Large Language Bayes
作者: Justin Domke
分类: cs.LG
发布日期: 2025-04-18 (更新: 2025-10-23)
备注: NeurIPS 2025
💡 一句话要点
提出Large Language Bayes,利用大语言模型从非正式描述中构建贝叶斯模型并进行推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 贝叶斯模型 大型语言模型 概率编程 自动化建模 近似推理
📋 核心要点
- 领域专家构建贝叶斯模型困难,需要一种能从非正式描述自动构建模型的方法。
- 利用大语言模型生成多个形式模型,并结合概率编程语言进行推理。
- 实验表明,该方法仅凭数据和非正式描述即可生成合理的预测结果。
📝 摘要(中文)
许多领域专家缺乏编写正式贝叶斯模型的时间或专业知识。本文将非正式的问题描述作为输入,结合大型语言模型和概率编程语言,定义了形式模型、潜在变量和数据上的联合分布。通过对观测数据进行条件化并对形式模型进行积分,可以得到潜在变量的后验分布。这是一个具有挑战性的推理问题。我们提出了一种推理方法,该方法相当于从大型语言模型中生成许多形式模型,对每个模型执行近似推理,然后进行加权平均。这被证明并分析为自归一化重要性抽样、MCMC和重要性加权变分推理的组合。实验表明,仅凭数据和非正式的问题描述,无需指定正式模型,即可产生合理的预测。
🔬 方法详解
问题定义:论文旨在解决领域专家难以将领域知识转化为形式化贝叶斯模型的问题。现有方法需要专家手动构建模型,耗时且需要专业知识,限制了贝叶斯方法在更广泛领域的应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,将非正式的问题描述转化为多个可能的正式贝叶斯模型。然后,对这些模型进行加权平均,以获得更鲁棒的推理结果。这种方法避免了手动构建模型的需要,降低了贝叶斯方法的使用门槛。
技术框架:整体框架包含以下几个主要阶段:1) 模型生成:使用LLM将非正式问题描述转化为多个形式化的贝叶斯模型,每个模型都包含潜在变量和数据之间的联合分布。2) 近似推理:对每个生成的模型,使用近似推理方法(如MCMC或变分推理)估计潜在变量的后验分布。3) 模型集成:对所有模型的后验分布进行加权平均,权重由LLM生成模型的概率决定。这个过程可以看作是自归一化重要性抽样、MCMC和重要性加权变分推理的组合。
关键创新:最重要的创新点在于利用LLM自动生成贝叶斯模型,从而将非正式的领域知识转化为可推理的形式化模型。与传统方法相比,该方法无需手动指定模型结构,大大降低了建模难度。此外,通过集成多个模型,提高了推理的鲁棒性和准确性。
关键设计:LLM的选择和prompt设计至关重要,直接影响生成模型的质量。近似推理方法的选择需要根据具体模型而定,MCMC适用于复杂模型,而变分推理适用于大规模数据。模型集成的权重可以根据LLM生成模型的概率或者其他指标进行调整。论文中具体参数设置和损失函数等细节未知。
🖼️ 关键图片
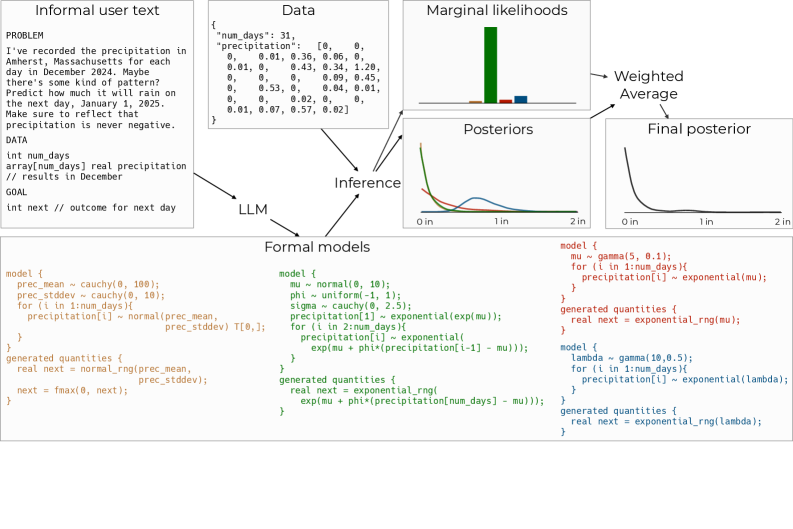
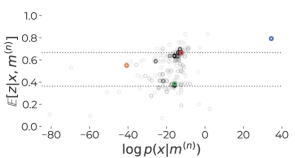
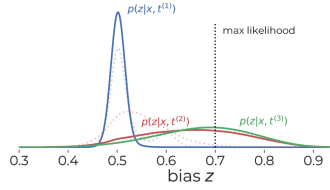
📊 实验亮点
论文通过实验验证了该方法的有效性,结果表明,仅凭数据和非正式的问题描述,无需指定正式模型,即可产生合理的预测结果。具体的性能数据和对比基线未知,但该方法为自动化贝叶斯建模提供了一种新的思路。
🎯 应用场景
该研究成果可应用于各种需要贝叶斯推理的领域,例如医疗诊断、金融风险评估、环境建模等。通过将领域专家的非正式知识转化为形式化模型,可以更有效地利用数据进行预测和决策。未来,该方法有望成为一种通用的贝叶斯建模工具,促进贝叶斯方法在更广泛领域的应用。
📄 摘要(原文)
Many domain experts do not have the time or expertise to write formal Bayesian models. This paper takes an informal problem description as input, and combines a large language model and a probabilistic programming language to define a joint distribution over formal models, latent variables, and data. A posterior over latent variables follows by conditioning on observed data and integrating over formal models. This presents a challenging inference problem. We suggest an inference recipe that amounts to generating many formal models from the large language model, performing approximate inference on each, and then doing a weighted average. This is justified and analyzed as a combination of self-normalized importance sampling, MCMC, and importance-weighted variational inference. Experimentally, this produces sensible predictions from only data and an informal problem description, without the need to specify a formal model.