Uncertainty-Aware Trajectory Prediction via Rule-Regularized Heteroscedastic Deep Classification
作者: Kumar Manas, Christian Schlauch, Adrian Paschke, Christian Wirth, Nadja Klein
分类: cs.LG, cs.RO
发布日期: 2025-04-17 (更新: 2025-08-28)
备注: 17 Pages, 9 figures. Accepted to Robotics: Science and Systems(RSS), 2025
期刊: Robotics: Science and Systems (RSS), 2025
DOI: 10.15607/RSS.2025.XXI.144
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出SHIFT框架,结合不确定性建模与规则先验,提升轨迹预测在复杂场景下的泛化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 轨迹预测 不确定性建模 异方差高斯过程 规则提取 自动驾驶
📋 核心要点
- 现有轨迹预测模型在分布外泛化能力不足,尤其是在数据不平衡和缺乏多样性的情况下,鲁棒性和校准性面临挑战。
- SHIFT框架结合了良好校准的不确定性建模和通过自动规则提取获得的先验信息,提升了模型在复杂场景下的预测能力。
- 在nuScenes数据集上的实验表明,SHIFT在不确定性校准和位移指标方面优于现有方法,尤其在复杂场景中表现突出。
📝 摘要(中文)
本文提出了一种名为SHIFT(Spectral Heteroscedastic Informed Forecasting for Trajectories)的新型轨迹预测框架,旨在解决深度学习轨迹预测模型在分布外泛化方面的挑战,尤其是在数据不平衡和缺乏足够数据多样性的情况下。SHIFT的核心在于将良好校准的不确定性建模与通过自动规则提取获得的先验信息相结合。它将轨迹预测重新定义为一个分类任务,并采用异方差谱归一化高斯过程来有效分离认知不确定性和偶然不确定性。此外,该方法从训练标签中学习信息丰富的先验知识,这些标签通过检索增强生成框架,利用大型语言模型从自然语言驾驶规则(如停止规则和可驾驶性约束)中自动生成。在nuScenes数据集上的大量评估,包括具有挑战性的低数据和跨位置场景,表明SHIFT优于最先进的方法,在不确定性校准和位移指标方面取得了显著的提升。尤其是在交叉路口等不确定性较高的复杂场景中,该模型表现出色。
🔬 方法详解
问题定义:现有的基于深度学习的轨迹预测模型在处理分布外数据时泛化能力较弱,尤其是在数据不平衡或者数据量不足的情况下。这些模型难以准确估计预测结果的不确定性,导致在复杂场景下的预测结果不可靠。现有方法难以有效利用驾驶规则等先验知识来提升模型的鲁棒性和校准性。
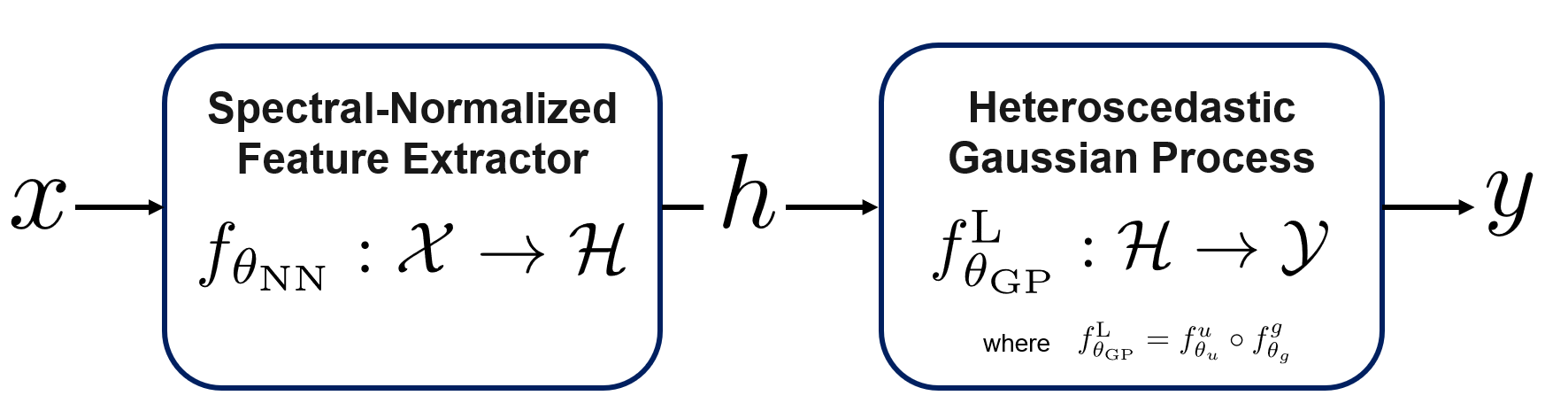
核心思路:SHIFT的核心思路是将轨迹预测问题转化为一个分类问题,并利用异方差高斯过程来建模预测结果的不确定性。通过自动提取驾驶规则并将其作为先验知识融入模型,从而提升模型在复杂场景下的泛化能力和不确定性估计的准确性。这种方法能够有效分离认知不确定性和偶然不确定性,并利用大型语言模型来生成信息丰富的先验知识。
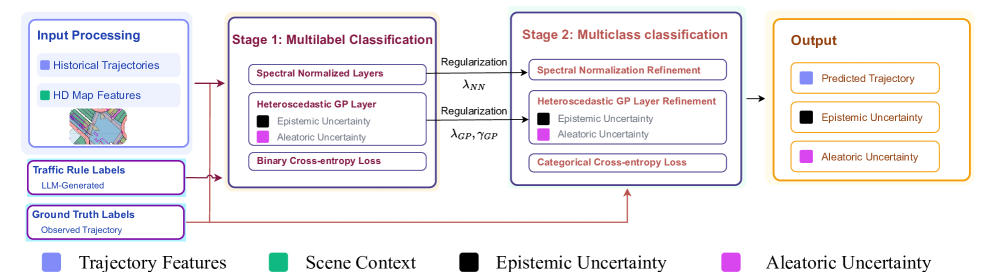
技术框架:SHIFT框架主要包含以下几个模块:1) 轨迹分类器:将轨迹预测问题转化为分类问题,预测车辆在未来一段时间内可能到达的区域。2) 异方差谱归一化高斯过程:用于建模预测结果的不确定性,能够区分认知不确定性和偶然不确定性。3) 规则提取模块:利用大型语言模型从自然语言驾驶规则中自动提取先验知识。4) 检索增强生成框架:用于生成训练标签,并将其作为先验知识融入模型。整个流程是,首先利用规则提取模块提取驾驶规则,然后利用检索增强生成框架生成训练标签,接着利用轨迹分类器和异方差谱归一化高斯过程进行轨迹预测和不确定性估计。
关键创新:SHIFT的关键创新在于:1) 将轨迹预测问题转化为分类问题,并利用异方差高斯过程来建模不确定性。2) 提出了一种自动提取驾驶规则并将其作为先验知识融入模型的方法。3) 利用大型语言模型来生成信息丰富的先验知识。与现有方法相比,SHIFT能够更准确地估计预测结果的不确定性,并在复杂场景下具有更好的泛化能力。
关键设计:在异方差谱归一化高斯过程中,使用了谱归一化技术来约束模型的复杂度,从而提高模型的泛化能力。在规则提取模块中,使用了大型语言模型来生成自然语言驾驶规则的表示,并将其作为先验知识融入模型。损失函数包括分类损失和不确定性损失,用于优化模型的预测精度和不确定性估计的准确性。
🖼️ 关键图片
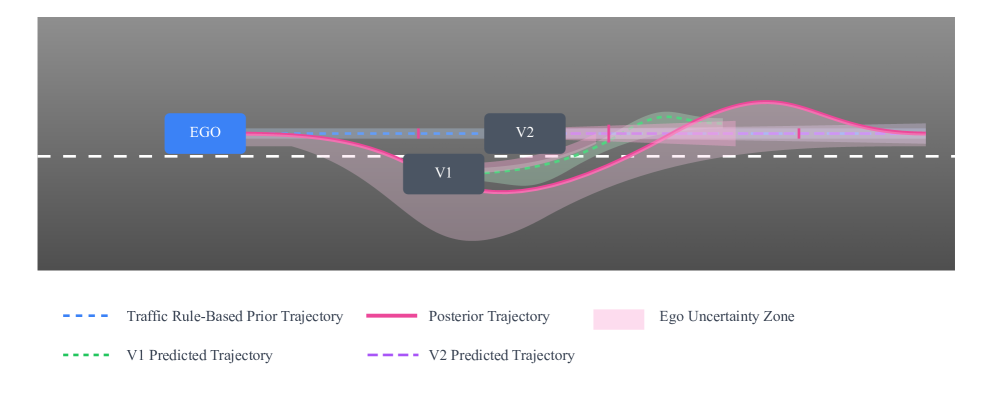
📊 实验亮点
SHIFT在nuScenes数据集上进行了广泛的评估,包括低数据和跨位置场景。实验结果表明,SHIFT在不确定性校准和位移指标方面优于最先进的方法。例如,在交叉路口等复杂场景中,SHIFT的不确定性校准误差显著降低,位移误差也得到了明显改善。与现有方法相比,SHIFT在复杂场景下的预测精度和鲁棒性得到了显著提升。
🎯 应用场景
该研究成果可应用于自动驾驶、智能交通系统等领域。通过提高轨迹预测的准确性和可靠性,可以提升自动驾驶车辆在复杂交通环境中的安全性。此外,该方法还可以用于预测行人和骑自行车者的轨迹,从而提高交通系统的整体安全性。
📄 摘要(原文)
Deep learning-based trajectory prediction models have demonstrated promising capabilities in capturing complex interactions. However, their out-of-distribution generalization remains a significant challenge, particularly due to unbalanced data and a lack of enough data and diversity to ensure robustness and calibration. To address this, we propose SHIFT (Spectral Heteroscedastic Informed Forecasting for Trajectories), a novel framework that uniquely combines well-calibrated uncertainty modeling with informative priors derived through automated rule extraction. SHIFT reformulates trajectory prediction as a classification task and employs heteroscedastic spectral-normalized Gaussian processes to effectively disentangle epistemic and aleatoric uncertainties. We learn informative priors from training labels, which are automatically generated from natural language driving rules, such as stop rules and drivability constraints, using a retrieval-augmented generation framework powered by a large language model. Extensive evaluations over the nuScenes dataset, including challenging low-data and cross-location scenarios, demonstrate that SHIFT outperforms state-of-the-art methods, achieving substantial gains in uncertainty calibration and displacement metrics. In particular, our model excels in complex scenarios, such as intersections, where uncertainty is inherently higher. Project page: https://kumarmanas.github.io/SHIFT/.