Soft-Label Caching and Sharpening for Communication-Efficient Federated Distillation
作者: Kitsuya Azuma, Takayuki Nishio, Yuichi Kitagawa, Wakako Nakano, Takahito Tanimura
分类: cs.LG
发布日期: 2025-04-28 (更新: 2025-12-02)
备注: 23 pages, 18 figures
🔗 代码/项目: GITHUB
💡 一句话要点
SCARLET:面向通信高效联邦蒸馏的软标签缓存与锐化框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 知识蒸馏 软标签缓存 通信效率 模型聚合 熵减少聚合 异构环境
📋 核心要点
- 传统联邦学习因频繁参数共享导致通信开销大,且模型异构性受限,难以满足实际应用需求。
- SCARLET框架通过软标签缓存和增强的熵减少聚合机制,减少冗余通信,提高通信效率。
- 实验结果表明,SCARLET在保持竞争力的准确性前提下,通信成本降低高达50%,优于现有方法。
📝 摘要(中文)
联邦学习(FL)通过在去中心化客户端上进行协作模型训练,并在本地保留数据来增强隐私。然而,传统的FL依赖于频繁的参数共享,导致高通信开销和有限的模型异构性。基于蒸馏的FL方法通过共享预测(软标签,即归一化的概率分布)来解决这些问题,但它们通常涉及跨通信轮次的冗余传输,降低了效率。我们提出了SCARLET,这是一个新颖的框架,集成了同步软标签缓存和增强的熵减少聚合(Enhanced ERA)机制。SCARLET通过重用缓存的软标签来最小化冗余通信,与现有方法相比,通信成本降低高达50%,同时保持了具有竞争力的准确性。增强的ERA解决了传统基于温度的聚合的基本不稳定性,确保了在各种客户端场景中的鲁棒控制和高性能。实验评估表明,SCARLET在准确性和通信效率方面始终优于最先进的基于蒸馏的FL方法。SCARLET的实现可在https://github.com/kitsuyaazuma/SCARLET公开获取。
🔬 方法详解
问题定义:联邦学习中,基于参数共享的传统方法通信开销大,限制了模型异构性。基于蒸馏的方法虽然通过共享软标签降低了通信量,但存在跨轮次冗余传输的问题,效率不高。现有基于温度的聚合方法在客户端场景多样时,稳定性较差。
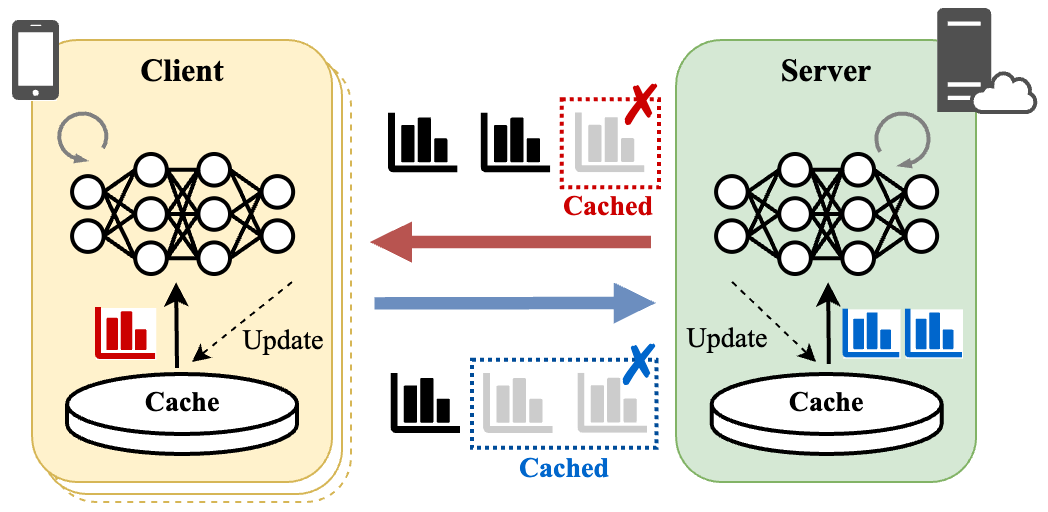
核心思路:SCARLET的核心在于通过软标签缓存机制减少冗余通信,并利用增强的熵减少聚合(Enhanced ERA)机制提高模型聚合的稳定性和性能。软标签缓存避免了重复传输相似的软标签,而Enhanced ERA则解决了传统温度缩放方法在异构环境下的不稳定性。
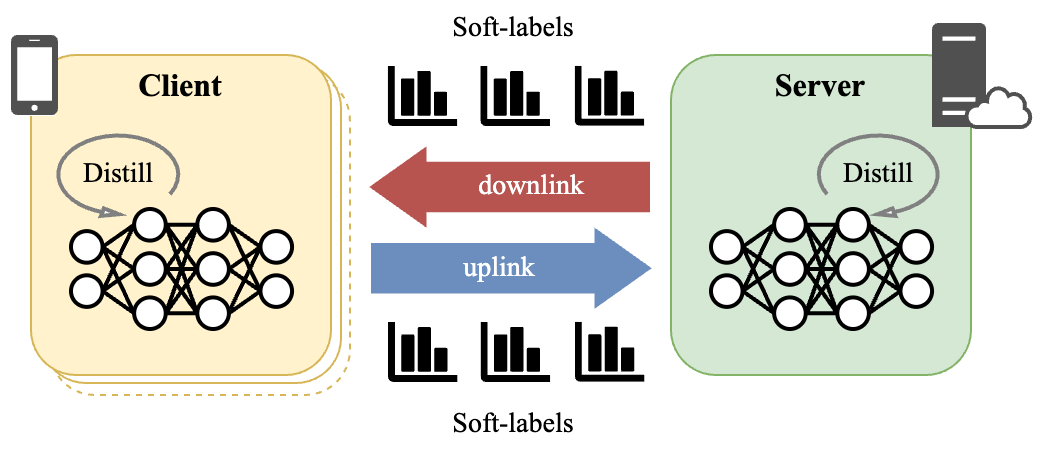
技术框架:SCARLET框架主要包含以下几个阶段:1) 客户端本地训练:每个客户端使用本地数据训练模型,并生成软标签。2) 软标签缓存:客户端将生成的软标签存储在本地缓存中。3) 服务器端聚合:服务器接收客户端上传的软标签(如果缓存中没有),并使用Enhanced ERA机制进行聚合。4) 模型更新:服务器将聚合后的模型参数发送给客户端,客户端更新本地模型。
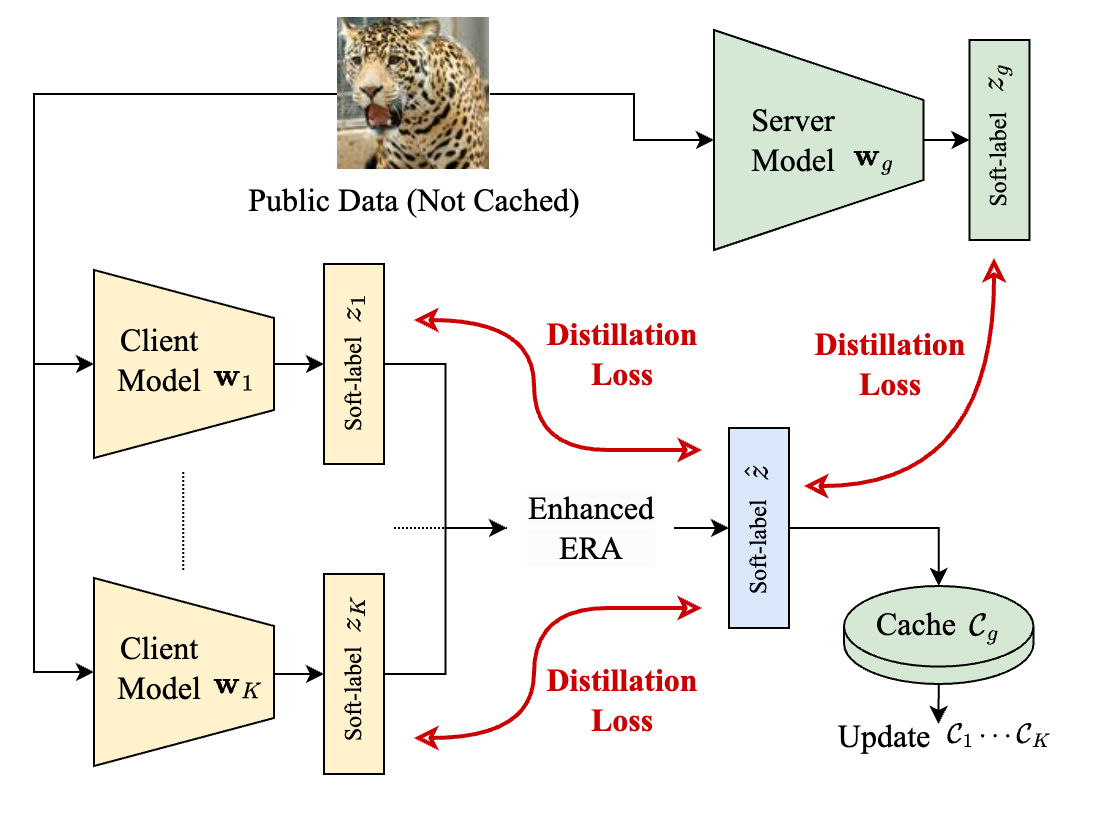
关键创新:SCARLET的关键创新在于:1) 引入了同步软标签缓存机制,有效减少了冗余通信。2) 提出了增强的熵减少聚合(Enhanced ERA)机制,解决了传统温度缩放方法在异构环境下的不稳定性,提高了模型聚合的鲁棒性。
关键设计:Enhanced ERA机制是关键设计之一。它通过动态调整温度参数,使得聚合后的软标签分布更加集中,从而提高模型的性能。具体的温度调整策略未知,但目标是解决传统温度缩放方法在客户端数据分布差异大时表现不佳的问题。此外,软标签缓存的同步策略也至关重要,需要保证客户端和服务器端缓存的一致性,避免数据不一致导致的问题。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SCARLET在通信效率方面显著优于现有的基于蒸馏的联邦学习方法,通信成本降低高达50%,同时保持了具有竞争力的准确性。这表明SCARLET在实际应用中具有很高的价值,能够有效降低联邦学习的部署成本。
🎯 应用场景
SCARLET框架适用于各种需要联邦学习的场景,例如移动设备上的个性化推荐、医疗数据分析、金融风控等。通过降低通信开销和提高模型聚合的稳定性,SCARLET能够更好地支持大规模、异构的联邦学习应用,加速人工智能在各个领域的落地。
📄 摘要(原文)
Federated Learning (FL) enables collaborative model training across decentralized clients, enhancing privacy by keeping data local. Yet conventional FL, relying on frequent parameter-sharing, suffers from high communication overhead and limited model heterogeneity. Distillation-based FL approaches address these issues by sharing predictions (soft-labels, i.e., normalized probability distributions) instead, but they often involve redundant transmissions across communication rounds, reducing efficiency. We propose SCARLET, a novel framework integrating synchronized soft-label caching and an enhanced Entropy Reduction Aggregation (Enhanced ERA) mechanism. SCARLET minimizes redundant communication by reusing cached soft-labels, achieving up to 50% reduction in communication costs compared to existing methods while maintaining competitive accuracy. Enhanced ERA resolves the fundamental instability of conventional temperature-based aggregation, ensuring robust control and high performance in diverse client scenarios. Experimental evaluations demonstrate that SCARLET consistently outperforms state-of-the-art distillation-based FL methods in terms of accuracy and communication efficiency. The implementation of SCARLET is publicly available at https://github.com/kitsuyaazuma/SCARLET.