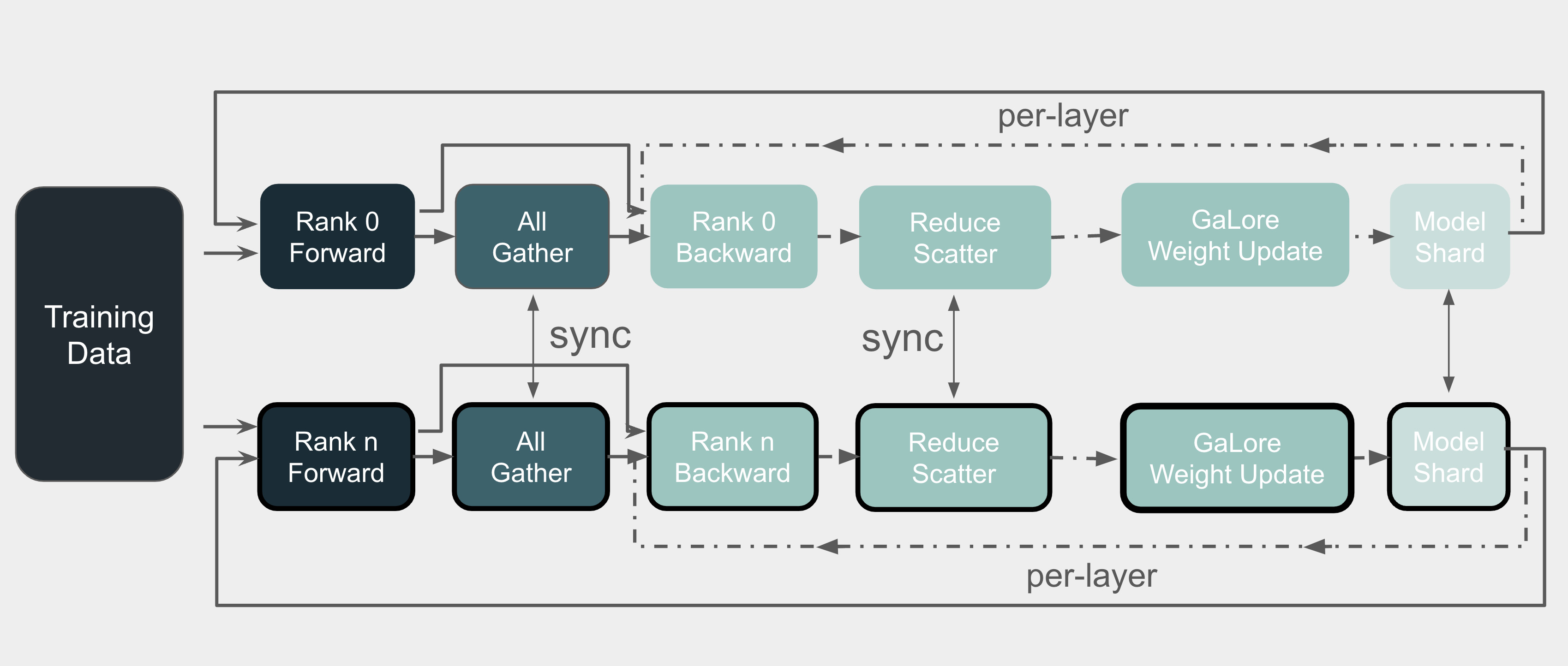
技术框架:GaLore 2框架主要包含以下几个阶段:1) 前向传播:计算模型输出和损失。2) 反向传播:计算梯度。3) 梯度低秩投影:使用低秩矩阵近似梯度,减少内存占用。4) 参数更新:使用近似梯度更新模型参数。5) 子空间更新:定期更新低秩子空间,以适应训练过程中的梯度变化。该框架可以与FSDP等并行训练策略集成,以进一步提高训练效率。
关键创新:GaLore 2的关键创新在于其高效的低秩投影算法和与先进并行训练策略的无缝集成。它可能采用更高效的SVD近似算法,或者避免完全依赖SVD,从而降低计算开销。此外,GaLore 2的设计使其能够与FSDP等策略协同工作,从而实现更大规模的模型训练。
关键设计:具体的技术细节未知,但可能包括:1) 低秩矩阵的秩的选择:需要平衡内存占用和性能。2) 子空间更新频率:需要根据训练数据和模型变化进行调整。3) 与FSDP的集成方式:需要考虑数据划分和梯度同步的效率。4) 损失函数:标准的交叉熵损失函数可能被使用,但也可以根据具体任务进行调整。
🖼️ 关键图片

📊 实验亮点
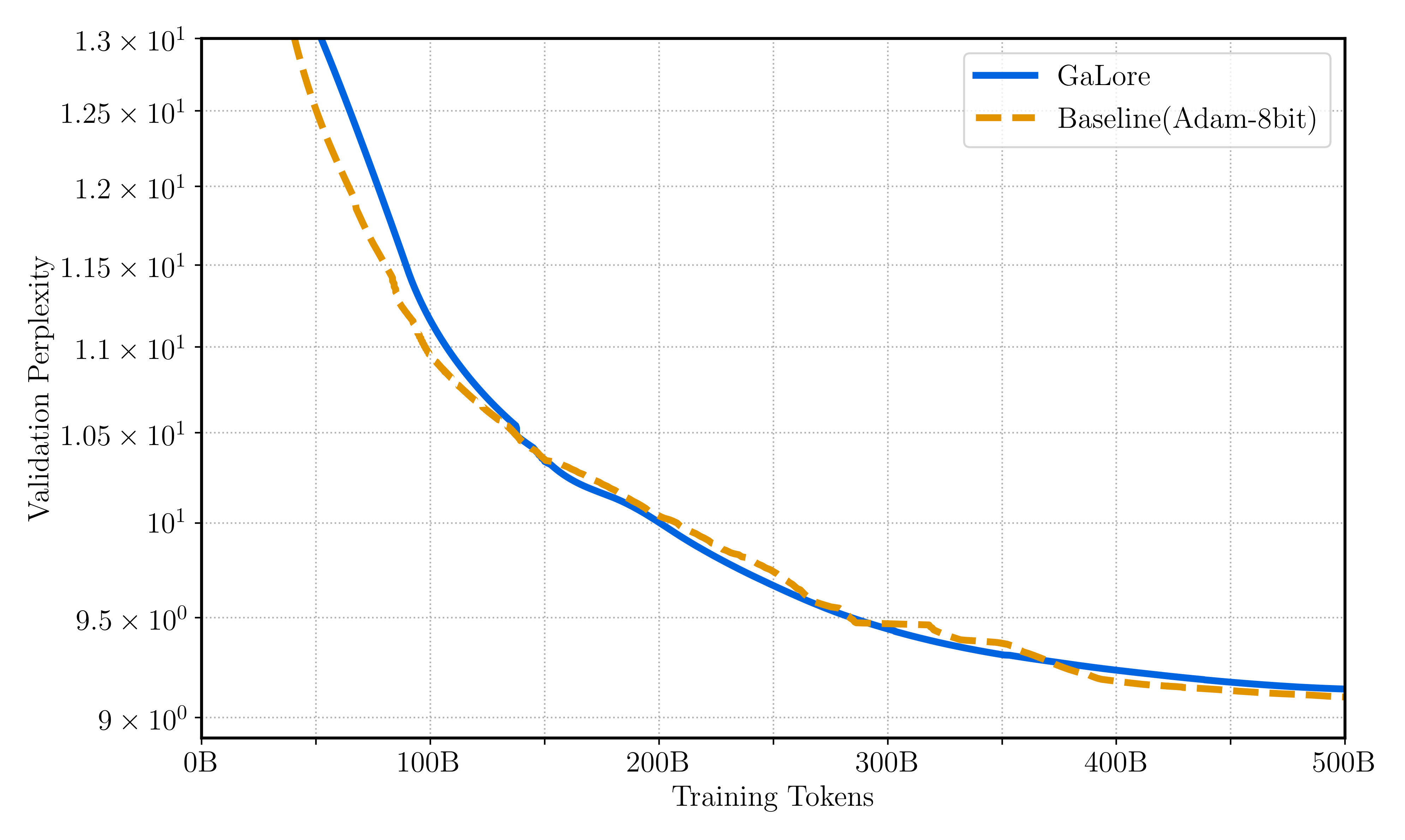
论文通过使用GaLore 2从头开始预训练Llama 7B模型,并使用了高达5000亿个训练token,证明了其在大规模LLM预训练场景中的有效性和可扩展性。具体的性能数据和对比基线未知,但该实验结果表明GaLore 2有潜力显著降低LLM训练的内存成本。
🎯 应用场景
GaLore 2可应用于大规模语言模型的预训练和微调,尤其是在资源受限的环境下。它能够降低训练所需的GPU内存,从而支持更大规模的模型和数据集。这对于开发更强大的自然语言处理应用,如智能助手、机器翻译和文本生成等具有重要意义。未来,GaLore 2可以进一步扩展到其他深度学习模型和任务中。
📄 摘要(原文)
Large language models (LLMs) have revolutionized natural language understanding and generation but face significant memory bottlenecks during training. GaLore, Gradient Low-Rank Projection, addresses this issue by leveraging the inherent low-rank structure of weight gradients, enabling substantial memory savings without sacrificing performance. Recent works further extend GaLore from various aspects, including low-bit quantization and higher-order tensor structures. However, there are several remaining challenges for GaLore, such as the computational overhead of SVD for subspace updates and the integration with state-of-the-art training parallelization strategies (e.g., FSDP). In this paper, we present GaLore 2, an efficient and scalable GaLore framework that addresses these challenges and incorporates recent advancements. In addition, we demonstrate the scalability of GaLore 2 by pre-training Llama 7B from scratch using up to 500 billion training tokens, highlighting its potential impact on real LLM pre-training scenarios.