M-TabNet: A Multi-Encoder Transformer Model for Predicting Neonatal Birth Weight from Multimodal Data
作者: Muhammad Mursil, Hatem A. Rashwan, Luis Santos-Calderon, Pere Cavalle-Busquets, Michelle M. Murphy, Domenec Puig
分类: cs.LG
发布日期: 2025-04-20
💡 一句话要点
M-TabNet:多编码器Transformer模型,用于多模态数据预测新生儿出生体重
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 新生儿出生体重预测 多模态数据融合 Transformer模型 注意力机制 深度学习 可解释性 早期风险评估
📋 核心要点
- 现有新生儿出生体重预测方法,如超声检查,精度受限且依赖操作者,同时忽略了营养和遗传因素的影响。
- 论文提出一种基于注意力机制的多编码器Transformer模型M-TabNet,整合多模态孕妇数据,实现更准确的早期出生体重预测。
- 实验结果表明,M-TabNet在内部和公开数据集上均表现出高预测精度和良好的泛化能力,并具有较强的可解释性。
📝 摘要(中文)
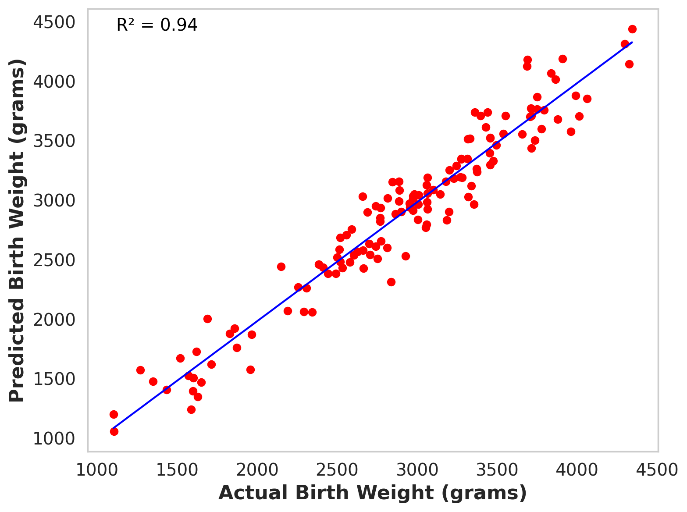
本研究提出了一种基于注意力机制的Transformer模型,采用多编码器架构,用于早期(妊娠12周前)预测新生儿出生体重(BW)。低出生体重(LBW)与新生儿死亡率和发病率增加有关,早期预测BW有助于及时干预。现有方法如超声检查存在局限性,且忽略了营养和遗传因素。该模型有效整合了生理、生活方式、营养和遗传等多方面的孕妇数据,克服了现有基于注意力机制模型(如TabNet)的不足。实验结果表明,该模型在内部数据集上实现了122克的平均绝对误差(MAE)和0.94的R平方值,在IEEE儿童数据集上实现了105克的MAE和0.95的R平方值,验证了其泛化能力。此外,模型将预测的BW分为低和正常两类,灵敏度为97.55%,特异性为94.48%,有助于早期风险分层。通过特征重要性和SHAP分析增强了模型的可解释性,突出了孕妇年龄、烟草暴露和维生素B12状态的重要影响,遗传因素起次要作用。该研究强调了先进深度学习模型在改善早期BW预测方面的潜力,为临床医生提供了一个稳健、可解释和个性化的工具,用于识别高危妊娠并优化新生儿结局。
🔬 方法详解
问题定义:论文旨在解决新生儿出生体重早期预测精度不高的问题,现有方法如超声检查存在操作依赖性,且忽略了营养和遗传因素等重要信息,导致预测结果不够准确,无法有效进行早期干预。
核心思路:论文的核心思路是利用Transformer模型的注意力机制,融合多模态的孕妇数据(生理、生活方式、营养、遗传),学习不同因素对出生体重的影响,从而提高预测精度。多编码器结构的设计旨在更好地处理不同类型的数据,并提取更丰富的特征。
技术框架:M-TabNet模型采用多编码器Transformer架构。首先,不同模态的孕妇数据(生理、生活方式、营养、遗传)分别通过各自的编码器进行特征提取。然后,利用Transformer的注意力机制,将不同模态的特征进行融合,学习它们之间的相互关系。最后,通过一个预测层,输出新生儿出生体重的预测值。
关键创新:论文的关键创新在于提出了多编码器Transformer模型M-TabNet,该模型能够有效整合多模态的孕妇数据,克服了现有方法仅依赖单一数据源的局限性。此外,M-TabNet利用注意力机制学习不同因素对出生体重的影响,提高了预测精度和可解释性。
关键设计:论文中没有明确给出关键参数设置、损失函数、网络结构的具体技术细节。但可以推断,编码器的选择可能根据不同模态数据的特点进行调整,损失函数可能采用均方误差或平均绝对误差等回归任务常用的损失函数。注意力机制的具体实现可能采用Scaled Dot-Product Attention。
🖼️ 关键图片
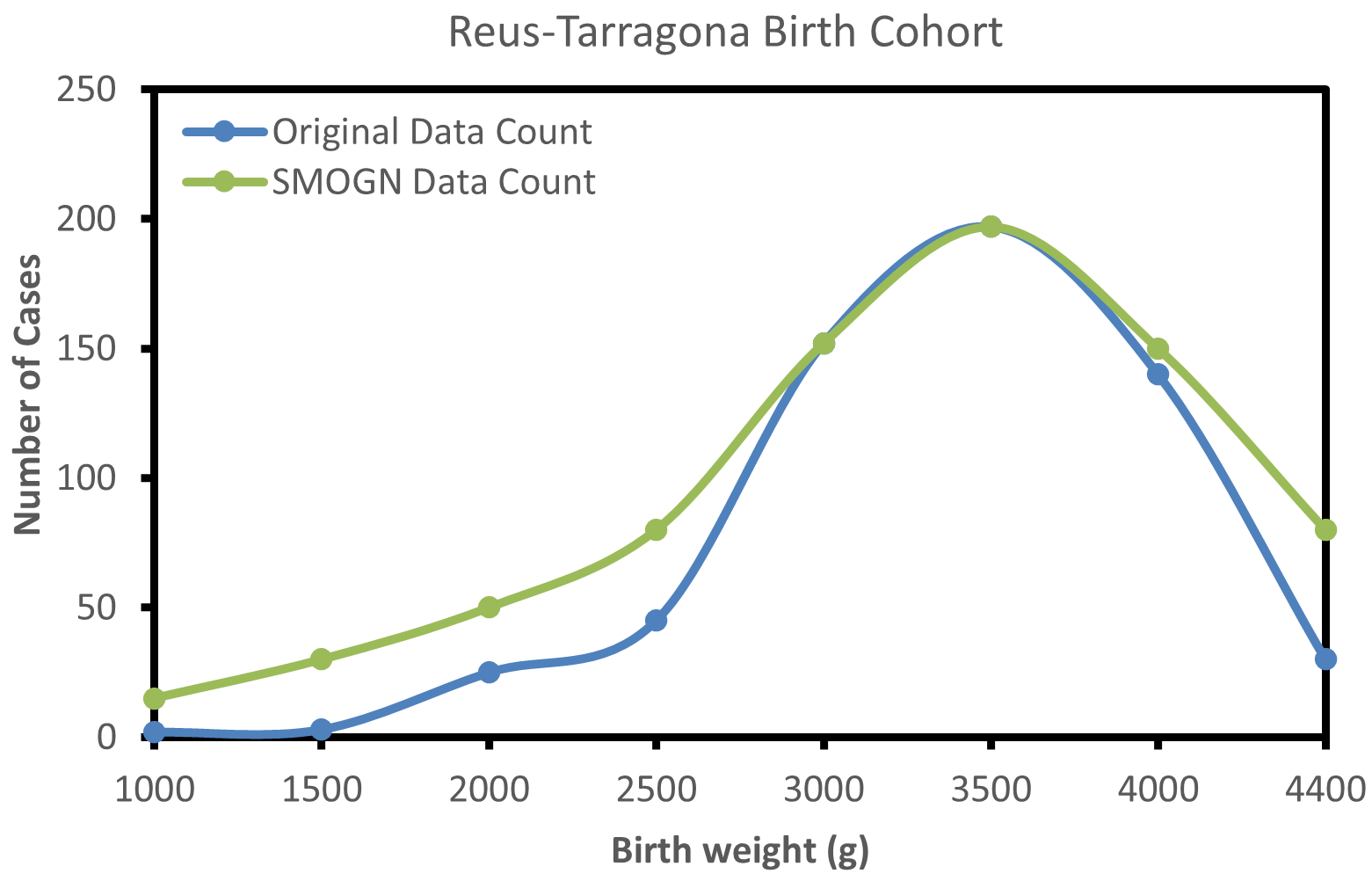
📊 实验亮点
M-TabNet模型在内部数据集上实现了122克的平均绝对误差(MAE)和0.94的R平方值,在IEEE儿童数据集上实现了105克的MAE和0.95的R平方值,表明其具有较高的预测精度和良好的泛化能力。此外,模型在低出生体重分类任务中,灵敏度达到97.55%,特异性达到94.48%,有助于早期风险分层。
🎯 应用场景
该研究成果可应用于临床,为医生提供一种更准确、更全面的新生儿出生体重预测工具。通过早期识别高危妊娠,医生可以采取有针对性的干预措施,改善新生儿的健康状况,降低低出生体重儿的死亡率和发病率。该模型还可用于个性化营养指导和健康管理,为孕妇提供更科学的孕期保健建议。
📄 摘要(原文)
Birth weight (BW) is a key indicator of neonatal health, with low birth weight (LBW) linked to increased mortality and morbidity. Early prediction of BW enables timely interventions; however, current methods like ultrasonography have limitations, including reduced accuracy before 20 weeks and operator dependent variability. Existing models often neglect nutritional and genetic influences, focusing mainly on physiological and lifestyle factors. This study presents an attention-based transformer model with a multi-encoder architecture for early (less than 12 weeks of gestation) BW prediction. Our model effectively integrates diverse maternal data such as physiological, lifestyle, nutritional, and genetic, addressing limitations seen in prior attention-based models such as TabNet. The model achieves a Mean Absolute Error (MAE) of 122 grams and an R-squared value of 0.94, demonstrating high predictive accuracy and interoperability with our in-house private dataset. Independent validation confirms generalizability (MAE: 105 grams, R-squared: 0.95) with the IEEE children dataset. To enhance clinical utility, predicted BW is classified into low and normal categories, achieving a sensitivity of 97.55% and a specificity of 94.48%, facilitating early risk stratification. Model interpretability is reinforced through feature importance and SHAP analyses, highlighting significant influences of maternal age, tobacco exposure, and vitamin B12 status, with genetic factors playing a secondary role. Our results emphasize the potential of advanced deep-learning models to improve early BW prediction, offering clinicians a robust, interpretable, and personalized tool for identifying pregnancies at risk and optimizing neonatal outcomes.