A Unified MDL-based Binning and Tensor Factorization Framework for PDF Estimation
作者: Mustafa Musab, Joseph K. Chege, Arie Yeredor, Martin Haardt
分类: cs.LG, cs.IT, math.PR, stat.ML
发布日期: 2025-04-25 (更新: 2025-09-28)
💡 一句话要点
提出基于MDL的联合分箱与张量分解框架,用于概率密度函数估计
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 概率密度估计 最小描述长度 张量分解 分箱算法 非参数估计
📋 核心要点
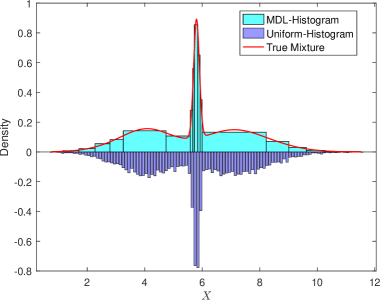
- 传统密度估计方法如均匀直方图,在处理非均匀分布数据时,难以捕捉局部变化,且不连续性影响后续任务。
- 论文提出一种基于MDL的分箱方法,结合分位数切割,并利用张量分解技术进行多元概率密度函数估计。
- 实验结果表明,该方法在合成数据和真实干豆分类数据集上均表现出良好的性能。
📝 摘要(中文)
可靠的密度估计是统计学和机器学习中众多应用的基础。在许多实际场景中,数据最好被建模为成分密度的混合,这些成分密度捕获了复杂和多模态的模式。然而,基于均匀直方图的传统密度估计器通常无法捕获局部变化,尤其是在底层分布高度不均匀时。此外,直方图固有的不连续性给需要平滑导数的任务带来了挑战,例如基于梯度的优化、聚类和非参数判别分析。本文提出了一种新的非参数方法,用于多元概率密度函数(PDF)估计,该方法利用基于最小描述长度(MDL)的分箱与分位数切割。我们的方法建立在张量分解技术之上,利用联合概率张量的典型多项式分解(CPD)。我们在合成数据和一个具有挑战性的真实干豆分类数据集上证明了该方法的有效性。
🔬 方法详解
问题定义:论文旨在解决多元概率密度函数(PDF)的估计问题。现有基于直方图的方法在处理非均匀分布时精度不足,且直方图的不连续性限制了其在梯度优化、聚类等任务中的应用。
核心思路:论文的核心思路是结合基于最小描述长度(MDL)的分箱方法和张量分解技术。MDL准则用于自适应地确定最优分箱策略,分位数切割保证了分箱的合理性。张量分解则用于高效地表示和估计多元联合概率分布。
技术框架:该方法主要包含以下几个阶段:1. 数据预处理:对输入数据进行必要的清洗和归一化。2. 基于MDL的分箱:使用MDL准则和分位数切割,对每个维度的数据进行自适应分箱。3. 构建联合概率张量:根据分箱结果,构建数据的联合概率张量。4. 张量分解:对联合概率张量进行典型多项式分解(CPD),得到低秩表示。5. 概率密度函数估计:利用分解结果重构概率密度函数。
关键创新:该方法的主要创新在于将基于MDL的分箱方法与张量分解技术相结合,用于概率密度函数估计。MDL分箱能够自适应地捕捉数据的局部变化,而张量分解则能够高效地处理高维数据,克服了传统直方图方法的局限性。
关键设计:关键设计包括:1. MDL准则的具体形式,用于平衡模型复杂度和拟合精度。2. 分位数切割的具体实现,用于保证分箱的合理性。3. 张量分解的具体算法选择,例如交替最小二乘法(ALS)。4. 分解秩的选择,需要根据数据的复杂度和计算资源进行权衡。
🖼️ 关键图片


📊 实验亮点
论文在合成数据和真实的干豆分类数据集上验证了所提出方法的有效性。实验结果表明,该方法能够有效地捕捉数据的局部变化,并获得比传统直方图方法更高的密度估计精度。具体性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于各种需要概率密度函数估计的领域,例如异常检测、模式识别、数据挖掘、风险评估和统计建模。特别是在高维数据分析和非均匀分布建模方面,该方法具有潜在的应用价值。未来可进一步扩展到更复杂的概率模型和更大规模的数据集。
📄 摘要(原文)
Reliable density estimation is fundamental for numerous applications in statistics and machine learning. In many practical scenarios, data are best modeled as mixtures of component densities that capture complex and multimodal patterns. However, conventional density estimators based on uniform histograms often fail to capture local variations, especially when the underlying distribution is highly nonuniform. Furthermore, the inherent discontinuity of histograms poses challenges for tasks requiring smooth derivatives, such as gradient-based optimization, clustering, and nonparametric discriminant analysis. In this work, we present a novel non-parametric approach for multivariate probability density function (PDF) estimation that utilizes minimum description length (MDL)-based binning with quantile cuts. Our approach builds upon tensor factorization techniques, leveraging the canonical polyadic decomposition (CPD) of a joint probability tensor. We demonstrate the effectiveness of our method on synthetic data and a challenging real dry bean classification dataset.