Combating Toxic Language: A Review of LLM-Based Strategies for Software Engineering
作者: Hao Zhuo, Yicheng Yang, Kewen Peng
分类: cs.LG, cs.SE
发布日期: 2025-04-21 (更新: 2026-01-20)
💡 一句话要点
综述:基于LLM的软件工程有毒语言检测与缓解策略
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 有毒语言检测 大型语言模型 软件工程 毒性缓解 自然语言处理
📋 核心要点
- 软件工程中LLM的应用面临有毒语言传播的风险,可能导致排斥性环境。
- 该综述聚焦于利用LLM进行有毒语言检测与缓解的策略,包括标注、检测和重写等技术。
- 通过消融实验验证了基于LLM的重写技术在降低文本毒性方面的有效性,为未来研究指明方向。
📝 摘要(中文)
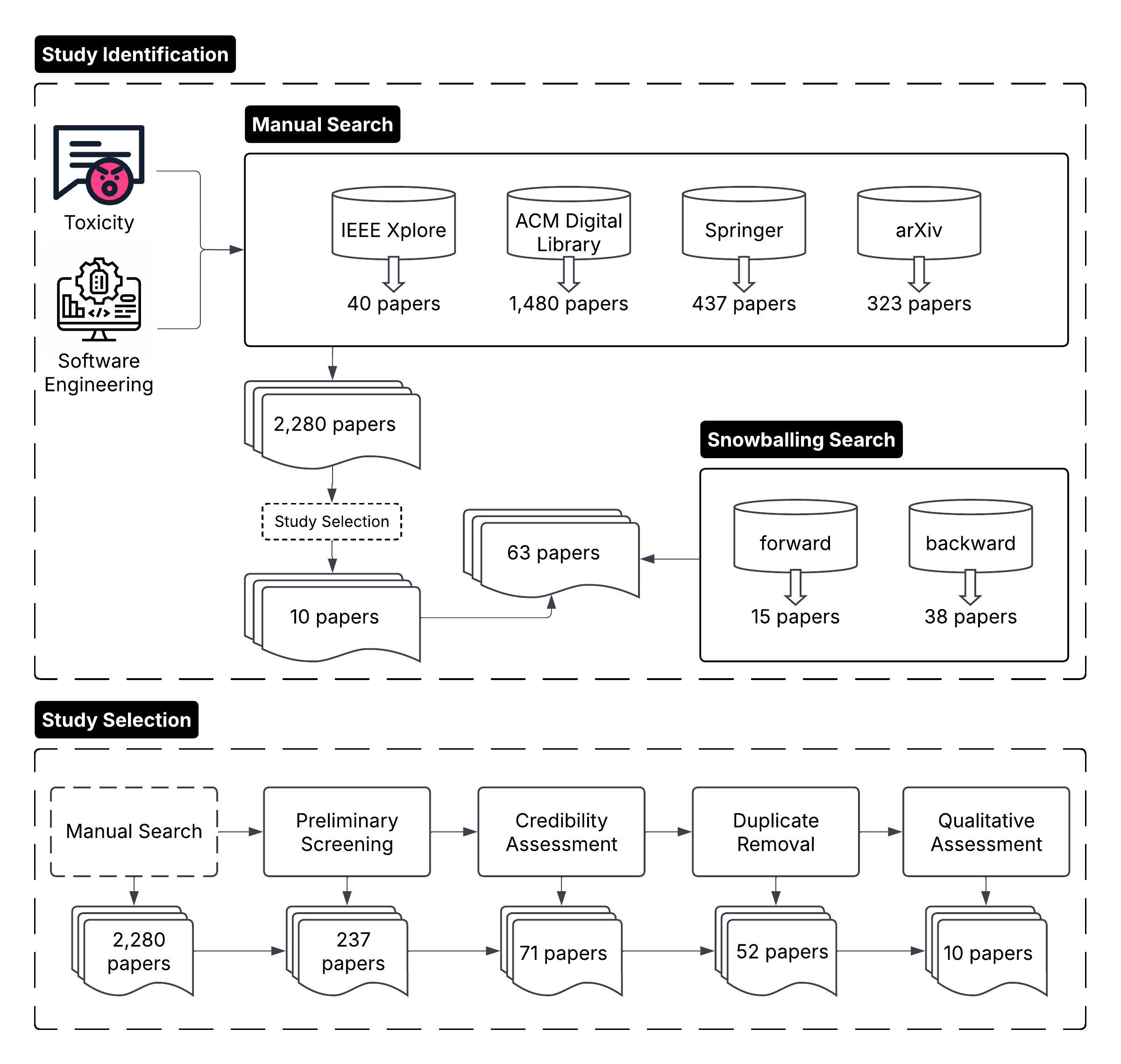
大型语言模型(LLM)已成为软件工程(SE)不可或缺的一部分,并日益广泛地应用于开发工作流程中。然而,它们的广泛采用引发了对有毒语言(可能助长排斥环境的有害或冒犯性内容)的存在和传播的担忧。本文全面回顾了2020-2024年关于毒性检测和缓解的最新研究,重点关注SE特定和通用数据集。我们考察了标注和预处理技术,评估了检测方法,并评估了缓解策略,特别是那些利用LLM的策略。此外,我们进行了一项消融研究,证明了基于LLM的重写在降低毒性方面的有效性。本综述仅限于指定时间范围内以及LLM和SE中毒性领域内发表的研究;因此,某些超出此期限的新兴方法或数据集可能不在其范围内。通过综合现有工作并识别未解决的挑战,本综述强调了未来研究的关键领域,以确保LLM在SE及其他领域中的负责任部署。
🔬 方法详解
问题定义:论文旨在解决软件工程领域中,大型语言模型(LLM)在应用过程中产生的有毒语言问题。现有方法在检测和缓解这些有毒语言方面存在不足,尤其是在软件工程特定场景下,通用方法可能无法达到理想效果。此外,如何有效地利用LLM自身的能力来对抗有毒语言也是一个挑战。
核心思路:论文的核心思路是对现有基于LLM的有毒语言检测与缓解策略进行系统性的梳理和分析,并结合软件工程领域的特点,探讨如何更有效地利用LLM来解决该问题。通过对现有方法的分类、评估和实验验证,为未来的研究提供指导。
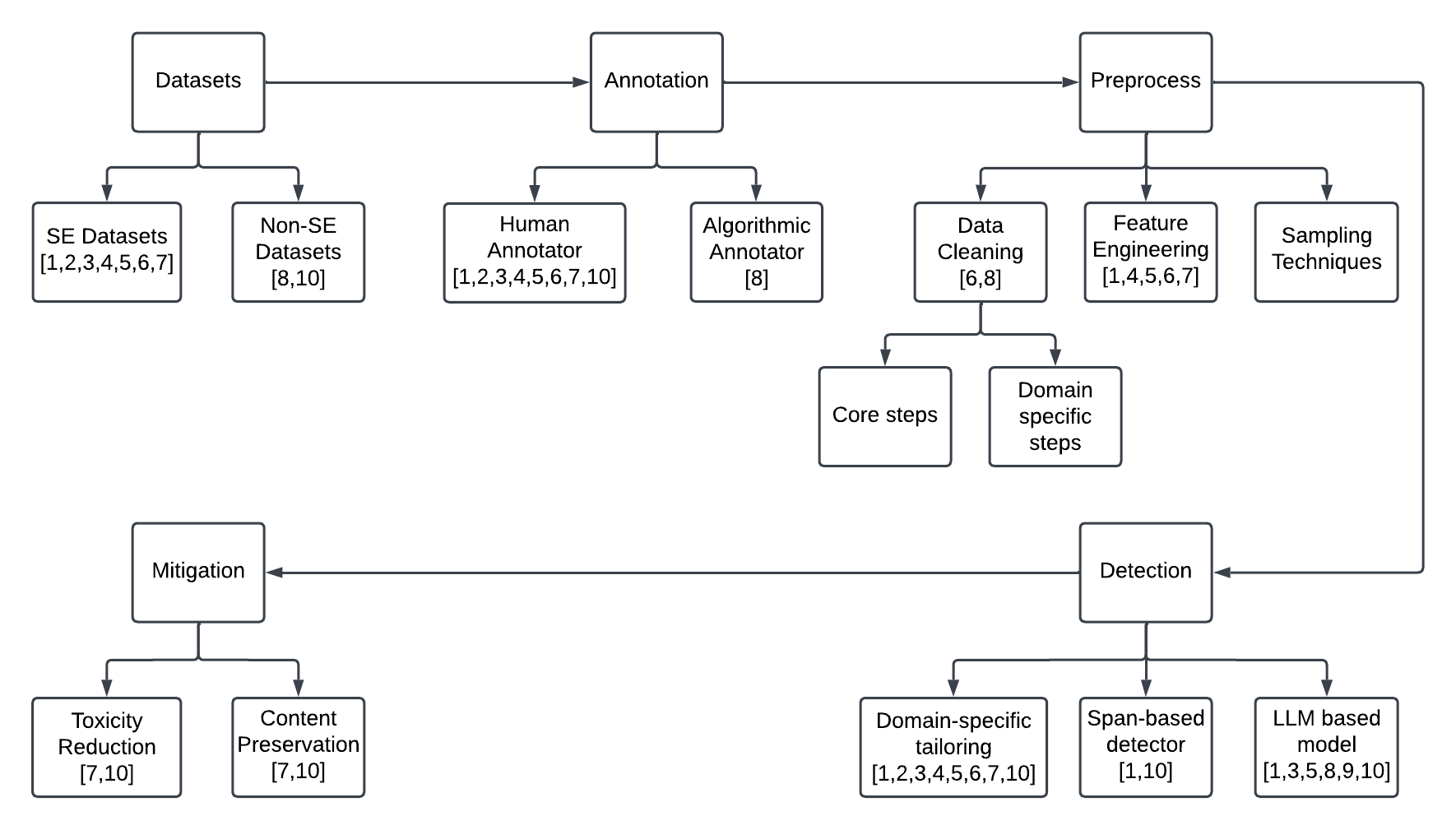
技术框架:该综述的技术框架主要包括三个方面:1) 有毒语言的标注与预处理技术;2) 基于LLM的有毒语言检测方法;3) 基于LLM的有毒语言缓解策略。文章首先对相关数据集进行分析,然后对各类检测和缓解方法进行详细的介绍和比较,最后通过实验验证LLM在缓解毒性方面的效果。
关键创新:该综述的关键创新在于其系统性地总结了基于LLM的有毒语言检测与缓解策略在软件工程领域的应用,并进行了实验验证。它不仅关注通用的方法,还特别关注了软件工程特定场景下的应用,为该领域的研究提供了有价值的参考。
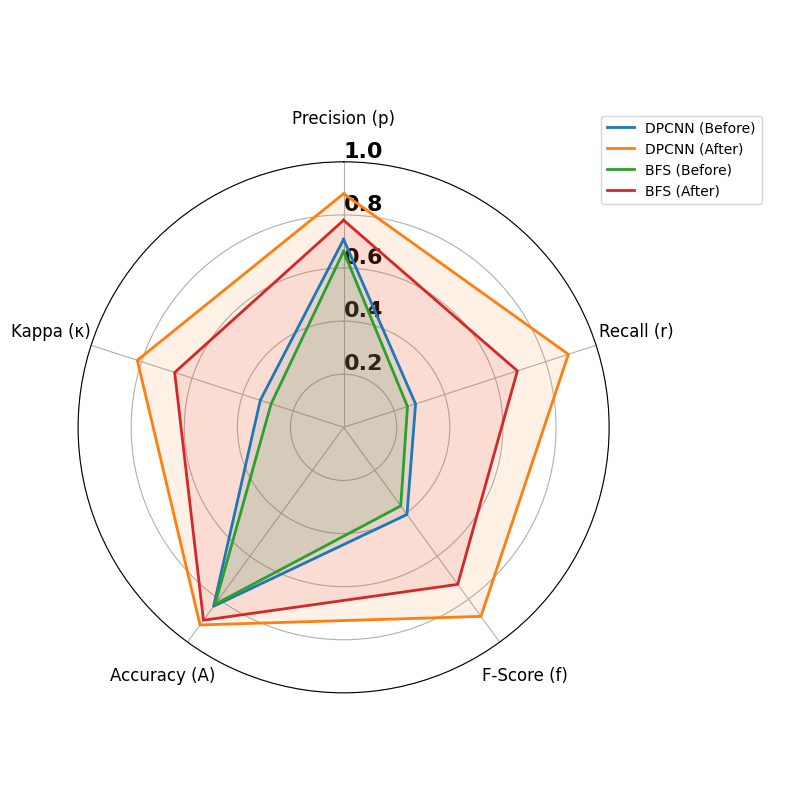
关键设计:论文的关键设计在于其消融实验,该实验旨在验证基于LLM的重写技术在降低文本毒性方面的有效性。通过对比不同重写策略的效果,可以评估LLM在缓解毒性方面的能力,并为未来的研究提供指导。具体的实验细节(如数据集、评估指标等)在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
该综述通过消融实验证明了基于LLM的重写技术在降低文本毒性方面的有效性。具体的性能数据和提升幅度在论文中进行了详细描述。实验结果表明,通过合理地利用LLM,可以有效地减少软件工程领域中的有毒语言。
🎯 应用场景
该研究成果可应用于各种软件工程场景,例如代码审查、缺陷报告、在线讨论等,以减少有毒语言的传播,营造更积极、包容的开发环境。此外,该研究也为其他领域(如社交媒体、在线教育等)利用LLM对抗有毒语言提供了借鉴。
📄 摘要(原文)
Large Language Models (LLMs) have become integral to Software Engineering (SE), increasingly used in development workflows. However, their widespread adoption raises concerns about the presence and propagation of toxic language - harmful or offensive content that can foster exclusionary environments. This paper provides a comprehensive review of recent research (2020-2024) on toxicity detection and mitigation, focusing on both SE-specific and general-purpose datasets. We examine annotation and pre-processing techniques, assess detection methodologies, and evaluate mitigation strategies, particularly those leveraging LLMs. Additionally, we conduct an ablation study demonstrating the effectiveness of LLM-based rewriting for reducing toxicity. This review is limited to studies published within the specified timeframe and within the domain of toxicity in LLMs and SE; therefore, certain emerging methods or datasets beyond this period may fall outside its purview. By synthesizing existing work and identifying open challenges, this review highlights key areas for future research to ensure the responsible deployment of LLMs in SE and beyond.