Process Reward Models That Think
作者: Muhammad Khalifa, Rishabh Agarwal, Lajanugen Logeswaran, Jaekyeom Kim, Hao Peng, Moontae Lee, Honglak Lee, Lu Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-23 (更新: 2025-12-08)
备注: Add new ablation and minor writing fixes
🔗 代码/项目: GITHUB
💡 一句话要点
提出ThinkPRM:一种数据高效的生成式过程奖励模型,用于提升测试时推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 思维链 生成式模型 数据高效学习 语言模型推理
📋 核心要点
- 现有过程奖励模型(PRM)训练成本高昂,因为它们需要大量的步骤级监督数据。
- ThinkPRM通过生成验证性的思维链(CoT)来验证解决方案的每一步,从而实现数据高效的训练。
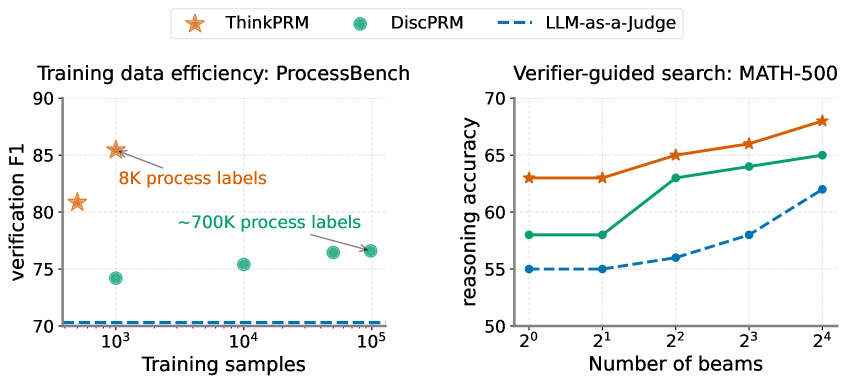
- ThinkPRM在多个基准测试中优于LLM-as-a-Judge和判别式验证器,同时仅使用少量过程标签。
📝 摘要(中文)
本文提出ThinkPRM,一种数据高效的过程奖励模型(PRM),它通过生成验证性的思维链(CoT)来验证解决方案中的每一步。与判别式PRM相比,ThinkPRM作为一种口头化的逐步奖励模型,在训练时所需的步骤级监督数据量级要小得多。该方法利用了长CoT模型固有的推理能力,并在多个具有挑战性的基准测试中优于LLM-as-a-Judge和判别式验证器,而使用的过程标签仅为PRM800K的1%。具体而言,ThinkPRM在ProcessBench、MATH-500和AIME '24上,通过best-of-N选择和奖励引导搜索,均超越了基线模型。在GPQA-Diamond和LiveCodeBench的领域外评估中,ThinkPRM超过了在完整PRM800K上训练的判别式验证器,分别提升了8%和4.5%。最后,在相同的token预算下,ThinkPRM比LLM-as-a-Judge更有效地扩展了验证计算,在ProcessBench的一个子集上超过了它7.2%。这项工作突出了生成式长CoT PRM的价值,它可以在测试时扩展验证计算,同时只需要最少的训练监督。
🔬 方法详解
问题定义:论文旨在解决过程奖励模型(PRM)训练数据需求量大的问题。现有的判别式PRM需要大量的步骤级标注数据,这使得训练成本非常高昂,限制了其应用范围。因此,如何构建数据高效的PRM是一个重要的研究问题。
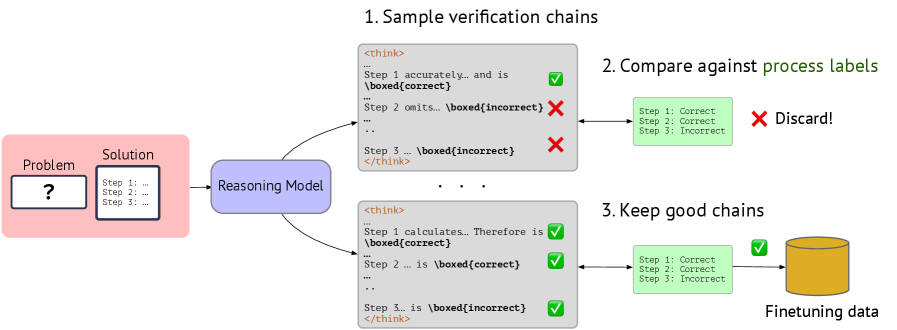
核心思路:论文的核心思路是利用大型语言模型(LLM)的固有推理能力,通过生成验证性的思维链(CoT)来评估解决方案的每一步。这种方法将PRM建模为一个生成式模型,而不是判别式模型,从而大大减少了对步骤级标注数据的需求。通过让模型生成CoT,可以更深入地理解解决方案的推理过程,并提供更准确的奖励信号。
技术框架:ThinkPRM的技术框架主要包括以下几个阶段:1) 给定一个问题和候选解决方案;2) ThinkPRM生成一个详细的CoT,逐步验证解决方案的正确性;3) 基于生成的CoT,ThinkPRM为解决方案的每一步分配奖励;4) 使用奖励引导搜索或best-of-N选择来选择最佳解决方案。整个框架依赖于一个经过微调的长CoT模型,该模型能够生成高质量的验证性CoT。
关键创新:ThinkPRM的关键创新在于其生成式的PRM设计。与传统的判别式PRM相比,ThinkPRM不需要大量的步骤级标注数据,而是通过利用LLM的推理能力来生成验证性的CoT。这种方法不仅降低了训练成本,还提高了模型的泛化能力。此外,ThinkPRM还能够提供更细粒度的奖励信号,从而更好地指导解决方案的搜索过程。
关键设计:ThinkPRM的关键设计包括:1) 使用长CoT模型作为生成器,确保模型能够生成详细且连贯的验证性CoT;2) 使用少量步骤级标注数据对长CoT模型进行微调,使其适应特定的任务;3) 设计合适的奖励函数,鼓励模型生成高质量的验证性CoT;4) 使用奖励引导搜索或best-of-N选择来选择最佳解决方案。具体的参数设置和网络结构细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
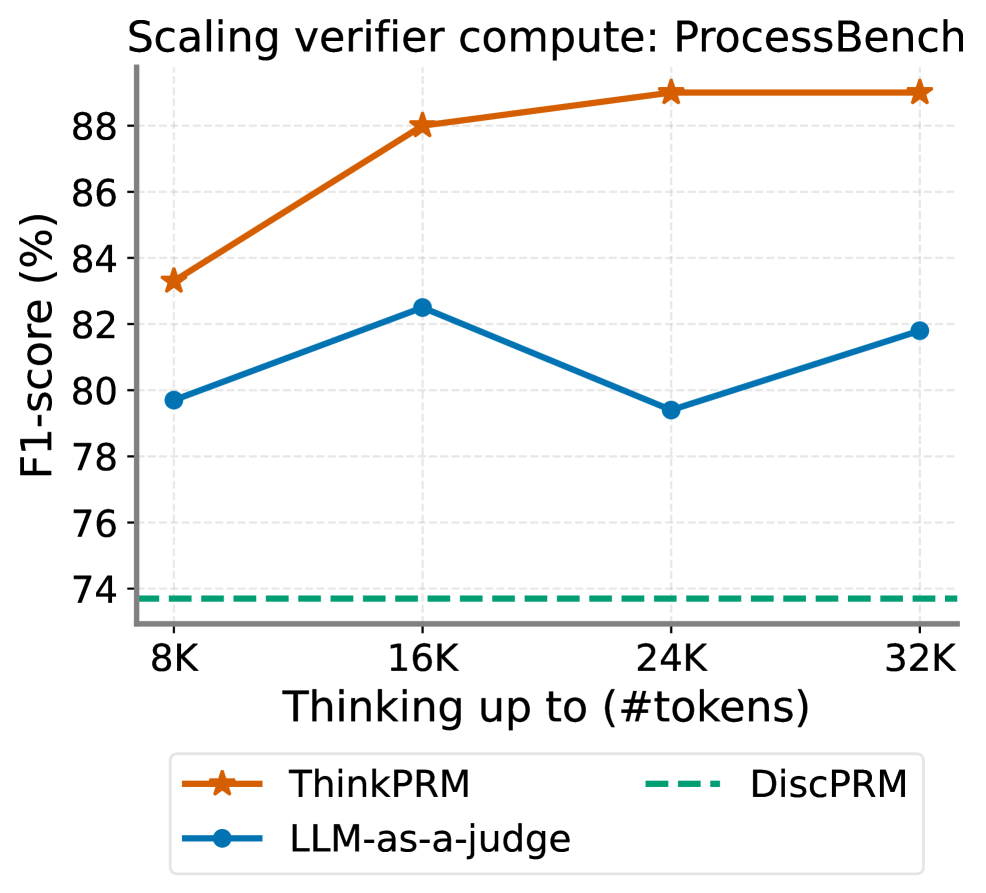
ThinkPRM在ProcessBench、MATH-500和AIME '24等基准测试中,使用仅为PRM800K 1% 的过程标签,超越了LLM-as-a-Judge和判别式验证器。在GPQA-Diamond和LiveCodeBench的领域外评估中,ThinkPRM超过了在完整PRM800K上训练的判别式验证器,分别提升了8%和4.5%。在ProcessBench的一个子集上,ThinkPRM比LLM-as-a-Judge的性能提升了7.2%。
🎯 应用场景
ThinkPRM可应用于各种需要逐步验证和推理的场景,例如数学问题求解、代码生成、科学推理等。该方法可以降低训练成本,提高模型在资源受限环境下的性能,并促进AI系统在复杂任务中的应用。
📄 摘要(原文)
Step-by-step verifiers -- also known as process reward models (PRMs) -- are a key ingredient for test-time scaling. PRMs require step-level supervision, making them expensive to train. This work aims to build data-efficient PRMs as verbalized step-wise reward models that verify every step in the solution by generating a verification chain-of-thought (CoT). We propose ThinkPRM, a long CoT verifier fine-tuned on orders of magnitude fewer process labels than those required by discriminative PRMs. Our approach capitalizes on the inherent reasoning abilities of long CoT models, and outperforms LLM-as-a-Judge and discriminative verifiers -- using only 1% of the process labels in PRM800K -- across several challenging benchmarks. Specifically, ThinkPRM beats the baselines on ProcessBench, MATH-500, and AIME '24 under best-of-N selection and reward-guided search. In an out-of-domain evaluation on a subset of GPQA-Diamond and LiveCodeBench, our PRM surpasses discriminative verifiers trained on the full PRM800K by 8% and 4.5%, respectively. Lastly, under the same token budget, ThinkPRM scales up verification compute more effectively compared to LLM-as-a-Judge, outperforming it by 7.2% on a subset of ProcessBench. Our work highlights the value of generative, long CoT PRMs that can scale test-time compute for verification while requiring minimal supervision for training. Our code, data, and models are released at https://github.com/mukhal/thinkprm.