High-Fidelity And Complex Test Data Generation For Google SQL Code Generation Services
作者: Shivasankari Kannan, Yeounoh Chung, Amita Gondi, Tristan Swadell, Fatma Ozcan
分类: cs.DB, cs.LG
发布日期: 2025-04-24 (更新: 2025-10-21)
💡 一句话要点
利用LLM生成高保真复杂测试数据,用于Google SQL代码生成服务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: SQL代码生成 测试数据生成 大型语言模型 数据质量 NL2SQL
📋 核心要点
- 现有SQL测试数据生成方法难以处理大型复杂数据结构,且生成的测试数据语义连贯性不足,导致测试覆盖率受限。
- 利用大型语言模型(LLM),结合预处理和后处理策略,生成语法正确、语义相关且符合复杂结构约束的高保真测试数据。
- 实验结果表明,该方法在工业SQL代码生成服务中具有实际应用价值,尤其是在无法访问生产数据时。
📝 摘要(中文)
在工业环境中,对高保真测试数据的需求至关重要,但通常难以访问生产数据。传统数据生成方法常常不足,难以模拟复杂的数据结构和语义关系,这对于测试复杂的SQL代码生成服务(如NL2SQL)至关重要。本文针对Google工作负载中常见的包含嵌套结构的复杂数据结构,提出了生成语法正确且语义相关的高保真模拟数据的需求。我们强调了现有生产方法的局限性,特别是它们处理大型复杂数据结构的能力不足,以及缺乏语义连贯的测试数据,导致测试覆盖率有限。我们证明,通过利用大型语言模型(LLM)并结合策略性的预处理和后处理步骤,我们可以生成语法正确且语义相关的高保真测试数据,这些数据遵循复杂的结构约束,并保持与SQL测试目标(查询/函数)的语义完整性。这种方法支持对涉及连接、聚合甚至深度嵌套子查询的复杂SQL查询进行全面测试,确保对SQL代码生成服务(如NL2SQL和SQL代码助手)进行稳健的评估。我们的结果表明,基于LLM(gemini)的测试数据生成在工业SQL代码生成服务中具有实际效用,在这些服务中,由于频繁无法访问生产数据集进行测试,因此生成高保真测试数据至关重要。
🔬 方法详解
问题定义:论文旨在解决为Google SQL代码生成服务生成高保真、复杂测试数据的问题。现有方法在处理大型、嵌套数据结构时存在困难,且生成的测试数据缺乏语义一致性,无法有效覆盖各种SQL查询场景,例如包含joins, aggregations, nested subqueries的复杂查询。
核心思路:核心思路是利用大型语言模型(LLM)的强大生成能力,通过精心设计的预处理和后处理步骤,生成既符合语法规则又具备语义相关性的测试数据。这种方法旨在克服传统数据生成方法的局限性,提供更全面、更真实的测试环境。
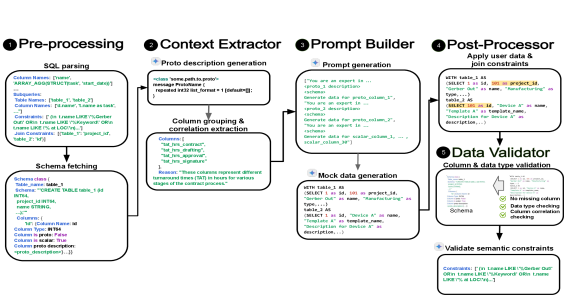
技术框架:该方法主要包含以下几个阶段:1) 数据模式定义:明确需要生成的数据表的结构,包括字段名、数据类型和约束。2) LLM提示工程:设计合适的提示语,引导LLM生成符合数据模式的初始数据。3) 预处理:对LLM的输入进行处理,例如提供数据字典、示例数据等,以提高生成数据的质量。4) LLM生成:使用LLM生成初始测试数据。5) 后处理:对LLM生成的测试数据进行验证和修正,确保其符合语法规则和语义约束。
关键创新:关键创新在于将大型语言模型(LLM)应用于SQL测试数据的生成,并结合预处理和后处理步骤来提高生成数据的质量和保真度。与传统方法相比,该方法能够更好地处理复杂的数据结构和语义关系,生成更具挑战性的测试用例。
关键设计:论文中使用了Google的LLM模型gemini,并针对SQL数据生成任务进行了微调。预处理阶段可能包括提供数据模式、示例数据、以及数据字典等信息。后处理阶段则包括语法检查、语义一致性验证、以及数据清洗等步骤。具体的损失函数和网络结构等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片

📊 实验亮点
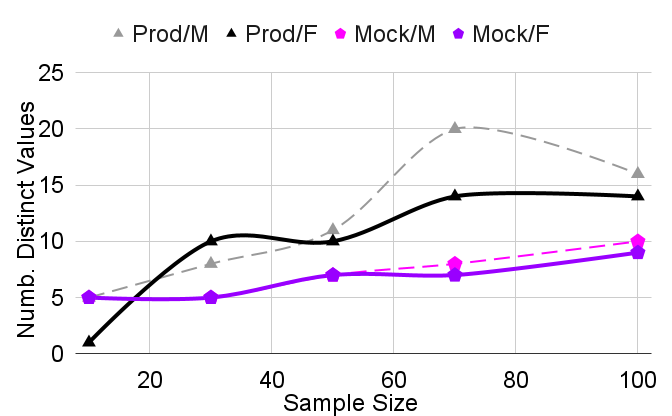
论文展示了利用gemini模型生成高保真测试数据的有效性,但摘要中没有提供具体的性能指标或对比基线。因此,无法量化该方法带来的具体提升幅度。实验结果表明,该方法在工业SQL代码生成服务中具有实际应用价值。
🎯 应用场景
该研究成果可广泛应用于各种SQL代码生成服务的测试和评估,例如NL2SQL系统、SQL代码助手等。通过生成高质量的测试数据,可以更全面地评估这些服务的性能和鲁棒性,提高其在实际应用中的可靠性。此外,该方法还可以应用于数据库模式演化、数据质量评估等领域。
📄 摘要(原文)
The demand for high-fidelity test data is paramount in industrial settings where access to production data is largely restricted. Traditional data generation methods often fall short, struggling with low-fidelity and the ability to model complex data structures and semantic relationships that are critical for testing complex SQL code generation services like Natural Language to SQL (NL2SQL). In this paper, we address the critical need for generating syntactically correct and semantically relevant high-fidelity mock data for complex data structures that includes columns with nested structures that we frequently encounter in Google workloads. We highlight the limitations of existing approaches used in production, particularly their inability to handle large and complex data structures, as well as the lack of semantically coherent test data that lead to limited test coverage. We demonstrate that by leveraging Large Language Models (LLMs) and incorporating strategic pre- and post-processing steps, we can generate syntactically correct and semantically relevant high-fidelity test data that adheres to complex structural constraints and maintains semantic integrity to the SQL test targets (queries/functions). This approach supports comprehensive testing of complex SQL queries involving joins, aggregations, and even deeply nested subqueries, ensuring robust evaluation of SQL code generation services, like NL2SQL and SQL Code Assistant. Our results demonstrate the practical utility of an LLM (\textit{gemini}) based test data generation for industrial SQL code generation services where generating high-fidelity test data is essential due to the frequent unavailability and inaccessibility of production datasets for testing.