Representation Learning for Tabular Data: A Comprehensive Survey
作者: Jun-Peng Jiang, Si-Yang Liu, Hao-Run Cai, Qile Zhou, Han-Jia Ye
分类: cs.LG
发布日期: 2025-04-17
🔗 代码/项目: GITHUB
💡 一句话要点
表格数据表示学习综述:系统性地回顾了基于深度神经网络的表格数据表示学习方法。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 表示学习 深度学习 综述 迁移学习 自监督学习 特征工程
📋 核心要点
- 现有表格数据学习方法在处理复杂关系和异构数据方面存在不足,限制了模型的泛化能力。
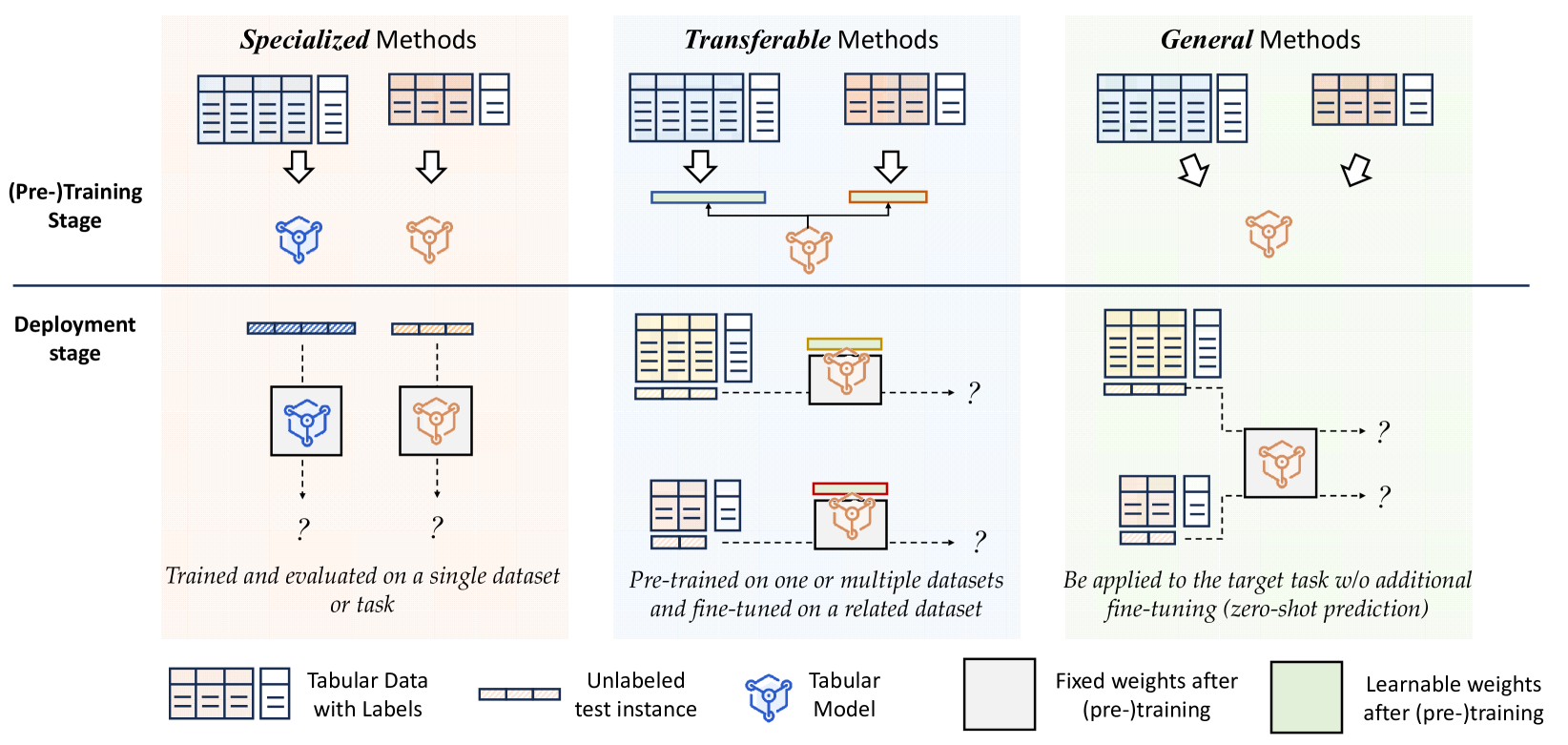
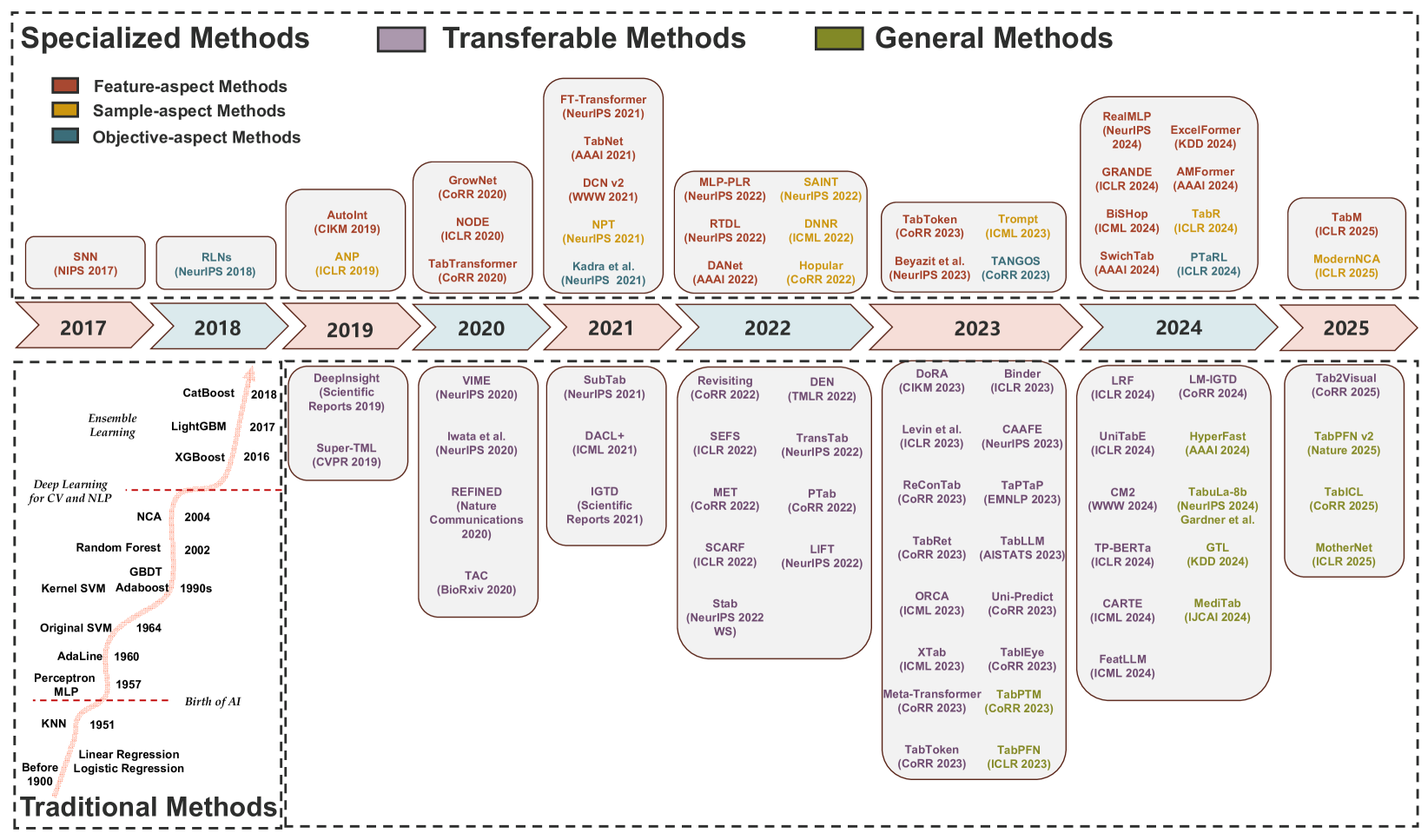
- 论文系统性地综述了表格数据表示学习,将现有方法分为专用、可迁移和通用模型三类,并分析了各自的优缺点。
- 该综述为研究人员提供了全面的表格数据表示学习方法概览,并指出了未来研究方向,促进了该领域的发展。
📝 摘要(中文)
表格数据以行和列的结构化形式存在,是机器学习分类和回归应用中最常见的数据类型之一。表格数据学习模型不断发展,其中深度神经网络(DNNs)最近通过其表示学习能力展示了令人期待的结果。本综述系统地介绍了表格表示学习领域,涵盖了背景、挑战和基准,以及使用DNNs的优缺点。我们根据其泛化能力将现有方法分为三类:专用模型、可迁移模型和通用模型。专用模型侧重于在相同数据分布内进行训练和评估的任务。我们基于表格数据的关键方面——特征、样本和目标——为专用模型引入了分层分类法,并深入研究了获得高质量特征和样本级别表示的详细策略。可迁移模型在一个或多个数据集上进行预训练,然后在下游任务上进行微调,利用来自同构或异构源的知识,甚至跨模态(如视觉和语言)。通用模型,也称为表格基础模型,进一步扩展了这个概念,允许直接应用于下游任务而无需微调。我们根据用于适应异构数据集的策略对这些通用模型进行分组。此外,我们还探讨了集成方法,该方法集成了多个表格模型的优势。最后,我们讨论了表格学习的代表性扩展,包括开放环境表格机器学习、具有表格数据的多模态学习和表格理解。
🔬 方法详解
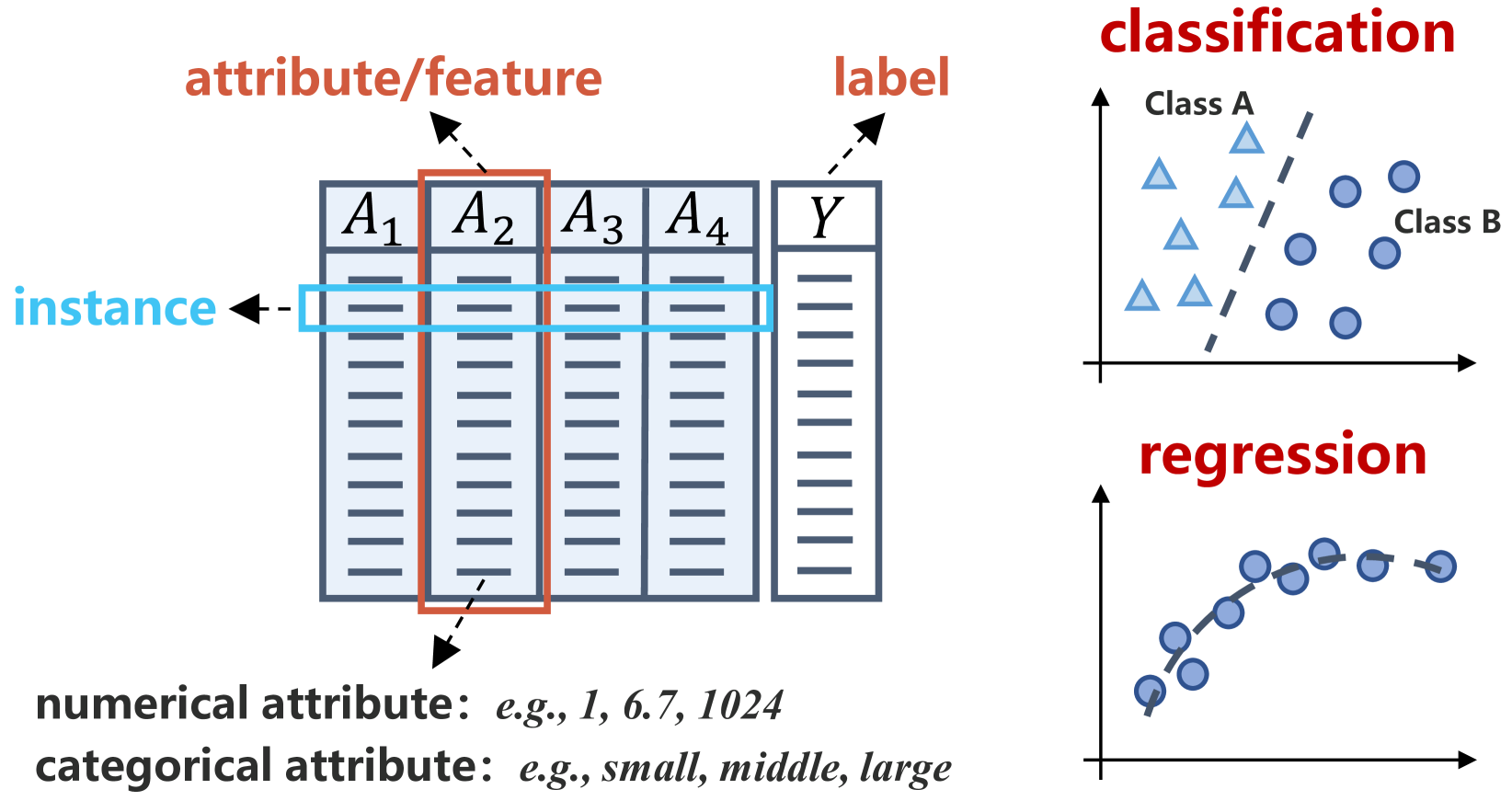
问题定义:表格数据表示学习旨在学习表格数据的有效表示,以便下游任务(如分类、回归)能够取得更好的性能。现有方法,尤其是传统机器学习方法,通常依赖于手工特征工程,难以捕捉表格数据中复杂的非线性关系。深度学习方法虽然具有自动特征学习的能力,但在表格数据上的应用仍面临挑战,例如如何有效处理异构特征、如何提高模型的泛化能力等。
核心思路:论文的核心思路是对现有的表格数据表示学习方法进行系统性的分类和总结,并分析各种方法的优缺点,从而为研究人员提供一个全面的参考框架。通过对不同方法的泛化能力进行区分,可以更好地理解各种方法的适用场景和局限性。
技术框架:论文将表格数据表示学习方法分为三类:专用模型、可迁移模型和通用模型。专用模型针对特定数据集进行优化;可迁移模型通过预训练和微调,将知识从一个数据集迁移到另一个数据集;通用模型则旨在直接应用于各种下游任务,无需微调。对于专用模型,论文进一步根据特征、样本和目标三个方面进行分类。此外,论文还讨论了集成方法和表格学习的扩展应用。
关键创新:论文的主要创新在于对表格数据表示学习方法进行了系统性的分类和总结,并提出了一个基于泛化能力的分类框架。该框架有助于研究人员更好地理解各种方法的特点和适用场景,并为未来的研究方向提供了指导。
关键设计:论文没有提出新的模型或算法,而是对现有方法进行了梳理和分析。关键的设计在于分类框架的构建,该框架基于模型的泛化能力,将方法分为专用、可迁移和通用模型。此外,论文还对各种方法的优缺点进行了详细的分析,并指出了未来研究方向。
🖼️ 关键图片
📊 实验亮点
该综述全面回顾了表格数据表示学习的最新进展,并根据模型的泛化能力,将现有方法分为专用模型、可迁移模型和通用模型。这种分类方式有助于研究人员更好地理解各种方法的特点和适用场景。此外,该综述还讨论了表格学习的扩展应用,为未来的研究方向提供了指导。
🎯 应用场景
表格数据表示学习在金融、医疗、电商等领域具有广泛的应用前景。例如,在金融领域,可以用于信用评分、欺诈检测;在医疗领域,可以用于疾病诊断、药物发现;在电商领域,可以用于用户行为分析、商品推荐。通过学习有效的表格数据表示,可以提高模型的预测精度和泛化能力,从而为这些应用带来实际价值。
📄 摘要(原文)
Tabular data, structured as rows and columns, is among the most prevalent data types in machine learning classification and regression applications. Models for learning from tabular data have continuously evolved, with Deep Neural Networks (DNNs) recently demonstrating promising results through their capability of representation learning. In this survey, we systematically introduce the field of tabular representation learning, covering the background, challenges, and benchmarks, along with the pros and cons of using DNNs. We organize existing methods into three main categories according to their generalization capabilities: specialized, transferable, and general models. Specialized models focus on tasks where training and evaluation occur within the same data distribution. We introduce a hierarchical taxonomy for specialized models based on the key aspects of tabular data -- features, samples, and objectives -- and delve into detailed strategies for obtaining high-quality feature- and sample-level representations. Transferable models are pre-trained on one or more datasets and subsequently fine-tuned on downstream tasks, leveraging knowledge acquired from homogeneous or heterogeneous sources, or even cross-modalities such as vision and language. General models, also known as tabular foundation models, extend this concept further, allowing direct application to downstream tasks without fine-tuning. We group these general models based on the strategies used to adapt across heterogeneous datasets. Additionally, we explore ensemble methods, which integrate the strengths of multiple tabular models. Finally, we discuss representative extensions of tabular learning, including open-environment tabular machine learning, multimodal learning with tabular data, and tabular understanding. More information can be found in the following repository: https://github.com/LAMDA-Tabular/Tabular-Survey.