Interactive Double Deep Q-network: Integrating Human Interventions and Evaluative Predictions in Reinforcement Learning of Autonomous Driving
作者: Alkis Sygkounas, Ioannis Athanasiadis, Andreas Persson, Michael Felsberg, Amy Loutfi
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-04-28
备注: Accepted at IEEE Intelligent Vehicles Symposium (IV) 2025, 8 pages
💡 一句话要点
提出交互式双深度Q网络(iDDQN),融合人类干预提升自动驾驶强化学习性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人机协作 强化学习 自动驾驶 深度Q网络 人类干预
📋 核心要点
- 现有强化学习方法在自动驾驶等高安全场景中,难以有效融合人类专家知识,导致学习效率和安全性受限。
- iDDQN通过修改Q值更新方程,将人类干预行为直接融入强化学习训练,实现人与智能体的协同策略开发。
- 实验表明,iDDQN在模拟自动驾驶场景中,性能优于行为克隆、DQfD等方法,有效提升了性能和适应性。
📝 摘要(中文)
本研究提出了一种交互式双深度Q网络(iDDQN),这是一种人机协同(HITL)方法,通过将人类的洞察力直接融入强化学习(RL)的训练过程中来增强RL,从而提高模型性能,尤其是在自动驾驶等需要高精度和安全性的应用中。所提出的iDDQN方法修改了Q值更新方程,以整合人类和智能体的行为,从而建立一种用于策略开发的协作方法。此外,我们还提出了一个离线评估框架,该框架模拟智能体的轨迹,就好像没有发生人为干预一样,以评估人为干预的有效性。在模拟自动驾驶场景中的实验结果表明,iDDQN在利用人类专业知识来提高性能和适应性方面优于已建立的方法,包括行为克隆(BC)、HG-DAgger、基于演示的深度Q学习(DQfD)和原始DRL。
🔬 方法详解
问题定义:自动驾驶强化学习任务中,如何有效利用人类专家的知识来提升学习效率和安全性是一个关键问题。传统的强化学习方法往往难以直接融合人类经验,导致学习过程缓慢,且在复杂或危险场景下表现不稳定。现有方法,如行为克隆,虽然可以模仿人类行为,但缺乏探索能力,难以超越人类水平。而直接使用人类数据进行预训练的强化学习方法,也可能受到人类数据质量的限制。
核心思路:iDDQN的核心思路是将人类干预作为一种特殊的动作,直接融入到强化学习的Q值更新过程中。通过修改Q值更新方程,使得智能体能够同时学习自身行为和人类干预行为的价值,从而实现人与智能体的协同学习。这种方法允许智能体在学习过程中不断接受人类的指导,从而更快地收敛到最优策略,并提高在复杂场景下的适应性。
技术框架:iDDQN的整体框架基于Double Deep Q-Network (DDQN)。在标准的DDQN框架中,使用两个神经网络:Q网络和目标Q网络。Q网络用于估计当前状态下每个动作的Q值,而目标Q网络用于稳定训练过程。iDDQN在此基础上,引入了人类干预信号。当人类进行干预时,iDDQN会将人类的动作作为一种特殊的动作,并将其Q值更新到Q网络中。此外,论文还提出了一个离线评估框架,用于评估人类干预的有效性。该框架通过模拟没有人类干预的智能体轨迹,来比较有无人类干预时的性能差异。
关键创新:iDDQN的关键创新在于将人类干预直接融入到Q值更新方程中,从而实现人与智能体的协同学习。与传统的基于演示的强化学习方法不同,iDDQN不需要预先收集大量的人类数据,而是可以在训练过程中动态地接受人类的指导。此外,iDDQN还提出了一个离线评估框架,用于评估人类干预的有效性,这有助于更好地理解人类干预对智能体学习的影响。
关键设计:iDDQN的关键设计在于Q值更新方程的修改。具体来说,当人类进行干预时,iDDQN会将人类的动作的Q值设置为一个较高的值,从而鼓励智能体学习人类的行为。此外,iDDQN还使用了一个折扣因子来控制人类干预的影响程度。折扣因子越大,人类干预的影响越大。在网络结构方面,iDDQN可以使用任何标准的深度神经网络结构,例如卷积神经网络或循环神经网络。损失函数通常采用均方误差损失函数,用于衡量Q网络的预测值与目标Q值之间的差异。
🖼️ 关键图片


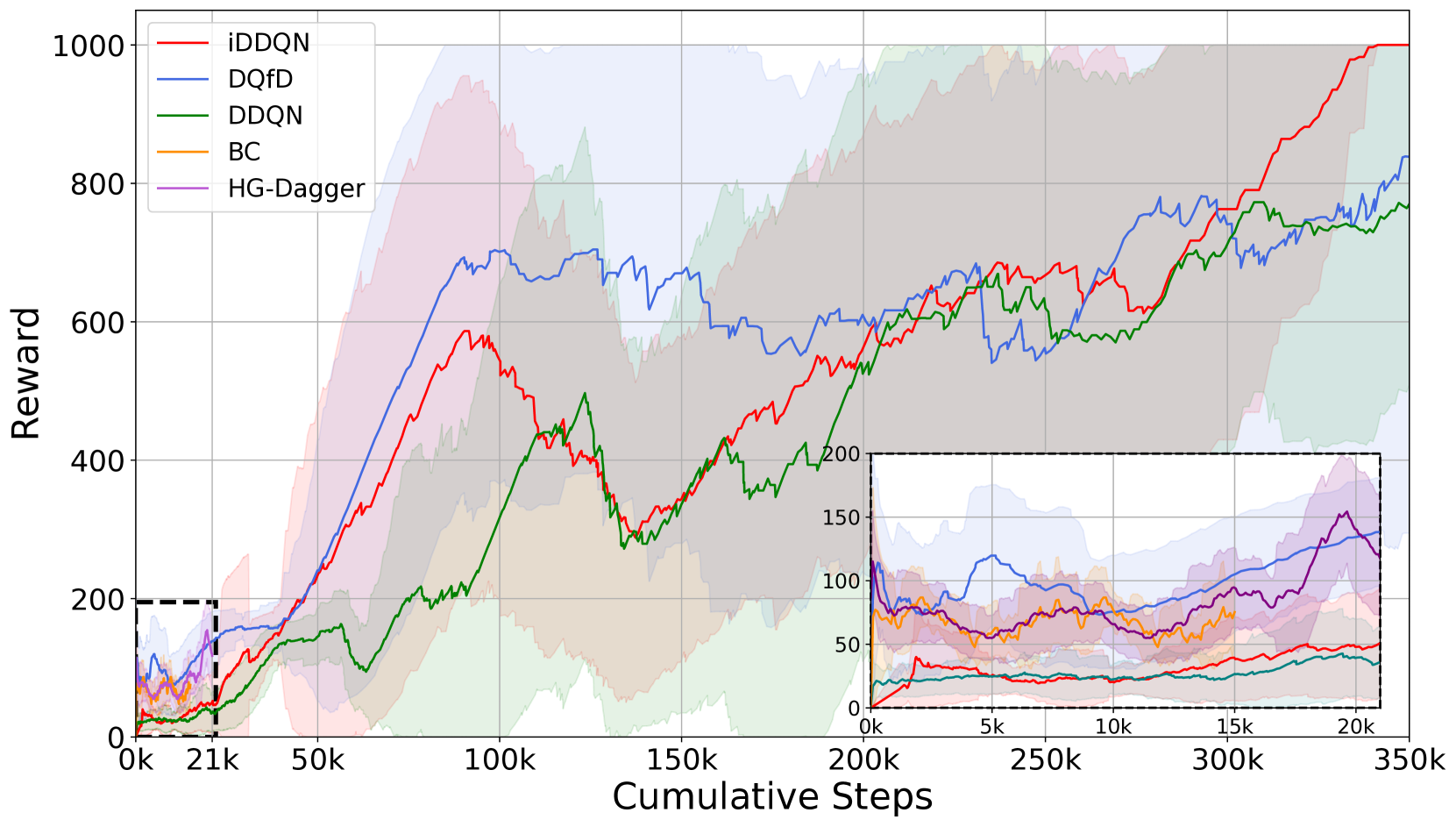
📊 实验亮点
实验结果表明,在模拟自动驾驶场景中,iDDQN显著优于行为克隆(BC)、HG-DAgger、基于演示的深度Q学习(DQfD)和原始DRL等基线方法。iDDQN能够更快地学习到最优策略,并在复杂场景下表现出更好的适应性。具体性能提升数据在论文中给出,证明了iDDQN在利用人类专业知识方面的有效性。
🎯 应用场景
iDDQN方法可应用于各种需要人机协作的强化学习任务,例如自动驾驶、机器人控制、游戏AI等。通过融合人类专家的知识,可以显著提高智能体的学习效率和安全性,尤其是在复杂或危险的环境中。该方法还有助于开发更加智能和可靠的自主系统,从而在交通运输、工业自动化等领域产生深远影响。
📄 摘要(原文)
Integrating human expertise with machine learning is crucial for applications demanding high accuracy and safety, such as autonomous driving. This study introduces Interactive Double Deep Q-network (iDDQN), a Human-in-the-Loop (HITL) approach that enhances Reinforcement Learning (RL) by merging human insights directly into the RL training process, improving model performance. Our proposed iDDQN method modifies the Q-value update equation to integrate human and agent actions, establishing a collaborative approach for policy development. Additionally, we present an offline evaluative framework that simulates the agent's trajectory as if no human intervention had occurred, to assess the effectiveness of human interventions. Empirical results in simulated autonomous driving scenarios demonstrate that iDDQN outperforms established approaches, including Behavioral Cloning (BC), HG-DAgger, Deep Q-Learning from Demonstrations (DQfD), and vanilla DRL in leveraging human expertise for improving performance and adaptability.