NoEsis: Differentially Private Knowledge Transfer in Modular LLM Adaptation
作者: Rob Romijnders, Stefanos Laskaridis, Ali Shahin Shamsabadi, Hamed Haddadi
分类: cs.CR, cs.LG
发布日期: 2025-04-25
备注: ICLR 2025 MCDC workshop
期刊: ICLR 2025 Workshop on Modularity for Collaborative, Decentralized, and Continual Deep Learning
💡 一句话要点
NoEsis:模块化LLM自适应中的差分隐私知识迁移框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 差分隐私 知识迁移 大型语言模型 参数高效微调 模块化 联邦学习 隐私保护
📋 核心要点
- 现有LLM训练面临隐私泄露风险,尤其是在模块化设计中,孤立训练又限制了模型的泛化能力。
- NoEsis框架结合差分隐私和参数高效微调,利用领域专家适配器和通用提示令牌实现知识共享。
- 实验表明,NoEsis在保证隐私的同时,实现了跨领域的知识迁移,并在代码补全任务上显著提升了性能。
📝 摘要(中文)
大型语言模型(LLM)通常在来自各种来源的海量数据上进行训练。即使采用模块化设计(例如,混合专家模型),LLM也可能泄露其来源的隐私信息。相反,孤立地训练此类模型可能会阻碍泛化能力。为此,我们提出了一个框架NoEsis,它建立在模块化、隐私和知识迁移的理想属性之上。NoEsis将差分隐私与混合两阶段参数高效微调相结合,该微调结合了特定领域的低秩适配器(作为专家)和通用提示令牌(作为知识共享的骨干)。在CodeXGLUE上的评估结果表明,NoEsis可以实现可证明的隐私保证,并在不同领域之间实现有形的知识迁移,并且通过实验证明了对成员推理攻击的保护。最后,在代码补全任务中,NoEsis弥合了非共享和非私有基线之间至少77%的准确率差距。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在训练过程中,即使采用模块化结构,也可能泄露训练数据的隐私信息。同时,为了保护隐私而进行孤立训练,会导致模型泛化能力下降,无法充分利用不同领域的数据知识。因此,如何在保证隐私的前提下,实现LLM的知识迁移和泛化是一个关键问题。
核心思路:NoEsis框架的核心思路是将差分隐私(Differential Privacy, DP)技术与参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)相结合,构建一个既能保护数据隐私,又能实现知识迁移的LLM自适应框架。通过模块化的专家适配器和共享的提示令牌,实现领域知识的有效传递。
技术框架:NoEsis框架包含两个主要阶段:首先,针对每个领域的数据,训练一个低秩适配器(Low-Rank Adapter),作为该领域的“专家”。这些适配器是参数高效的,可以减少训练成本。其次,使用共享的提示令牌(Prompt Tokens)作为知识共享的骨干,将不同领域的知识整合到一起。整个框架采用差分隐私机制,保证训练过程中的隐私性。
关键创新:NoEsis的关键创新在于将差分隐私与模块化的参数高效微调相结合,实现了一种新的知识迁移方法。与传统的联邦学习方法相比,NoEsis不需要共享原始数据,而是通过共享适配器和提示令牌来实现知识的传递,从而更好地保护了数据隐私。此外,两阶段的微调策略也提高了训练效率和模型性能。
关键设计:NoEsis的关键设计包括:1) 使用低秩适配器作为领域专家,减少训练参数;2) 使用共享的提示令牌作为知识共享的骨干,促进知识迁移;3) 采用差分隐私机制,保证训练过程的隐私性;4) 使用两阶段微调策略,先训练领域专家适配器,再训练共享提示令牌。具体的参数设置和损失函数选择取决于具体的任务和数据集,但整体目标是平衡隐私保护、知识迁移和模型性能。
🖼️ 关键图片

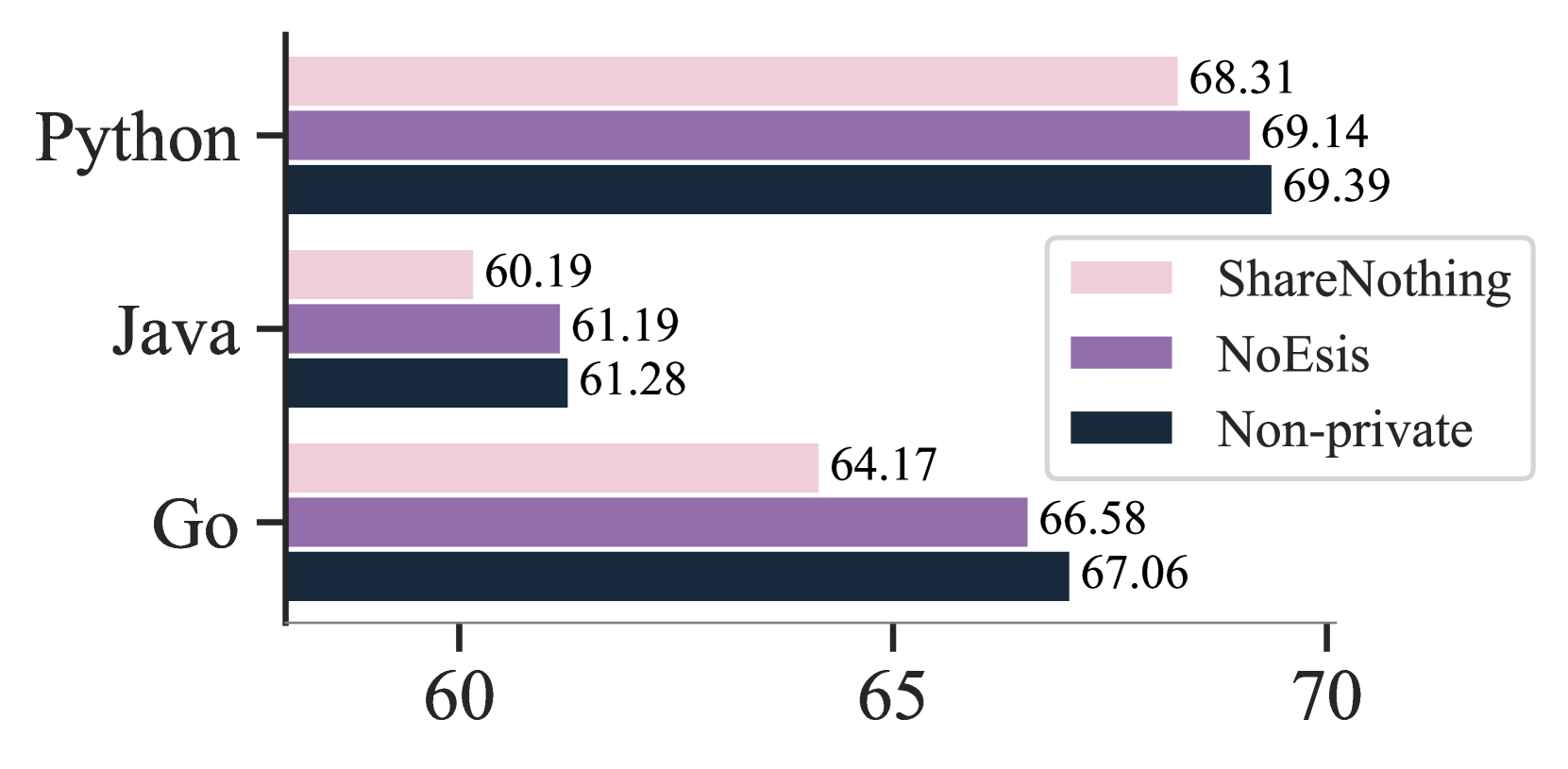

📊 实验亮点
实验结果表明,NoEsis框架在CodeXGLUE数据集上实现了可证明的隐私保证,并在不同领域之间实现了有效的知识迁移。在代码补全任务中,NoEsis弥合了非共享和非私有基线之间至少77%的准确率差距。此外,实验还证明了NoEsis框架能够有效防御成员推理攻击,进一步验证了其隐私保护能力。
🎯 应用场景
NoEsis框架可应用于各种需要保护数据隐私的LLM自适应场景,例如医疗、金融等敏感数据领域。通过该框架,不同机构可以在不共享原始数据的情况下,共同训练和优化LLM,从而提高模型的泛化能力和性能。此外,该框架还可以用于构建个性化的LLM服务,为用户提供更加安全和可靠的智能体验。
📄 摘要(原文)
Large Language Models (LLM) are typically trained on vast amounts of data from various sources. Even when designed modularly (e.g., Mixture-of-Experts), LLMs can leak privacy on their sources. Conversely, training such models in isolation arguably prohibits generalization. To this end, we propose a framework, NoEsis, which builds upon the desired properties of modularity, privacy, and knowledge transfer. NoEsis integrates differential privacy with a hybrid two-staged parameter-efficient fine-tuning that combines domain-specific low-rank adapters, acting as experts, with common prompt tokens, acting as a knowledge-sharing backbone. Results from our evaluation on CodeXGLUE showcase that NoEsis can achieve provable privacy guarantees with tangible knowledge transfer across domains, and empirically show protection against Membership Inference Attacks. Finally, on code completion tasks, NoEsis bridges at least 77% of the accuracy gap between the non-shared and the non-private baseline.