Streaming, Fast and Slow: Cognitive Load-Aware Streaming for Efficient LLM Serving
作者: Chang Xiao, Brenda Yang
分类: cs.HC, cs.LG
发布日期: 2025-04-25 (更新: 2025-07-23)
期刊: The 38th Annual ACM Symposium on User Interface Software and Technology (UIST 25), September 28-October 01, 2025, Busan, Republic of Korea
💡 一句话要点
提出认知负荷感知的LLM流式服务,提升效率并节约计算资源
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 流式服务 认知负荷 自适应传输 计算资源优化
📋 核心要点
- 现有LLM流式服务通常忽略用户阅读速度和内容认知负荷,导致计算资源浪费。
- 论文提出基于认知负荷的自适应流式方法,动态调整LLM输出速度,优化资源分配。
- 实验结果表明,该方法能在保证用户体验的同时,有效降低计算资源消耗。
📝 摘要(中文)
本文提出了一种自适应的流式传输方法,该方法基于推断的认知负荷,实时动态地调整大型语言模型(LLM)流式输出的节奏。该方法估计与流式内容相关的认知负荷,并在复杂或信息丰富的片段期间策略性地减慢流速,从而为其他用户释放计算资源。基于众包用户研究中收集的数据,针对各种LLM生成的内容,进行了统计分析和模拟。结果表明,这种自适应方法可以有效地减少计算消耗,同时在很大程度上保持流速高于用户的正常阅读速度。
🔬 方法详解
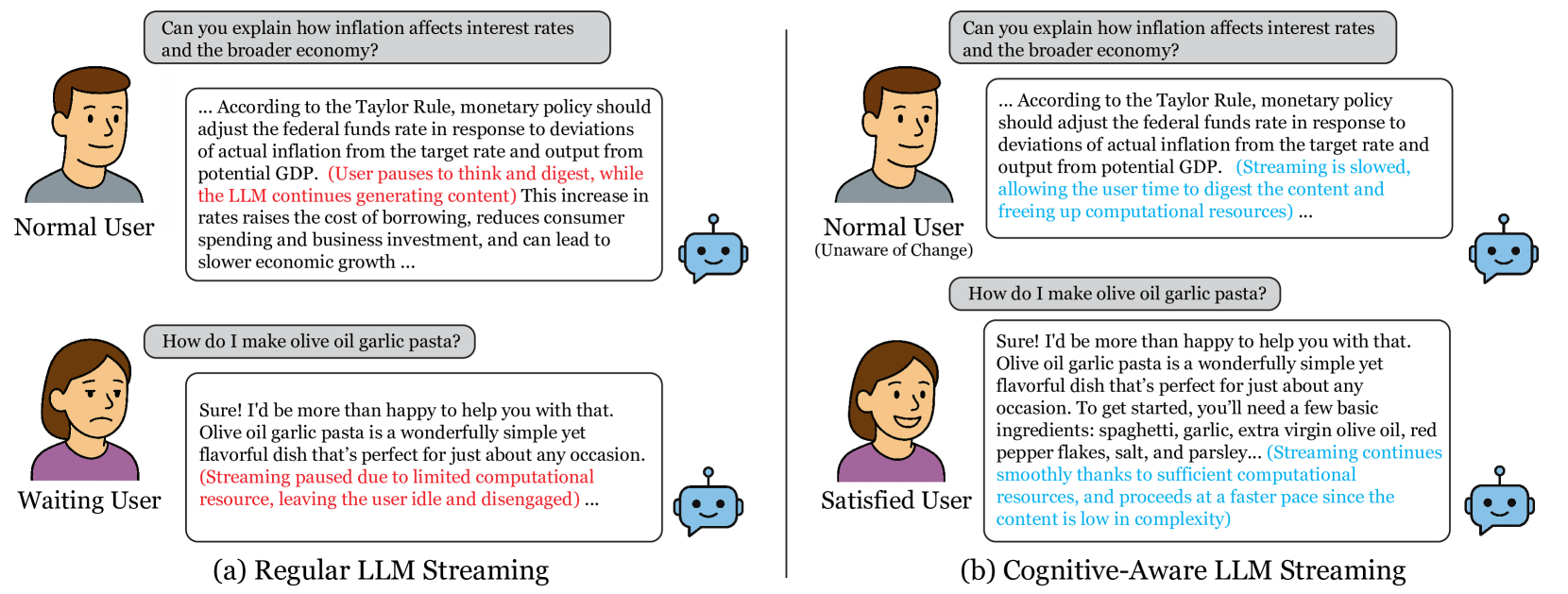
问题定义:现有的大型语言模型(LLM)流式服务,通常以固定的速率逐个token地输出内容,而没有考虑到用户的实际阅读速度以及内容本身的认知负荷。这种做法导致在用户无法及时处理信息时,计算资源被不必要地占用,尤其是在高峰时段,会影响其他用户的服务质量。因此,需要解决的问题是如何根据用户的认知负荷动态调整LLM的输出速度,从而更有效地利用计算资源。
核心思路:论文的核心思路是根据用户在阅读LLM生成内容时的认知负荷,动态地调整流式传输的速度。具体来说,当内容较为复杂或信息密度较高时,降低传输速度,让用户有足够的时间理解;而当内容较为简单时,则可以适当提高传输速度。通过这种方式,可以在保证用户体验的前提下,最大限度地减少计算资源的浪费。
技术框架:该方法主要包含两个核心模块:认知负荷估计模块和自适应流式传输模块。认知负荷估计模块负责实时评估当前输出内容的认知负荷,可以基于文本特征(如句子长度、词汇复杂度等)或用户行为数据(如阅读速度、暂停时间等)进行估计。自适应流式传输模块则根据认知负荷估计的结果,动态调整LLM的输出速度。整体流程为:LLM生成token -> 认知负荷估计 -> 速度调整 -> token流式传输给用户。
关键创新:该方法最重要的创新点在于将认知负荷的概念引入到LLM流式服务中,并提出了一种基于认知负荷的自适应流式传输策略。与传统的固定速率流式传输方法相比,该方法能够更好地匹配用户的阅读需求,从而更有效地利用计算资源。
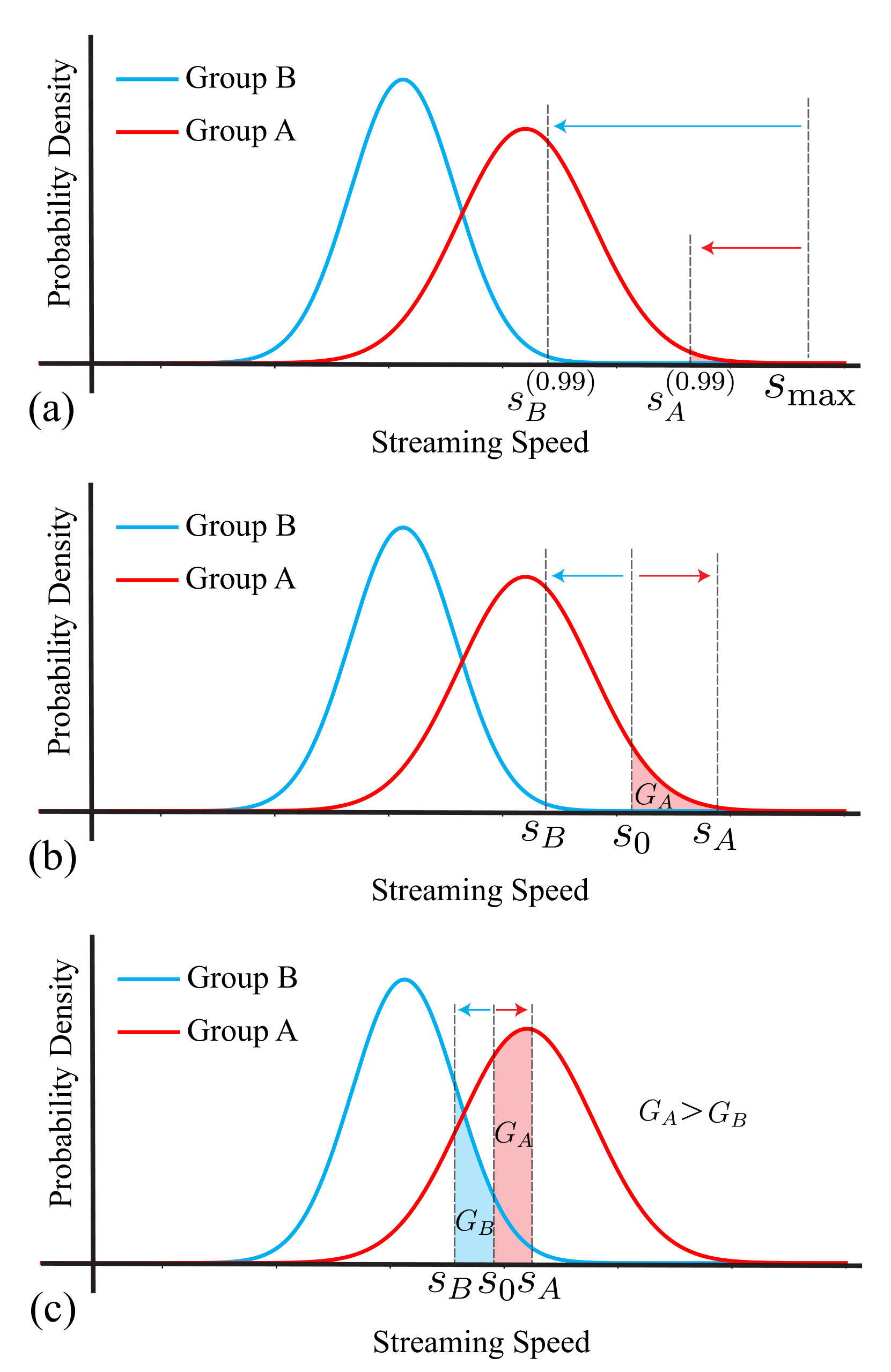
关键设计:认知负荷的估计可以采用多种方法,例如基于文本复杂度的统计模型,或者基于用户行为的机器学习模型。自适应流式传输策略可以采用简单的线性调整,也可以采用更复杂的非线性调整。具体的参数设置需要根据实际的应用场景和用户数据进行调整。论文中提到使用了基于众包用户研究数据的统计模型进行分析和模拟,但具体模型细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该自适应流式传输方法能够在很大程度上保持流速高于用户正常阅读速度的同时,有效地减少计算消耗。具体的性能数据和提升幅度未知,但论文强调该方法在降低计算资源消耗方面的有效性。
🎯 应用场景
该研究成果可应用于各种基于LLM的生成式对话界面,例如智能客服、AI助手、在线教育平台等。通过优化流式传输策略,可以显著降低服务器的计算负载,提高服务质量,并为更多用户提供服务。此外,该方法还可以应用于其他需要实时反馈的场景,例如游戏AI、机器人控制等。
📄 摘要(原文)
Generative conversational interfaces powered by large language models (LLMs) typically stream output token-by-token at a rate determined by computational budget, often neglecting actual human reading speeds and the cognitive load associated with the content. This mismatch frequently leads to inefficient use of computational resources. For example, in cloud-based services, streaming content faster than users can read appears unnecessary, resulting in wasted computational resources and potential delays for other users, particularly during peak usage periods. To address this issue, we propose an adaptive streaming method that dynamically adjusts the pacing of LLM streaming output in real-time based on inferred cognitive load. Our approach estimates the cognitive load associated with streaming content and strategically slows down the stream during complex or information-rich segments, thereby freeing computational resources for other users. We conducted a statistical analysis and simulation based on a statistical model derived from data collected in a crowdsourced user study across various types of LLM-generated content. Our results show that this adaptive method can effectively reduce computational consumption while largely maintaining streaming speed above user's normal reading speed.