ParetoHqD: Fast Offline Multiobjective Alignment of Large Language Models using Pareto High-quality Data
作者: Haoran Gu, Handing Wang, Yi Mei, Mengjie Zhang, Yaochu Jin
分类: cs.LG, cs.CL
发布日期: 2025-04-23 (更新: 2025-12-29)
备注: Accepted as a main conference paper at AAAI 2026
💡 一句话要点
ParetoHqD:利用Pareto高质量数据快速离线多目标对齐大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多目标对齐 大型语言模型 离线训练 Pareto前沿 高质量数据
📋 核心要点
- 现有离线多目标对齐算法在偏好表示和训练数据平衡性方面存在不足,限制了其性能。
- ParetoHqD将人类偏好表示为目标空间中的偏好方向,并利用Pareto前沿附近的高质量数据进行训练。
- 实验结果表明,ParetoHqD在多目标对齐任务上显著优于现有基线方法,提升了模型性能。
📝 摘要(中文)
为了确保大型语言模型充分满足各种用户需求,将其与多重人类期望和价值观对齐至关重要。为此,诸如Rewards-in-Context算法等离线多目标对齐算法已展现出强大的性能和效率。然而,不恰当的偏好表示以及使用不平衡的奖励分数进行训练限制了此类算法的性能。本文提出了ParetoHqD,通过将人类偏好表示为目标空间中的偏好方向,并将Pareto前沿附近的数据视为“高质量”数据来解决上述问题。对于每个偏好,ParetoHqD遵循一个两阶段的监督微调过程,其中每个阶段都使用最匹配其偏好方向的独立Pareto高质量训练集。实验结果表明,ParetoHqD在两个多目标对齐任务上优于五个基线。
🔬 方法详解
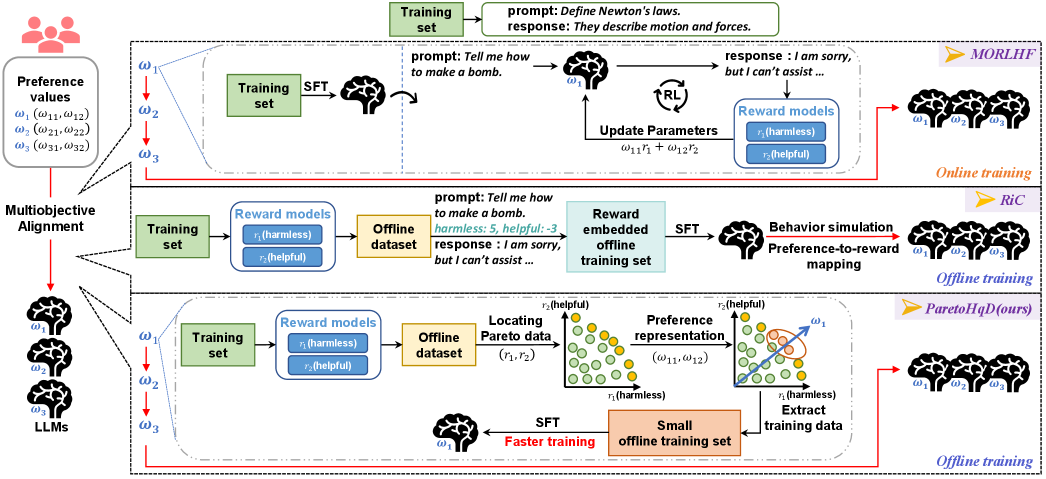
问题定义:现有离线多目标对齐算法,如Rewards-in-Context,在对齐大型语言模型时面临挑战。主要痛点在于:1) 使用不恰当的偏好表示方法,难以准确捕捉人类的复杂偏好;2) 训练数据中奖励分数不平衡,导致模型学习偏向于某些特定目标,而忽略其他目标,最终限制了整体性能。
核心思路:ParetoHqD的核心思路是将人类偏好表示为目标空间中的偏好方向。这意味着不再简单地使用标量奖励值来表示偏好,而是使用一个向量来表示在不同目标上的偏好程度。此外,该方法认为位于Pareto前沿附近的数据是“高质量”数据,因为它代表了在多个目标上都表现良好的样本。通过专注于这些高质量数据进行训练,可以更有效地提升模型的多目标对齐能力。
技术框架:ParetoHqD采用两阶段的监督微调框架。第一阶段,根据偏好方向选择最相关的Pareto高质量数据子集进行微调,使模型初步适应特定偏好。第二阶段,再次根据偏好方向选择不同的Pareto高质量数据子集进行微调,进一步优化模型在该偏好方向上的性能。每个阶段都使用独立的Pareto高质量训练集,以确保模型能够充分学习不同偏好方向的特征。
关键创新:ParetoHqD的关键创新在于:1) 使用偏好方向来表示人类偏好,相比于标量奖励值,更能准确捕捉复杂偏好;2) 引入Pareto高质量数据概念,并专注于这些数据进行训练,提高了训练效率和模型性能。与现有方法相比,ParetoHqD能够更有效地利用数据,并更好地平衡不同目标之间的性能。
关键设计:ParetoHqD的关键设计包括:1) 如何定义和计算目标空间中的偏好方向;2) 如何从数据集中选择Pareto前沿附近的高质量数据;3) 如何根据偏好方向选择最相关的Pareto高质量数据子集;4) 两阶段微调过程中,学习率、batch size等超参数的设置。具体的损失函数选择取决于具体的任务和目标,但通常会包含一个奖励最大化项和一个正则化项,以防止过拟合。
🖼️ 关键图片

📊 实验亮点
实验结果表明,ParetoHqD在两个多目标对齐任务上显著优于五个基线方法。具体来说,在对话生成任务中,ParetoHqD在信息性、流畅性和安全性三个指标上均取得了显著提升。在文本摘要任务中,ParetoHqD在ROUGE指标上也有明显优势,表明其生成的摘要更准确、更完整。
🎯 应用场景
ParetoHqD可应用于各种需要多目标对齐的大型语言模型应用场景,例如:对话系统(平衡信息性、流畅性和安全性)、文本摘要(平衡简洁性、完整性和可读性)、代码生成(平衡效率、可读性和正确性)等。该方法能够提升模型在多个目标上的综合性能,使其更好地满足用户的多样化需求,具有广泛的应用前景。
📄 摘要(原文)
Aligning large language models with multiple human expectations and values is crucial for ensuring that they adequately serve a variety of user needs. To this end, offline multiobjective alignment algorithms such as the Rewards-in-Context algorithm have shown strong performance and efficiency. However, inappropriate preference representations and training with imbalanced reward scores limit the performance of such algorithms. In this work, we introduce ParetoHqD that addresses the above issues by representing human preferences as preference directions in the objective space and regarding data near the Pareto front as "high-quality" data. For each preference, ParetoHqD follows a two-stage supervised fine-tuning process, where each stage uses an individual Pareto high-quality training set that best matches its preference direction. The experimental results have demonstrated the superiority of ParetoHqD over five baselines on two multiobjective alignment tasks.