Deep Learning with Pretrained 'Internal World' Layers: A Gemma 3-Based Modular Architecture for Wildfire Prediction
作者: Ayoub Jadouli, Chaker El Amrani
分类: cs.LG, cs.AI
发布日期: 2025-04-20
💡 一句话要点
提出基于Gemma 3预训练“内部世界”层的模块化架构,用于野火预测。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 野火预测 深度学习 预训练模型 Transformer 模块化架构
📋 核心要点
- 现有野火预测方法在小数据集上容易过拟合,且难以有效利用大规模预训练模型的知识。
- 论文提出一种模块化架构,利用Gemma 3预训练模型的中间层作为“内部世界”,提取特征并进行预测。
- 实验表明,该方法在野火预测任务上优于传统方法,且消融实验验证了预训练层的有效性。
📝 摘要(中文)
本文提出了一种基于Gemma 3的模块化架构,利用深度学习模型中间层中蕴含的“内部世界”知识进行野火预测。该架构没有使用Gemma 3原始的嵌入和位置编码层,而是开发了一个自定义的前馈模块,将表格型野火特征转换为Gemma 3中间Transformer块所需的隐藏维度。冻结Gemma 3的这些子层,保留其预训练的表示能力,同时只训练较小的输入和输出网络。这种方法最大限度地减少了可训练参数的数量,降低了在有限的野火数据上过拟合的风险,同时保留了Gemma 3的广泛知识。在摩洛哥野火数据集上的评估表明,与标准前馈和卷积基线相比,预测精度和鲁棒性有所提高。消融研究证实,冻结的Transformer层始终有助于更好的表示,突出了重用大型模型中间层作为学习到的内部世界的可行性。研究结果表明,对预训练Transformer进行战略性的模块化重用,可以为野火风险管理等关键环境应用提供更高效和可解释的解决方案。
🔬 方法详解
问题定义:论文旨在解决野火预测问题,现有方法在数据量有限的情况下容易过拟合,并且难以有效利用大规模预训练模型的知识。传统的浅层模型表达能力有限,而直接训练大型深度学习模型又需要大量标注数据,这在野火预测领域是难以满足的。
核心思路:论文的核心思路是利用大型预训练模型(Gemma 3)的中间层作为“内部世界”,这些中间层已经学习了丰富的通用知识。通过将野火特征映射到这个“内部世界”的表示空间,可以有效地利用预训练模型的知识,同时避免从头开始训练整个模型,从而减少了过拟合的风险。
技术框架:整体架构包括三个主要模块:1) 特征转换模块:将表格型野火特征转换为Gemma 3中间层所需的隐藏维度表示;2) 冻结的Gemma 3中间Transformer块:利用预训练的Transformer块提取特征;3) 输出网络:将Transformer块的输出映射到野火发生的概率。整个流程是:输入野火特征 -> 特征转换 -> Gemma 3中间层特征提取 -> 输出预测。
关键创新:最重要的技术创新点在于将预训练模型的中间层视为一个可重用的“内部世界”,并设计了一个模块化的架构来利用这个“内部世界”的知识。与直接微调整个预训练模型或从头开始训练模型相比,该方法更加高效且不易过拟合。
关键设计:关键设计包括:1) 特征转换模块的设计,需要将表格型特征有效地映射到Transformer块的隐藏维度;2) Gemma 3中间层的选择,需要选择合适的层以获得最佳的表示能力;3) 冻结Gemma 3中间层的参数,只训练特征转换模块和输出网络,以减少可训练参数的数量。
🖼️ 关键图片


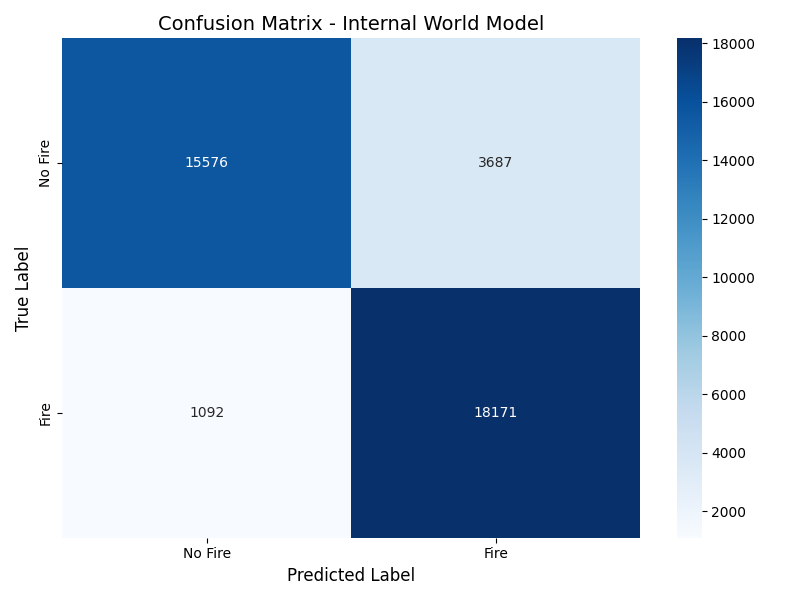
📊 实验亮点
实验结果表明,该方法在摩洛哥野火数据集上取得了优于传统前馈网络和卷积神经网络的预测精度。消融实验进一步验证了冻结的Transformer层对提升预测性能的贡献,证明了利用预训练模型中间层作为“内部世界”的有效性。具体性能提升数据未知,但整体表现优于基线模型。
🎯 应用场景
该研究成果可应用于野火风险评估与管理,帮助相关部门更准确地预测野火发生的概率,从而制定更有效的预防和应对措施。此外,该方法也为其他环境监测和预测任务提供了一种新的思路,即利用预训练模型的“内部世界”知识来解决数据量有限的问题,具有广泛的应用前景。
📄 摘要(原文)
Deep learning models, especially large Transformers, carry substantial "memory" in their intermediate layers -- an \emph{internal world} that encodes a wealth of relational and contextual knowledge. This work harnesses that internal world for wildfire occurrence prediction by introducing a modular architecture built upon Gemma 3, a state-of-the-art multimodal model. Rather than relying on Gemma 3's original embedding and positional encoding stacks, we develop a custom feed-forward module that transforms tabular wildfire features into the hidden dimension required by Gemma 3's mid-layer Transformer blocks. We freeze these Gemma 3 sub-layers -- thus preserving their pretrained representation power -- while training only the smaller input and output networks. This approach minimizes the number of trainable parameters and reduces the risk of overfitting on limited wildfire data, yet retains the benefits of Gemma 3's broad knowledge. Evaluations on a Moroccan wildfire dataset demonstrate improved predictive accuracy and robustness compared to standard feed-forward and convolutional baselines. Ablation studies confirm that the frozen Transformer layers consistently contribute to better representations, underscoring the feasibility of reusing large-model mid-layers as a learned internal world. Our findings suggest that strategic modular reuse of pretrained Transformers can enable more data-efficient and interpretable solutions for critical environmental applications such as wildfire risk management.