Can Masked Autoencoders Also Listen to Birds?
作者: Lukas Rauch, René Heinrich, Ilyass Moummad, Alexis Joly, Bernhard Sick, Christoph Scholz
分类: cs.LG, cs.SD, eess.AS
发布日期: 2025-04-17 (更新: 2025-08-19)
备注: accepted @TMLR: https://openreview.net/forum?id=GIBWR0Xo2J
💡 一句话要点
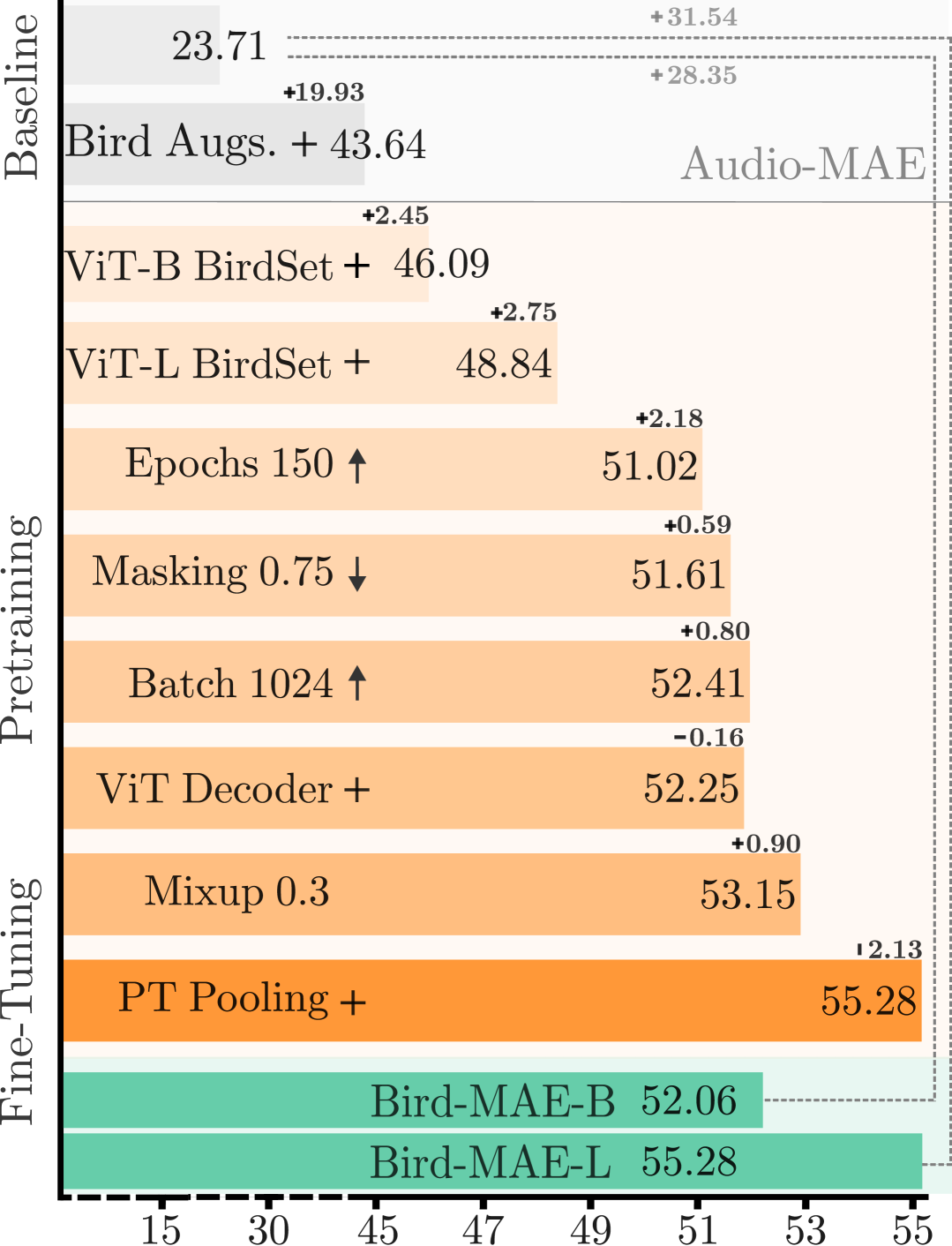
针对鸟鸣声识别,提出Bird-MAE,实现全流程自适应,刷新BirdSet数据集SOTA。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 鸟鸣声识别 掩码自编码器 自监督学习 领域自适应 原型探测
📋 核心要点
- 通用Audio-MAE在细粒度鸟鸣声分类中表现不佳,难以区分物种间细微差异和处理物种内声学变异性。
- 提出Bird-MAE,通过全流程自适应,包括预训练方案、微调方法和冻结特征利用,弥合领域差距。
- Bird-MAE在BirdSet数据集上取得SOTA,原型探测显著提升低资源场景性能,并展现出强大的少样本学习能力。
📝 摘要(中文)
掩码自编码器(MAE)通过高效的自监督重建任务学习音频分类中的丰富语义表示。然而,通用模型在直接应用于细粒度音频领域时,泛化能力较差。特别是,鸟鸣声分类需要区分物种间细微的差异,并管理物种内高度的声学变异性,这暴露了通用领域Audio-MAE的性能局限性。本研究表明,弥合这种领域差距需要全流程的自适应,而不仅仅是特定领域的预训练数据。我们系统地重新审视并调整了预训练方案、微调方法和冻结特征利用,使用BirdSet(一个可与AudioSet媲美的大规模生物声学数据集)进行鸟鸣声处理。我们提出的Bird-MAE在BirdSet的多标签分类基准测试中取得了新的state-of-the-art结果。此外,我们引入了参数高效的原型探测,增强了冻结MAE表示的效用,并在低资源设置中接近微调性能。在BirdSet下游任务中,Bird-MAE的原型探测优于线性探测,平均精度提高了37个百分点,并缩小了与微调的差距。Bird-MAE还在我们新建立的BirdSet少样本基准测试中,通过原型探测展示了强大的少样本能力,突出了为细粒度音频领域定制自监督学习流程的潜力。
🔬 方法详解
问题定义:论文旨在解决通用Audio-MAE在细粒度鸟鸣声分类任务中泛化能力不足的问题。现有方法直接应用通用模型,无法有效区分不同鸟类物种之间细微的声音差异,并且难以处理同一物种内部声音的多样性。这导致在BirdSet等数据集上性能不佳。
核心思路:论文的核心思路是进行全流程的领域自适应,而不仅仅是使用领域特定的数据进行预训练。这意味着需要重新审视和调整预训练的流程、微调的方法,以及如何有效地利用预训练模型提取的特征。通过针对鸟鸣声的特性进行优化,从而提升模型在细粒度音频分类任务上的性能。
技术框架:Bird-MAE的整体框架基于Masked Autoencoder (MAE),包含预训练和微调两个主要阶段。在预训练阶段,模型学习重建被掩盖的音频片段,从而学习音频的潜在表示。在微调阶段,使用BirdSet数据集对预训练模型进行微调,以适应鸟鸣声分类任务。此外,论文还提出了原型探测方法,用于在低资源场景下利用冻结的MAE特征。
关键创新:论文的关键创新在于全流程的领域自适应策略,以及提出的原型探测方法。全流程自适应强调了针对特定领域任务,需要对整个训练流程进行优化,而不仅仅是数据层面的调整。原型探测则是一种参数高效的方法,能够有效利用预训练模型的特征,并在低资源场景下取得接近微调的性能。
关键设计:在预训练阶段,论文可能调整了掩码比例、掩码策略等参数,以适应鸟鸣声的特性。在微调阶段,可能使用了特定的损失函数或正则化方法,以提高模型的泛化能力。原型探测方法通过计算样本与类别原型之间的距离来进行分类,原型可以通过训练数据学习得到。
🖼️ 关键图片


📊 实验亮点
Bird-MAE在BirdSet数据集的多标签分类基准测试中取得了新的SOTA结果。原型探测方法在低资源场景下显著提升了性能,平均精度提高了37个百分点,并缩小了与微调的差距。此外,Bird-MAE在少样本学习方面也表现出色,证明了其在细粒度音频分类任务中的潜力。
🎯 应用场景
该研究成果可应用于生物多样性监测、鸟类保护、生态声学研究等领域。通过自动识别鸟鸣声,可以更高效地进行鸟类种群数量统计、栖息地评估和行为分析。未来,该技术有望扩展到其他生物声学领域,例如海洋生物监测和昆虫声学研究。
📄 摘要(原文)
Masked Autoencoders (MAEs) learn rich semantic representations in audio classification through an efficient self-supervised reconstruction task. However, general-purpose models fail to generalize well when applied directly to fine-grained audio domains. Specifically, bird-sound classification requires distinguishing subtle inter-species differences and managing high intra-species acoustic variability, revealing the performance limitations of general-domain Audio-MAEs. This work demonstrates that bridging this domain gap domain gap requires full-pipeline adaptation, not just domain-specific pretraining data. We systematically revisit and adapt the pretraining recipe, fine-tuning methods, and frozen feature utilization to bird sounds using BirdSet, a large-scale bioacoustic dataset comparable to AudioSet. Our resulting Bird-MAE achieves new state-of-the-art results in BirdSet's multi-label classification benchmark. Additionally, we introduce the parameter-efficient prototypical probing, enhancing the utility of frozen MAE representations and closely approaching fine-tuning performance in low-resource settings. Bird-MAE's prototypical probes outperform linear probing by up to 37 percentage points in mean average precision and narrow the gap to fine-tuning across BirdSet downstream tasks. Bird-MAE also demonstrates robust few-shot capabilities with prototypical probing in our newly established few-shot benchmark on BirdSet, highlighting the potential of tailored self-supervised learning pipelines for fine-grained audio domains.