Scaling and Beyond: Advancing Spatial Reasoning in MLLMs Requires New Recipes
作者: Huanyu Zhang, Chengzu Li, Wenshan Wu, Shaoguang Mao, Yifan Zhang, Haochen Tian, Ivan Vulić, Zhang Zhang, Liang Wang, Tieniu Tan, Furu Wei
分类: cs.LG
发布日期: 2025-04-21 (更新: 2025-06-03)
💡 一句话要点
MLLM空间推理能力不足,需变革现有架构与训练方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 空间推理 视觉语言 人工智能 机器人 模型架构 训练方法
📋 核心要点
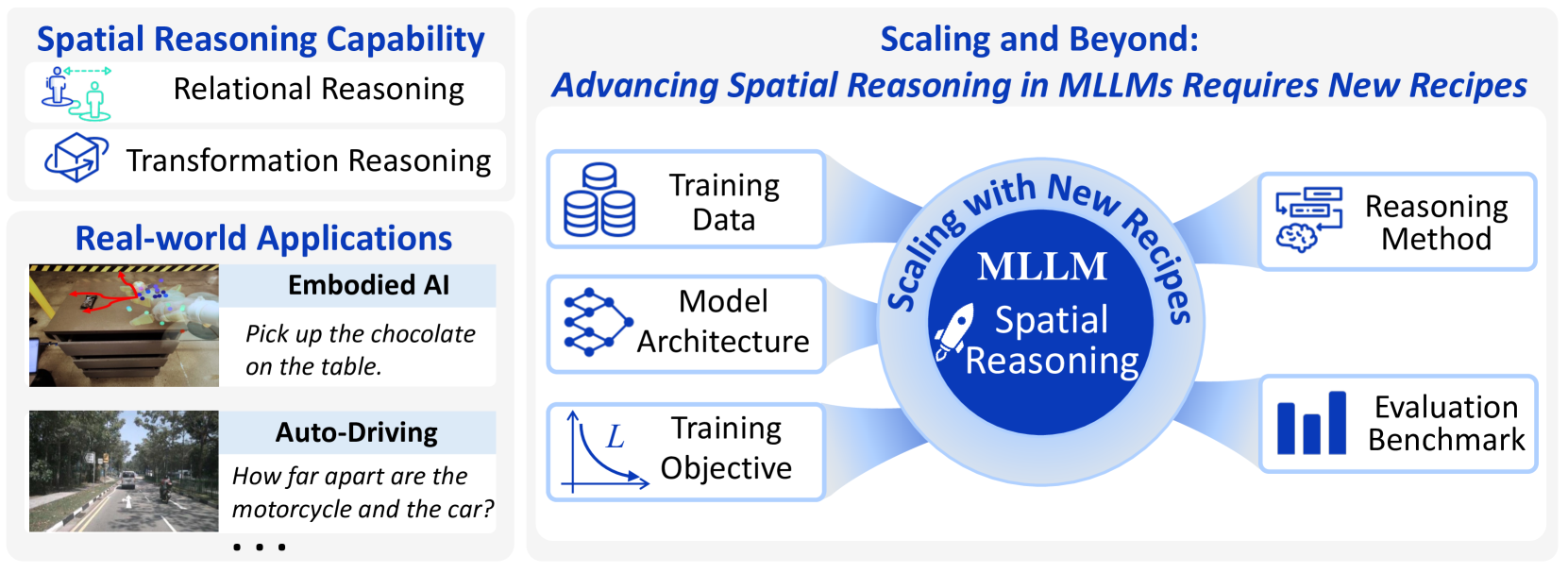
- 现有MLLM在空间推理方面存在明显不足,严重限制了其在现实世界中的应用潜力。
- 论文提出不能仅靠扩大模型规模来提升空间推理能力,需要从根本上修改 MLLM 的架构和训练方法。
- 论文构建了 MLLM 空间推理的综合框架,并分析了现有方法在数据、机制等方面的影响与局限。
📝 摘要(中文)
多模态大型语言模型(MLLM)在通用视觉-语言任务中表现出色,但其空间推理能力存在严重局限性。这种缺陷限制了MLLM与物理世界的有效交互,从而制约了其更广泛的应用。本文认为,仅仅通过扩展现有架构和训练方法无法自然地提升空间推理能力。因此,需要对当前的MLLM开发方法进行根本性修改。本文首先建立了MLLM空间推理的综合框架,阐述了其在实际应用中的关键作用。通过系统分析,我们考察了当前方法(从训练数据到推理机制)的各个组成部分如何影响空间推理能力,揭示了关键局限性,并确定了有希望的改进途径。我们的工作旨在引导AI研究界关注这些关键但未被充分探索的方面,从而促进MLLM实现类人空间推理能力。
🔬 方法详解
问题定义:论文关注的是多模态大型语言模型(MLLMs)在空间推理能力上的不足。现有方法,如简单地扩大模型规模和使用通用视觉-语言训练数据,并不能有效提升 MLLMs 的空间推理能力。这导致 MLLMs 难以理解和操作物理世界,限制了其在机器人、自动驾驶等领域的应用。
核心思路:论文的核心思路是认为空间推理能力并非可以通过简单的模型放大而自然涌现,而是需要针对性地设计新的架构和训练方法。这意味着需要更精细地控制训练数据,设计更有效的推理机制,并可能需要引入新的模型组件来专门处理空间信息。
技术框架:论文构建了一个用于分析 MLLM 空间推理能力的框架,该框架涵盖了训练数据、模型架构、推理机制等多个方面。通过这个框架,论文系统性地分析了现有方法在各个环节上的局限性,并提出了改进方向。虽然论文没有提出一个具体的模型架构,但它为未来的研究提供了一个分析和改进 MLLM 空间推理能力的蓝图。
关键创新:论文的关键创新在于它明确指出了当前 MLLM 发展路径在空间推理能力上的瓶颈,并强调了变革现有方法的重要性。它打破了“越大越好”的传统观念,呼吁研究者关注更根本性的问题,例如如何更好地表示和处理空间信息。
关键设计:论文并没有提出具体的参数设置或网络结构,而是侧重于对现有方法的分析和对未来方向的展望。它强调了训练数据的重要性,认为需要设计更符合空间推理需求的训练数据。同时,它也指出需要探索新的推理机制,例如引入符号推理或图推理等方法来增强 MLLMs 的空间推理能力。
🖼️ 关键图片
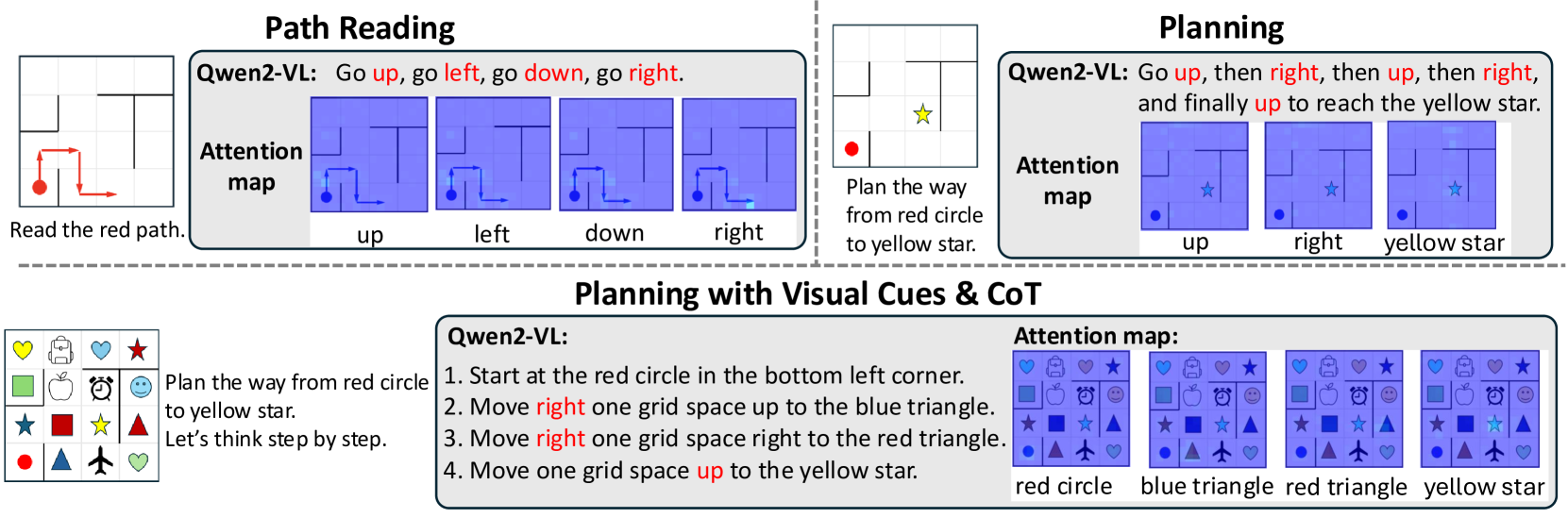
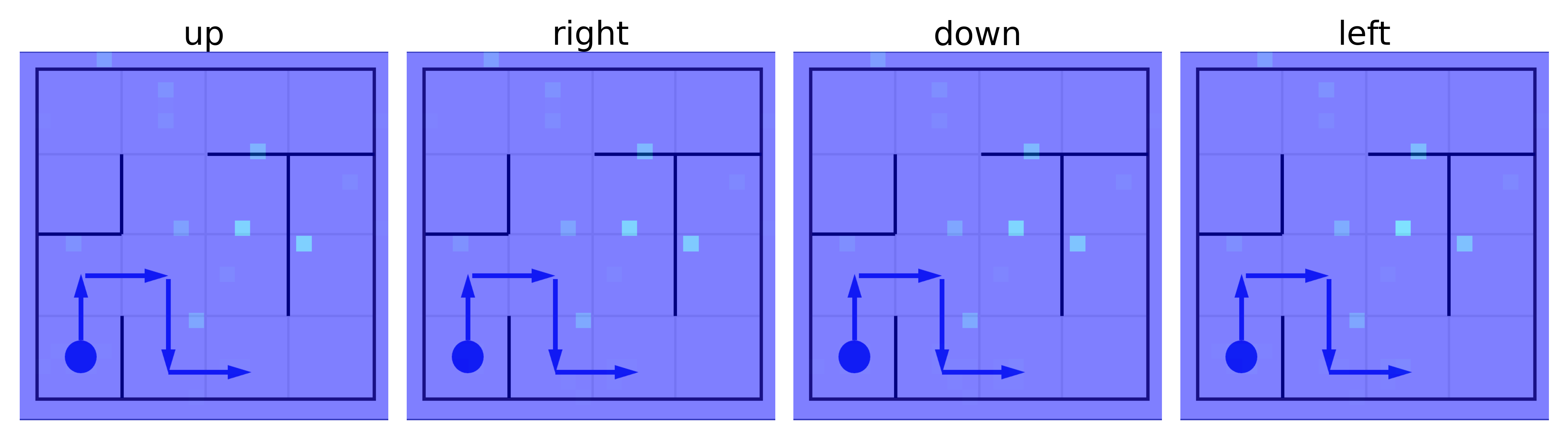
📊 实验亮点
该论文是一篇立场性文章,主要贡献在于对现有MLLM空间推理能力的不足进行了系统性分析,并指出了未来研究方向。它没有提供具体的实验结果,而是通过理论分析强调了变革现有方法的重要性,为后续研究提供了指导。
🎯 应用场景
该研究成果对机器人、自动驾驶、增强现实等领域具有重要意义。提升MLLM的空间推理能力,可以使机器人更好地理解和操作物理环境,提高自动驾驶系统的安全性和可靠性,并为AR应用提供更自然、更具交互性的体验。此外,该研究还有助于开发更智能的虚拟助手和游戏AI。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have demonstrated impressive performance in general vision-language tasks. However, recent studies have exposed critical limitations in their spatial reasoning capabilities. This deficiency in spatial reasoning significantly constrains MLLMs' ability to interact effectively with the physical world, thereby limiting their broader applications. We argue that spatial reasoning capabilities will not naturally emerge from merely scaling existing architectures and training methodologies. Instead, this challenge demands dedicated attention to fundamental modifications in the current MLLM development approach. In this position paper, we first establish a comprehensive framework for spatial reasoning within the context of MLLMs. We then elaborate on its pivotal role in real-world applications. Through systematic analysis, we examine how individual components of the current methodology, from training data to reasoning mechanisms, influence spatial reasoning capabilities. This examination reveals critical limitations while simultaneously identifying promising avenues for advancement. Our work aims to direct the AI research community's attention toward these crucial yet underexplored aspects. By highlighting these challenges and opportunities, we seek to catalyze progress toward achieving human-like spatial reasoning capabilities in MLLMs.