Tilus: A Tile-Level GPGPU Programming Language for Low-Precision Computation
作者: Yaoyao Ding, Bohan Hou, Xiao Zhang, Allan Lin, Tianqi Chen, Cody Yu Hao, Yida Wang, Gennady Pekhimenko
分类: cs.LG, cs.AI, cs.PL
发布日期: 2025-04-17 (更新: 2025-08-31)
备注: 17 pages, 14 figures, 1 table
🔗 代码/项目: GITHUB
💡 一句话要点
Tilus:一种面向低精度计算的Tile级GPGPU编程语言
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: GPGPU编程 低精度计算 领域特定语言 编译器优化 大型语言模型 GPU Kernel 自动向量化
📋 核心要点
- 现有低精度计算kernel生成方法受限于2的幂次的位宽,且高级编程抽象阻碍了细粒度优化,导致性能瓶颈。
- Tilus是一种领域特定语言,支持1-8位任意位宽的低精度数据类型,并提供线程块级编程模型和分层存储空间。
- 实验表明,Tilus在各种低精度数据类型上均表现出色,并超越了现有编译器和手工优化的kernel。
📝 摘要(中文)
服务大型语言模型(LLMs)对AI应用至关重要,但它需要大量的计算资源,尤其是在内存带宽和计算吞吐量方面。低精度计算已成为提高效率同时降低资源消耗的关键技术。现有的低精度kernel生成方法仅限于2的幂次的权重位宽,并且由于高级GPU编程抽象而导致次优性能。这些抽象限制了关键优化,例如细粒度的寄存器管理和优化的内存访问模式,这对于高效的低精度计算至关重要。本文介绍Tilus,一种专为通用GPU(GPGPU)计算设计的领域特定语言,它支持1到8位任意位宽的低精度数据类型,同时保持GPU的可编程性。Tilus具有线程块级编程模型、分层存储空间、一种新颖的代数布局系统以及对各种低精度数据类型的广泛支持。Tilus程序通过自动向量化和指令选择被编译成高效的GPU程序。大量实验表明,Tilus有效地支持全方位的低精度数据类型,并且优于最先进的低精度kernel。与现有的编译器(如Triton和Ladder)以及手动优化的kernel(如QuantLLM和Marlin)相比,Tilus分别实现了1.75倍、2.61倍、1.29倍和1.03倍的性能提升。我们在https://github.com/NVIDIA/tilus开源了Tilus。
🔬 方法详解
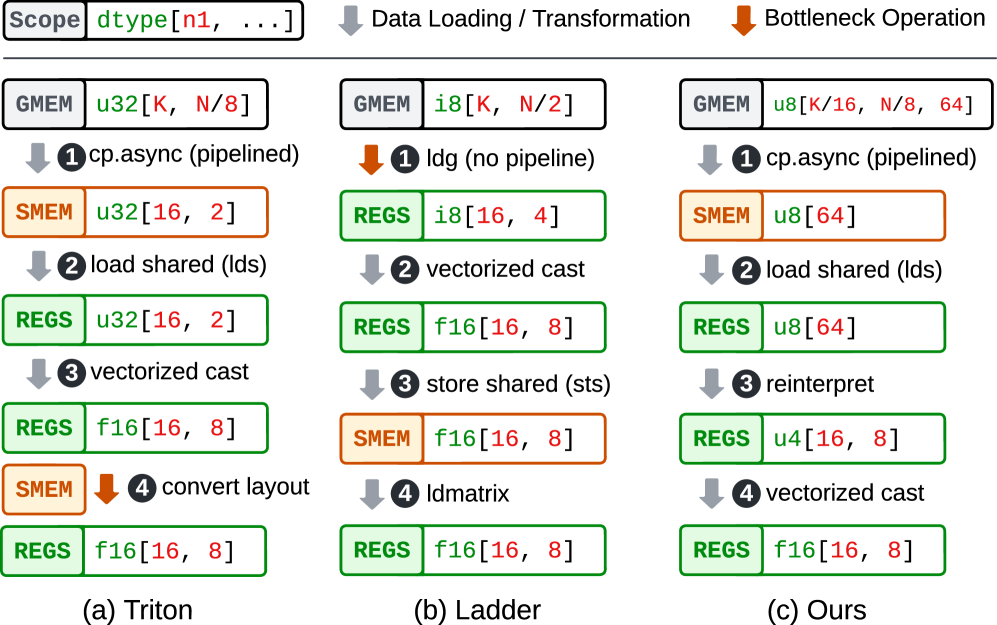
问题定义:论文旨在解决现有GPGPU编程框架在低精度计算方面效率低下的问题。现有方法,如Triton和Ladder,以及手工优化的kernel,如QuantLLM和Marlin,在处理任意位宽的低精度数据时,由于高级编程抽象的限制,无法充分利用GPU的硬件特性,导致性能受限。具体痛点包括无法进行细粒度的寄存器管理和优化内存访问模式。
核心思路:Tilus的核心思路是提供一种领域特定语言(DSL),允许开发者在更接近硬件的层面上进行编程,从而实现更精细的控制和优化。通过线程块级的编程模型、分层存储空间和代数布局系统,Tilus能够更好地利用GPU的并行计算能力和内存带宽,从而提高低精度计算的效率。这样设计的目的是为了克服现有高级编程抽象带来的性能瓶颈。
技术框架:Tilus的技术框架主要包括以下几个部分:1) 线程块级编程模型:允许开发者以线程块为单位进行编程,更好地控制GPU的并行执行。2) 分层存储空间:提供多种存储空间,包括全局内存、共享内存和寄存器,允许开发者根据数据的访问模式选择合适的存储位置。3) 代数布局系统:提供一种灵活的方式来描述数据的布局,允许开发者根据计算需求优化内存访问模式。4) 自动向量化和指令选择:编译器能够自动将Tilus程序转换为高效的GPU指令。
关键创新:Tilus最重要的技术创新在于其领域特定语言的设计,它允许开发者在保持GPU可编程性的同时,对低精度计算进行更精细的控制和优化。与现有方法相比,Tilus能够支持任意位宽的低精度数据类型(1-8位),并且能够通过自动向量化和指令选择生成高效的GPU代码。这种设计使得Tilus能够更好地利用GPU的硬件特性,从而提高低精度计算的效率。
关键设计:Tilus的关键设计包括:1) 线程块大小的配置,需要根据具体的GPU架构和计算任务进行调整,以达到最佳的并行执行效果。2) 分层存储空间的使用,需要根据数据的访问模式选择合适的存储位置,以减少内存访问延迟。3) 代数布局系统的设计,需要根据计算需求优化内存访问模式,以提高内存带宽的利用率。4) 自动向量化和指令选择的策略,需要根据GPU的指令集和计算任务进行优化,以生成高效的GPU代码。具体的损失函数和网络结构设计未知,因为Tilus主要关注的是底层编程模型和编译器优化。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Tilus在低精度计算方面显著优于现有方法。与Triton相比,Tilus实现了1.75倍的性能提升;与Ladder相比,提升了2.61倍;与QuantLLM和Marlin相比,分别提升了1.29倍和1.03倍。这些数据表明,Tilus能够有效地支持全方位的低精度数据类型,并生成高效的GPU代码。
🎯 应用场景
Tilus在大型语言模型(LLMs)的部署和服务中具有广泛的应用前景。通过高效的低精度计算,Tilus可以显著降低LLMs的计算资源需求,使其能够在资源受限的设备上运行。此外,Tilus还可以应用于其他需要大量计算的AI应用,如图像识别、语音识别和自然语言处理等。未来,Tilus有望成为低精度计算领域的重要工具,推动AI技术的发展。
📄 摘要(原文)
Serving Large Language Models (LLMs) is critical for AI-powered applications, yet it demands substantial computational resources, particularly in memory bandwidth and computational throughput. Low-precision computation has emerged as a key technique to improve efficiency while reducing resource consumption. Existing approaches for generating low-precision kernels are limited to weight bit widths that are powers of two and suffer from suboptimal performance because of high-level GPU programming abstractions. These abstractions restrict critical optimizations, such as fine-grained register management and optimized memory access patterns, that are essential for efficient low-precision computations. In this paper, we introduce Tilus, a domain-specific language designed for General-Purpose GPU (GPGPU) computing that supports low-precision data types with arbitrary bit widths from 1 to 8 while maintaining GPU programmability. Tilus features a thread-block-level programming model, a hierarchical memory space, a novel algebraic layout system, and extensive support for diverse low-precision data types. Tilus programs are compiled into highly efficient GPU programs through automatic vectorization and instruction selection. Extensive experiments demonstrate that Tilus efficiently supports a full spectrum of low-precision data types, and outperforms state-of-the-art low-precision kernels. Compared to existing compilers such as Triton and Ladder, as well as hand-optimized kernels such as QuantLLM and Marlin, Tilus achieves performance improvements of: $1.75\times$, $2.61\times$, $1.29\times$ and $1.03\times$, respectively. We open-source Tilus at https://github.com/NVIDIA/tilus.