In-context Ranking Preference Optimization
作者: Junda Wu, Rohan Surana, Zhouhang Xie, Yiran Shen, Yu Xia, Tong Yu, Ryan A. Rossi, Prithviraj Ammanabrolu, Julian McAuley
分类: cs.LG
发布日期: 2025-04-21 (更新: 2025-09-06)
备注: 10 pages
💡 一句话要点
提出IRPO框架,通过上下文排序偏好优化LLM,提升排序任务性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 排序偏好优化 直接偏好优化 大型语言模型 信息检索
📋 核心要点
- 现有方法在上下文排序中面临反馈稀疏和成对比较不足的挑战,难以有效优化LLM。
- IRPO框架通过结合项目相关性和位置信息,扩展DPO目标,实现基于排序列表的直接优化。
- IRPO在排序性能上优于标准DPO方法,验证了其在上下文排序偏好对齐方面的有效性。
📝 摘要(中文)
直接偏好优化(DPO)的最新进展使大型语言模型(LLM)能够通过最大化首选响应和非首选响应之间的裕度来充当隐式排序模型。实际上,用户对此类列表的反馈通常涉及识别上下文中一些相关的项目,而不是为每个可能的项目对提供详细的成对比较。此外,许多复杂的信息检索任务,如对话代理和摘要系统,关键在于将最高质量的输出排在首位,这突出了支持自然和灵活的用户反馈形式的需求。为了解决上下文环境中有限且稀疏的成对反馈的挑战,我们提出了一种上下文排序偏好优化(IRPO)框架,该框架直接基于推理期间构建的排序列表来优化LLM。为了进一步捕获灵活的反馈形式,IRPO通过结合项目相关性和它们在列表中的位置来扩展DPO目标。联合建模这些方面并非易事,因为排序指标本质上是离散且不可微的,这使得直接优化变得困难。为了克服这个问题,IRPO引入了一种基于成对项目偏好的位置聚合的可微目标,从而能够对离散排序指标进行有效的基于梯度的优化。我们进一步提供了理论见解,表明IRPO (i) 自动强调模型和参考排序之间存在较大分歧的项目,以及 (ii) 将其梯度链接到重要性抽样估计器,从而产生具有降低方差的无偏估计器。经验结果表明,IRPO在排序性能方面优于标准DPO方法,突出了其在使LLM与直接上下文排序偏好对齐方面的有效性。
🔬 方法详解
问题定义:现有方法在利用用户对排序列表的反馈时,通常需要详细的成对比较,这在实际应用中是不现实的,因为用户通常只关注少量相关项目。此外,传统的DPO方法难以直接优化排序指标,因为它们是离散且不可微的。因此,如何利用有限且稀疏的反馈,有效地优化LLM的排序能力,是一个亟待解决的问题。
核心思路:IRPO的核心思路是直接基于推理过程中构建的排序列表来优化LLM,并结合项目相关性和位置信息,扩展DPO目标。通过引入可微的排序损失函数,实现对离散排序指标的有效优化。这种方法允许模型从更自然和灵活的用户反馈中学习,从而更好地对齐用户的排序偏好。
技术框架:IRPO框架主要包含以下几个阶段:1) LLM生成排序列表;2) 用户提供上下文反馈,指出相关项目及其位置;3) IRPO根据用户反馈,构建基于位置聚合的成对项目偏好;4) 利用可微的排序损失函数,对LLM进行梯度优化。整个框架通过迭代优化,使LLM的排序结果更符合用户的偏好。
关键创新:IRPO的关键创新在于:1) 提出了基于位置聚合的成对项目偏好,能够有效利用上下文信息;2) 引入了可微的排序损失函数,克服了离散排序指标难以直接优化的难题;3) 理论分析表明,IRPO能够自动强调模型和参考排序之间存在较大分歧的项目,并降低梯度估计的方差。
关键设计:IRPO的关键设计包括:1) 位置聚合函数的设计,用于将项目的位置信息融入到偏好建模中;2) 可微排序损失函数的选择,需要保证其能够有效地反映排序质量,并易于优化;3) 梯度优化算法的选择,需要考虑其收敛速度和稳定性。论文中具体使用了DPO的损失函数,并对其进行了扩展,使其能够处理排序列表和位置信息。
🖼️ 关键图片
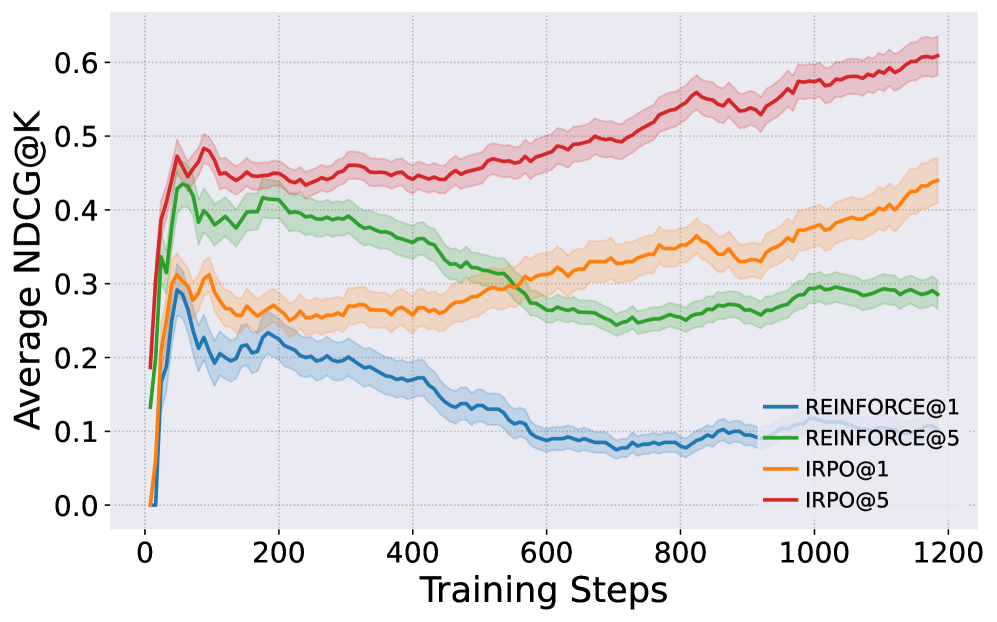


📊 实验亮点
实验结果表明,IRPO在排序性能方面显著优于标准DPO方法。具体来说,IRPO在多个数据集上取得了更高的NDCG和MAP指标,表明其能够更准确地对项目进行排序。此外,实验还验证了IRPO的理论分析,表明其能够自动强调模型和参考排序之间存在较大分歧的项目,并降低梯度估计的方差。
🎯 应用场景
IRPO框架可应用于各种需要排序的场景,如信息检索、推荐系统、对话系统和文本摘要等。通过利用用户的上下文反馈,IRPO能够提升LLM在这些任务中的排序性能,从而提高用户满意度和系统效率。未来,IRPO还可以扩展到更复杂的排序任务,如多目标排序和个性化排序。
📄 摘要(原文)
Recent developments in Direct Preference Optimization (DPO) allow large language models (LLMs) to function as implicit ranking models by maximizing the margin between preferred and non-preferred responses. In practice, user feedback on such lists typically involves identifying a few relevant items in context rather than providing detailed pairwise comparisons for every possible item pair. Moreover, many complex information retrieval tasks, such as conversational agents and summarization systems, critically depend on ranking the highest-quality outputs at the top, emphasizing the need to support natural and flexible forms of user feedback. To address the challenge of limited and sparse pairwise feedback in the in-context setting, we propose an In-context Ranking Preference Optimization (IRPO) framework that directly optimizes LLMs based on ranking lists constructed during inference. To further capture flexible forms of feedback, IRPO extends the DPO objective by incorporating both the relevance of items and their positions in the list. Modeling these aspects jointly is non-trivial, as ranking metrics are inherently discrete and non-differentiable, making direct optimization difficult. To overcome this, IRPO introduces a differentiable objective based on positional aggregation of pairwise item preferences, enabling effective gradient-based optimization of discrete ranking metrics. We further provide theoretical insights showing that IRPO (i) automatically emphasizes items with greater disagreement between the model and the reference ranking, and (ii) links its gradient to an importance sampling estimator, yielding an unbiased estimator with reduced variance. Empirical results show IRPO outperforms standard DPO approaches in ranking performance, highlighting its effectiveness in aligning LLMs with direct in-context ranking preferences.