One Jump Is All You Need: Short-Cutting Transformers for Early Exit Prediction with One Jump to Fit All Exit Levels
作者: Amrit Diggavi Seshadri
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-18
💡 一句话要点
提出One-Jump-Fits-All低秩捷径,显著降低Transformer模型早期退出的参数成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 早期退出 低秩逼近 Transformer模型 参数效率 模型加速
📋 核心要点
- 现有早期退出方法为每个Transformer块维护单独的捷径,导致参数冗余和计算成本高昂。
- 提出One-Jump-Fits-All (OJFA)低秩捷径,使用单个捷径适应所有退出层,大幅降低参数成本。
- 实验表明,OJFA在显著降低参数成本的同时,保持了与多捷径方法相当的性能,并提供稳定的精度。
📝 摘要(中文)
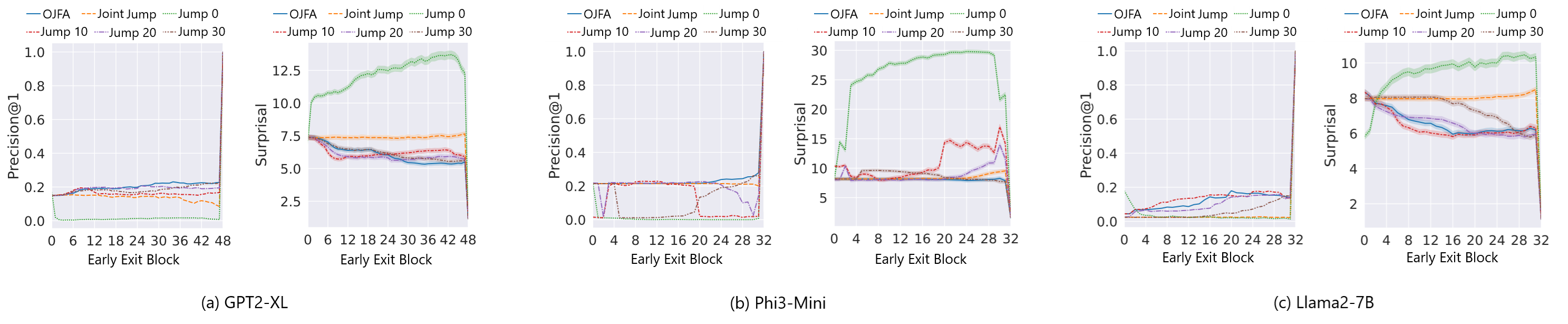
为了降低大型语言模型推理的时间和计算成本,研究者们对参数高效的低秩早期退出方法产生了兴趣,该方法将Transformer的隐藏层表示转换为最终表示。这种低秩捷径已被证明在模型早期阶段优于identity shortcuts,并在捷径跳转中提供参数效率。然而,现有的低秩方法在推理期间为每个Transformer中间块级别维护一个单独的早期退出捷径跳转到最终表示。本文提出了一种One-Jump-Fits-All (OJFA)低秩捷径的选择,在推理期间可将捷径参数成本降低30倍以上。我们表明,尽管有如此极端的降低,我们的OJFA选择在很大程度上与在推理期间维护多个捷径跳转的性能相匹配,并为GPT2-XL、Phi3-Mini和Llama2-7B Transformer模型的所有Transformer块级别提供稳定的精度。
🔬 方法详解
问题定义:大型语言模型推理成本高昂,早期退出是一种加速推理的有效方法。现有的低秩捷径方法虽然能提升早期退出性能,但需要为每个Transformer块维护独立的捷径,导致参数量和计算开销显著增加,限制了其在资源受限场景下的应用。
核心思路:论文的核心思想是使用一个通用的低秩捷径(One-Jump-Fits-All, OJFA)来连接所有Transformer块的中间表示到最终表示,从而避免为每个块单独维护捷径。这种设计基于观察到不同层的表示可能存在一定的冗余性,可以通过学习一个共享的低秩映射来有效利用这些冗余信息。
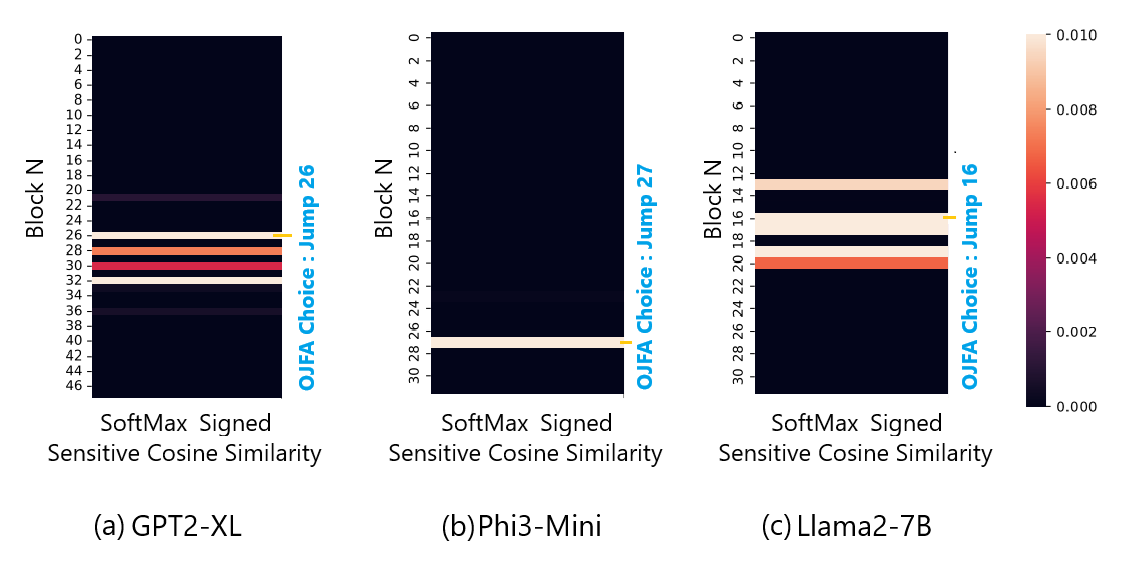
技术框架:该方法的核心在于选择一个合适的Transformer块作为“跳板”,并学习一个低秩矩阵,将该块的隐藏层表示映射到最终的输出表示。推理时,所有其他块的早期退出都通过这个共享的低秩映射来实现。整体流程包括:1) 选择一个Transformer块作为OJFA的跳板;2) 训练一个低秩矩阵,将该块的隐藏层表示映射到最终输出;3) 在推理时,所有块的早期退出都使用该低秩矩阵。
关键创新:最关键的创新在于提出了One-Jump-Fits-All (OJFA) 的概念,即使用单个低秩捷径来适应所有Transformer块的早期退出。与现有方法为每个块单独维护捷径相比,OJFA显著降低了参数成本,同时保持了可比的性能。这种共享捷径的思想可以推广到其他类型的模型和任务中。
关键设计:关键设计包括:1) 低秩矩阵的秩的选择,需要平衡参数量和性能;2) 选择哪个Transformer块作为OJFA的跳板,不同的块可能具有不同的表示能力;3) 低秩矩阵的训练方式,可以使用标准的监督学习方法,也可以使用一些特殊的正则化技术来提高泛化能力。论文中具体使用的参数设置和训练细节未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OJFA方法在GPT2-XL、Phi3-Mini和Llama2-7B等模型上,能够以超过30倍的参数成本降低,实现与多捷径方法相当的性能。同时,OJFA为所有Transformer块级别提供了稳定的精度,验证了其有效性和通用性。
🎯 应用场景
该研究成果可应用于资源受限的设备上部署大型语言模型,例如移动设备、嵌入式系统等。通过降低模型推理的参数成本,可以实现更快的推理速度和更低的功耗,从而扩展大型语言模型在边缘计算领域的应用。
📄 摘要(原文)
To reduce the time and computational costs of inference of large language models, there has been interest in parameter-efficient low-rank early-exit casting of transformer hidden-representations to final-representations. Such low-rank short-cutting has been shown to outperform identity shortcuts at early model stages while offering parameter-efficiency in shortcut jumps. However, current low-rank methods maintain a separate early-exit shortcut jump to final-representations for each transformer intermediate block-level during inference. In this work, we propose selection of a single One-Jump-Fits-All (OJFA) low-rank shortcut that offers over a 30x reduction in shortcut parameter costs during inference. We show that despite this extreme reduction, our OJFA choice largely matches the performance of maintaining multiple shortcut jumps during inference and offers stable precision from all transformer block-levels for GPT2-XL, Phi3-Mini and Llama2-7B transformer models.