Learning from Less: SINDy Surrogates in RL
作者: Aniket Dixit, Muhammad Ibrahim Khan, Faizan Ahmed, James Brusey
分类: cs.LG, cs.AI
发布日期: 2025-04-25
备注: World Models @ ICLR 2025
💡 一句话要点
提出基于SINDy的强化学习代理环境,降低计算成本并保持性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 代理环境 稀疏动力学辨识 SINDy 模型学习
📋 核心要点
- 现有强化学习环境计算成本高昂,限制了智能体训练的效率和可扩展性。
- 利用SINDy算法学习环境的稀疏非线性动力学模型,构建计算效率更高的代理环境。
- 实验表明,基于SINDy的代理环境能显著降低计算成本,同时保持与原始环境相当的智能体性能。
📝 摘要(中文)
本文提出了一种利用稀疏非线性动力学辨识(SINDy)算法在强化学习(RL)中开发代理环境的方法。通过在OpenAI Gym环境(特别是Mountain Car和Lunar Lander)中的大量实验,证明了该方法的有效性。结果表明,基于SINDy的代理模型能够准确地捕捉这些环境的底层动力学,同时将计算成本降低20-35%。仅需少量交互(Mountain Car为75次,Lunar Lander为1000次),即可实现超过0.997的状态相关性,Mountain Car速度的均方误差低至3.11e-06,LunarLander位置的均方误差低至1.42e-06。在这些代理环境中训练的RL智能体所需的总步数更少(Mountain Car为65,075步 vs. 100,000步,Lunar Lander为801,000步 vs. 1,000,000步),同时实现了与在原始环境中训练的智能体相当的性能,表现出相似的收敛模式和最终性能指标。这项工作通过提供一种生成精确、可解释的代理环境的有效方法,为基于模型的RL领域做出了贡献。
🔬 方法详解
问题定义:论文旨在解决强化学习中环境交互成本高的问题。传统的强化学习算法需要大量的环境交互才能学习到有效的策略,这在计算资源有限或环境交互代价高昂的场景下是不可行的。现有方法,如直接在真实环境中训练,效率低下;而复杂的环境建模方法又难以保证模型的准确性和泛化能力。
核心思路:论文的核心思路是利用SINDy算法学习环境的动力学模型,并用该模型构建一个代理环境。SINDy算法能够从少量数据中识别出控制系统动力学的稀疏表示,从而构建一个计算效率高且准确的代理环境。智能体可以在这个代理环境中进行训练,然后迁移到真实环境中。
技术框架:该方法主要包含两个阶段:1) 使用SINDy算法学习环境动力学模型。通过与真实环境进行少量交互,收集状态转移数据,然后利用SINDy算法识别出描述状态转移的稀疏非线性方程。2) 构建代理环境并训练智能体。基于学习到的动力学模型,构建一个模拟环境,智能体在这个环境中进行训练。训练完成后,可以将智能体部署到真实环境中。
关键创新:该方法的关键创新在于利用SINDy算法学习环境的动力学模型。SINDy算法能够从少量数据中识别出稀疏的动力学方程,这使得构建代理环境所需的交互次数大大减少。与传统的环境建模方法相比,SINDy算法更加高效且易于实现。
关键设计:SINDy算法的关键参数包括稀疏性阈值和候选函数库。稀疏性阈值控制模型的复杂度,候选函数库则决定了模型能够表达的函数形式。论文中,作者针对不同的环境选择了合适的候选函数库,并通过实验调整稀疏性阈值,以获得最佳的建模效果。此外,论文还采用了适当的正则化方法,以防止过拟合。
🖼️ 关键图片
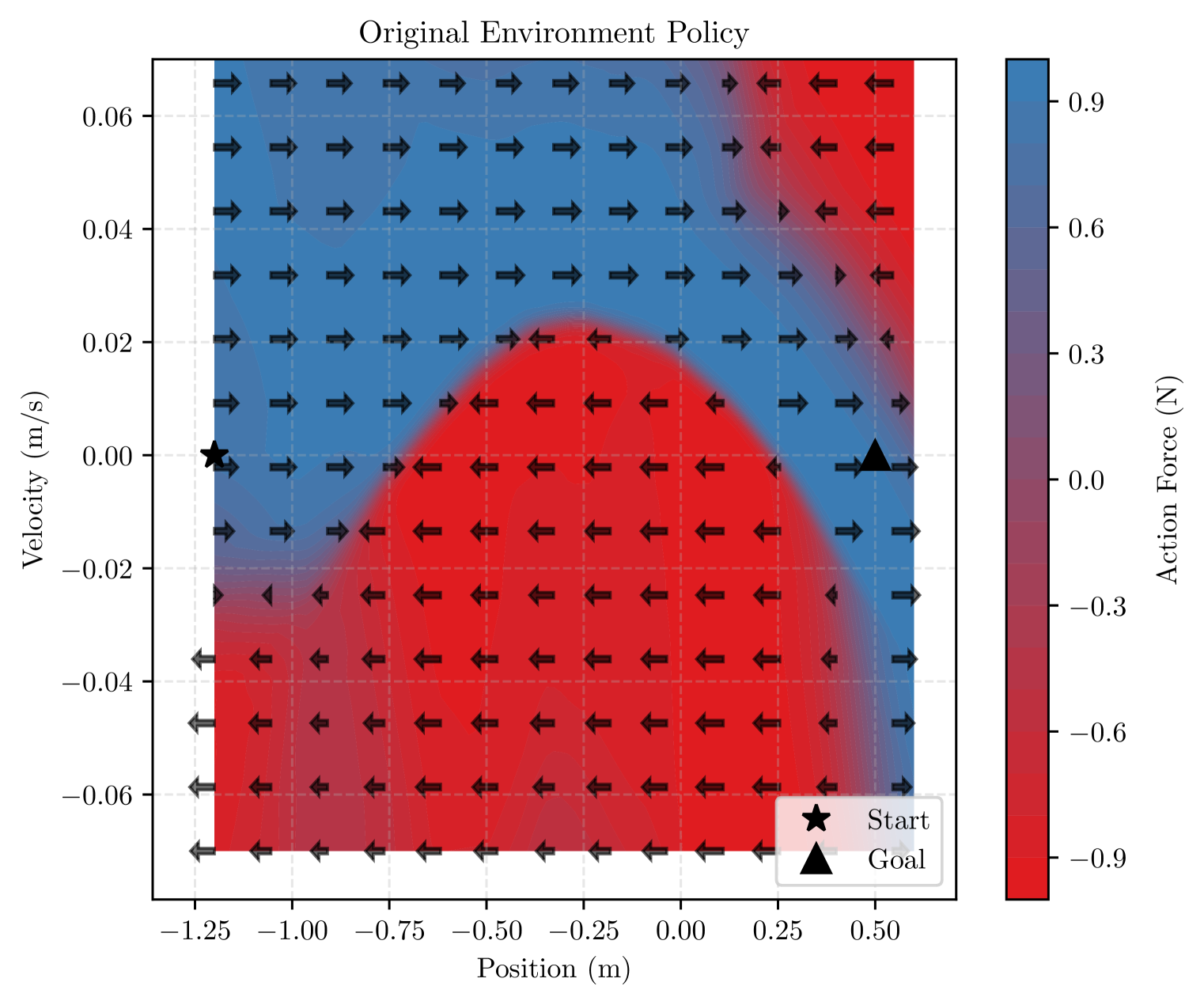
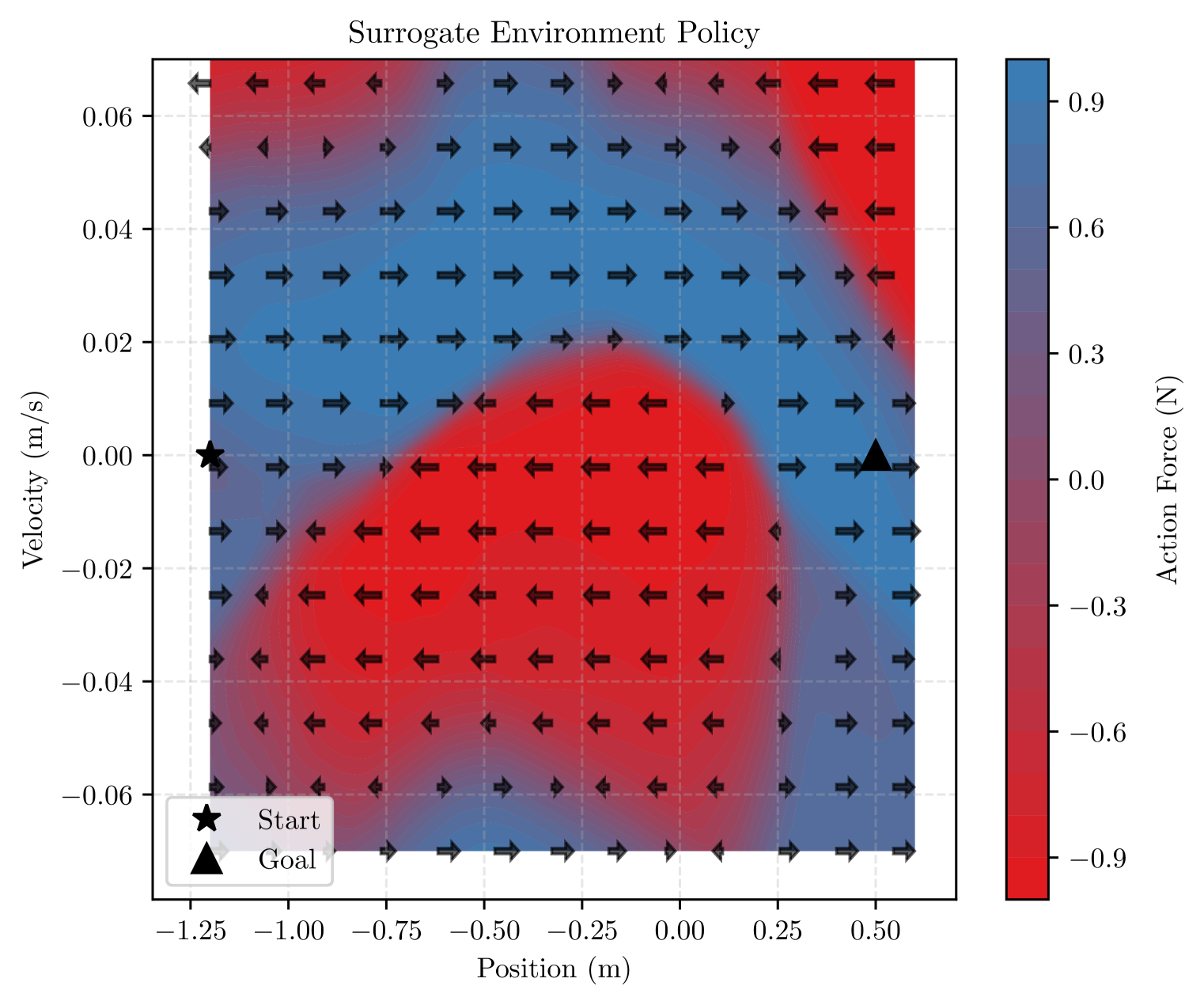
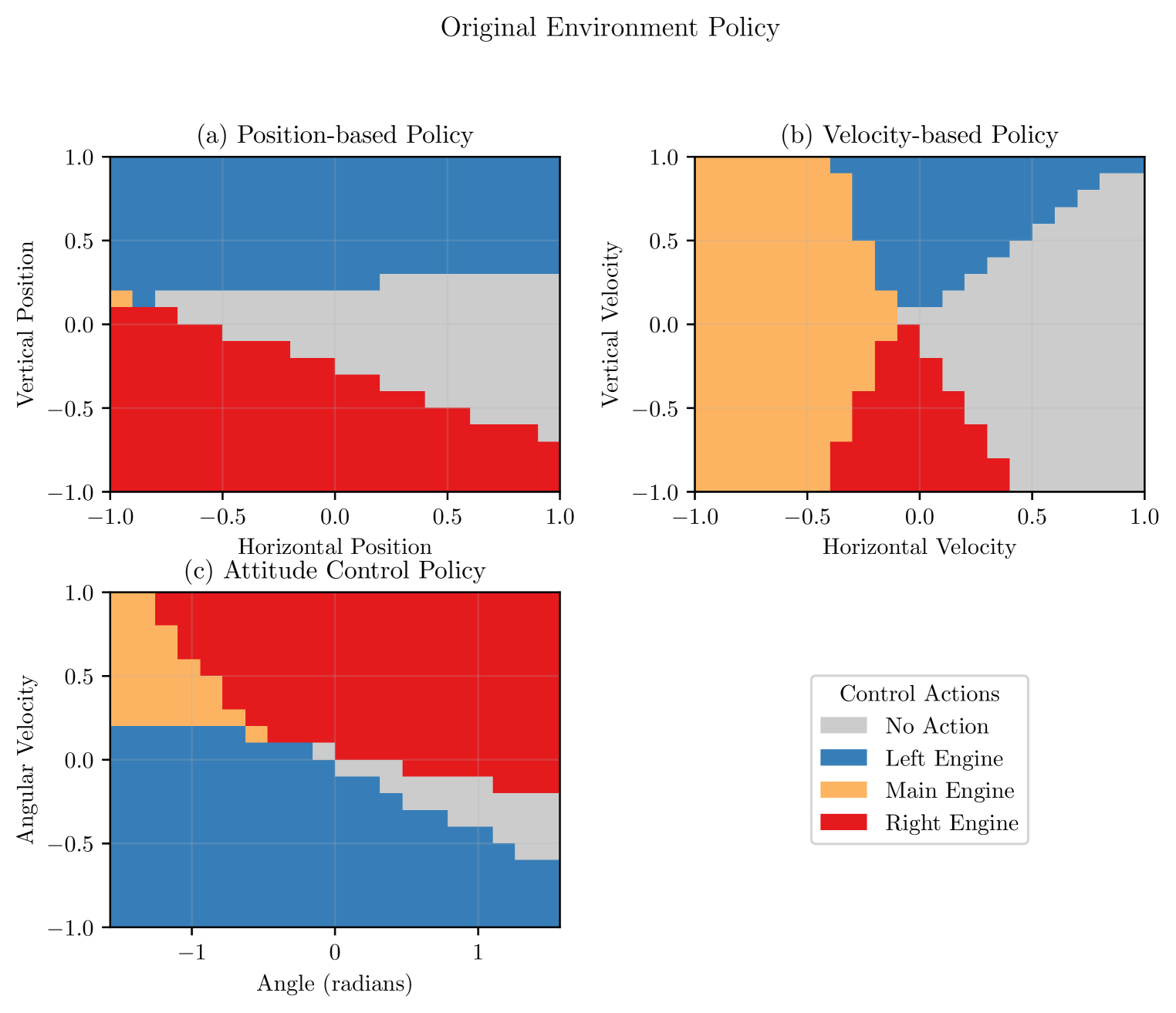
📊 实验亮点
实验结果表明,在Mountain Car和Lunar Lander环境中,仅需少量交互(分别为75次和1000次)即可构建出高精度的代理环境,状态相关性超过0.997,均方误差分别低至3.11e-06和1.42e-06。在代理环境中训练的智能体所需的总步数显著减少(分别减少35%和20%),同时保持了与在原始环境中训练的智能体相当的性能。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、游戏AI等领域。通过构建高效的代理环境,可以加速强化学习智能体的训练过程,降低计算成本,并提高智能体的泛化能力。尤其是在真实环境交互成本高昂或存在安全风险的场景下,该方法具有重要的应用价值。
📄 摘要(原文)
This paper introduces an approach for developing surrogate environments in reinforcement learning (RL) using the Sparse Identification of Nonlinear Dynamics (SINDy) algorithm. We demonstrate the effectiveness of our approach through extensive experiments in OpenAI Gym environments, particularly Mountain Car and Lunar Lander. Our results show that SINDy-based surrogate models can accurately capture the underlying dynamics of these environments while reducing computational costs by 20-35%. With only 75 interactions for Mountain Car and 1000 for Lunar Lander, we achieve state-wise correlations exceeding 0.997, with mean squared errors as low as 3.11e-06 for Mountain Car velocity and 1.42e-06 for LunarLander position. RL agents trained in these surrogate environments require fewer total steps (65,075 vs. 100,000 for Mountain Car and 801,000 vs. 1,000,000 for Lunar Lander) while achieving comparable performance to those trained in the original environments, exhibiting similar convergence patterns and final performance metrics. This work contributes to the field of model-based RL by providing an efficient method for generating accurate, interpretable surrogate environments.