Hierarchical Attention Generates Better Proofs
作者: Jianlong Chen, Chao Li, Yang Yuan, Andrew C Yao
分类: cs.LG, cs.AI, cs.CL, cs.LO
发布日期: 2025-04-27
备注: 15 pages with 3 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出层级注意力机制,提升大语言模型在形式化定理证明中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 形式化定理证明 层级注意力机制 大型语言模型 数学推理 正则化方法
📋 核心要点
- 现有大语言模型在形式化定理证明中缺乏对数学证明层级结构的有效建模。
- 引入层级注意力正则化方法,通过多层级结构对齐LLM的注意力与数学推理过程。
- 实验结果表明,该方法能有效提升证明成功率并降低证明复杂度。
📝 摘要(中文)
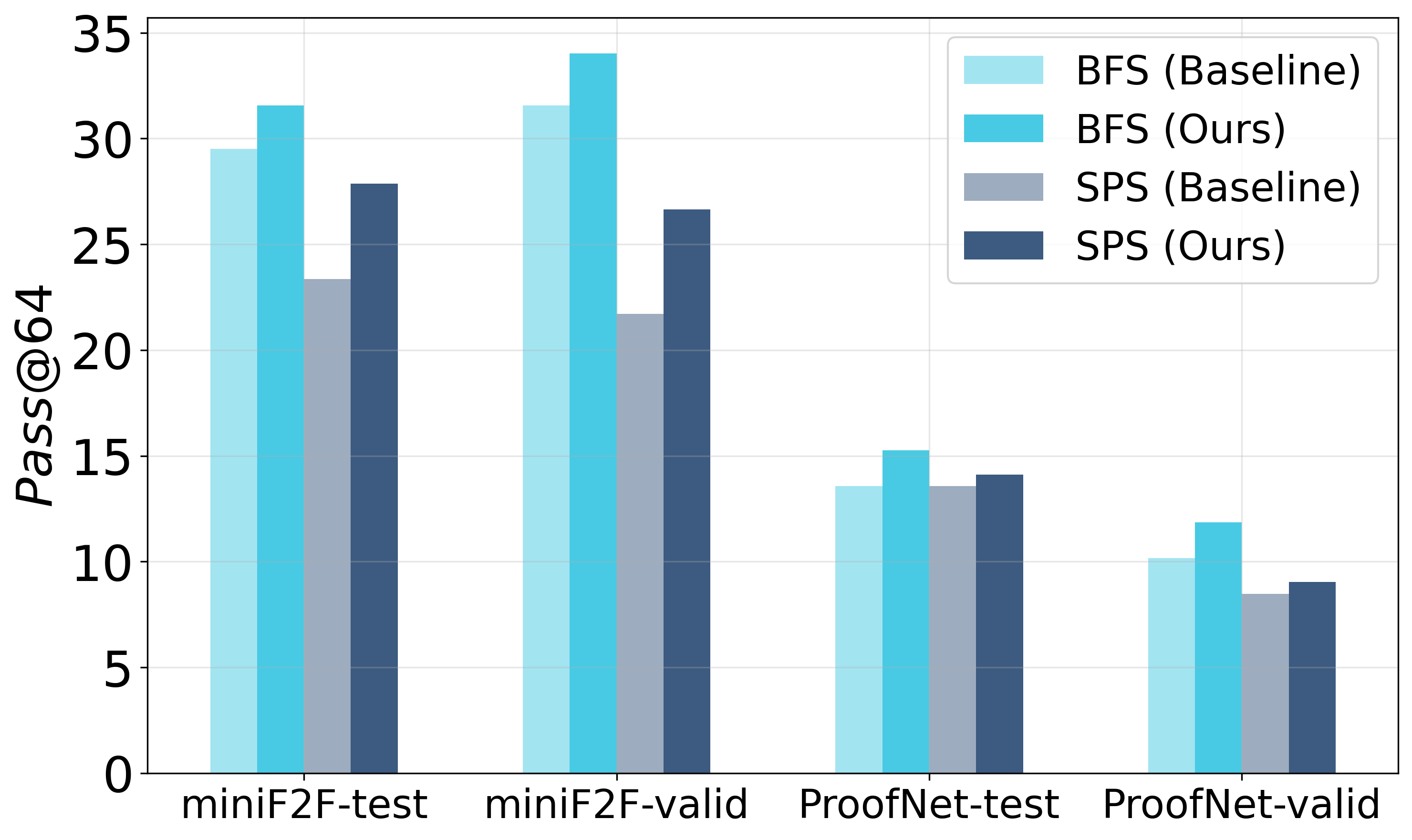
大型语言模型(LLMs)在形式化定理证明方面展现出潜力,但其token级别的处理方式通常无法捕捉数学证明固有的层级结构。我们提出了一种名为“层级注意力”(Hierarchical Attention)的正则化方法,旨在使LLMs的注意力机制与数学推理结构对齐。我们的方法建立了一个从基础元素到高层概念的五层层级结构,确保证明生成过程中结构化的信息流动。实验表明,我们的方法在miniF2F上将证明成功率提高了2.05%,在ProofNet上提高了1.69%,同时分别降低了23.81%和16.50%的证明复杂度。代码已在https://github.com/Car-pe/HAGBP上发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在形式化定理证明中,由于缺乏对数学证明内在层级结构的有效建模,导致证明成功率不高且证明过程复杂的问题。现有方法通常以token级别处理,忽略了数学证明从基础概念到高层抽象的层层递进关系。
核心思路:论文的核心思路是引入层级注意力机制,通过正则化方法引导LLM的注意力机制与数学推理的层级结构对齐。具体来说,就是构建一个多层级的结构,让模型在不同层级上关注不同的信息,从而更好地理解和生成证明。
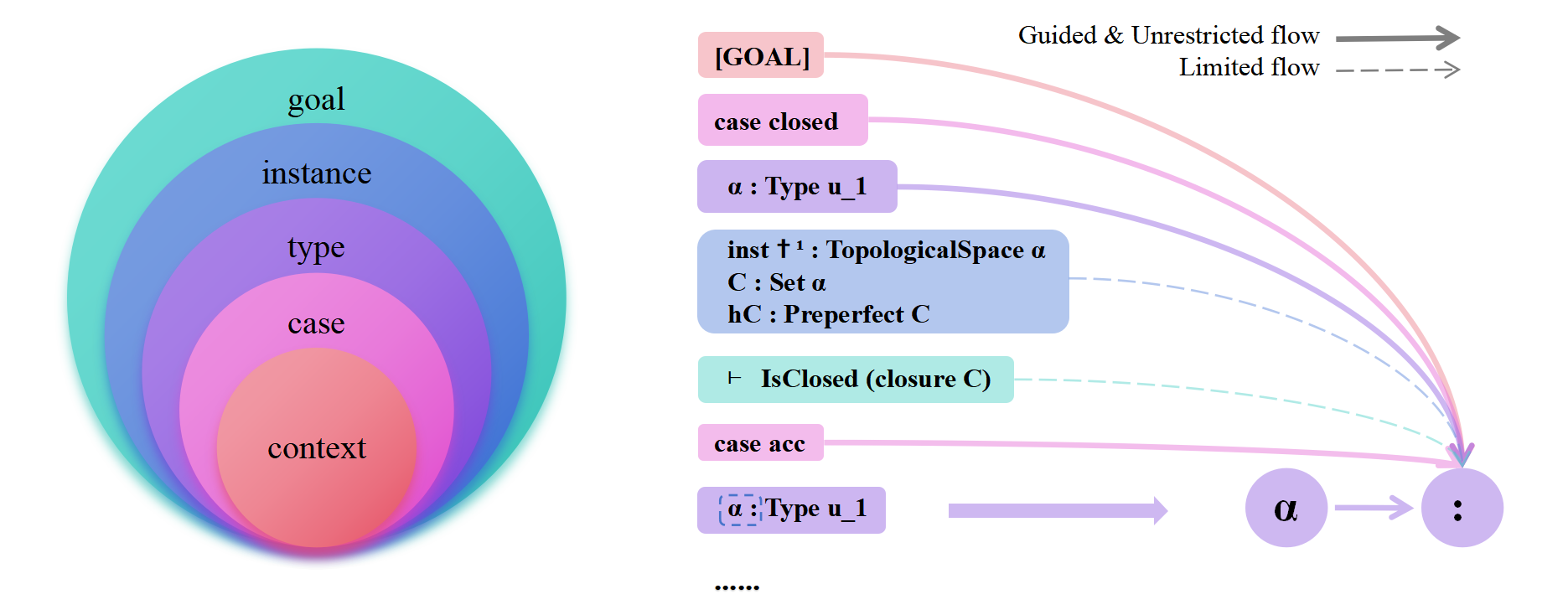
技术框架:该方法的核心是层级注意力机制,它建立了一个五层层级结构,从基础元素到高层概念,包括:(1) 词法层 (Lexical Layer),关注token级别的语义;(2) 表达式层 (Expression Layer),关注数学表达式的结构;(3) 语句层 (Statement Layer),关注数学语句的含义;(4) 推理步骤层 (Inference Step Layer),关注推理步骤的逻辑关系;(5) 证明策略层 (Proof Strategy Layer),关注整体证明策略。模型在每一层都学习相应的注意力权重,从而实现结构化的信息流动。
关键创新:该方法最重要的创新点在于将数学证明的层级结构显式地融入到LLM的注意力机制中。与传统的token级别注意力机制不同,层级注意力机制能够更好地捕捉数学证明的内在逻辑关系,从而提高证明的成功率和效率。
关键设计:论文中关键的设计包括:五层层级结构的划分,每一层对应不同的数学概念抽象级别;注意力权重的正则化方法,鼓励模型学习符合层级结构的注意力模式;以及损失函数的设计,综合考虑了证明成功率和证明复杂度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的层级注意力机制在miniF2F和ProofNet数据集上分别将证明成功率提高了2.05%和1.69%,同时分别降低了23.81%和16.50%的证明复杂度。这些结果表明,该方法能够有效提升LLM在形式化定理证明方面的性能。
🎯 应用场景
该研究成果可应用于自动定理证明、数学辅助教学、形式化验证等领域。通过提升LLM在形式化推理方面的能力,可以帮助研究人员更高效地进行数学研究,并为学生提供更智能化的学习工具。未来,该方法有望扩展到其他需要复杂推理的领域,如代码生成、知识图谱推理等。
📄 摘要(原文)
Large language models (LLMs) have shown promise in formal theorem proving, but their token-level processing often fails to capture the inherent hierarchical nature of mathematical proofs. We introduce \textbf{Hierarchical Attention}, a regularization method that aligns LLMs' attention mechanisms with mathematical reasoning structures. Our approach establishes a five-level hierarchy from foundational elements to high-level concepts, ensuring structured information flow in proof generation. Experiments demonstrate that our method improves proof success rates by 2.05\% on miniF2F and 1.69\% on ProofNet while reducing proof complexity by 23.81\% and 16.50\% respectively. The code is available at https://github.com/Car-pe/HAGBP.