Hierarchical Vector Quantized Graph Autoencoder with Annealing-Based Code Selection
作者: Long Zeng, Jianxiang Yu, Jiapeng Zhu, Qingsong Zhong, Xiang Li
分类: cs.LG
发布日期: 2025-04-17
期刊: WWW 2025
💡 一句话要点
提出基于退火码选择的分层向量量化图自编码器,提升图拓扑结构捕获能力。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 图自编码器 向量量化 自监督学习 图神经网络 链接预测
📋 核心要点
- 现有图自监督学习方法依赖扰动,可能破坏图的固有信息,限制了模型性能。
- 提出基于退火策略和分层码本的向量量化图自编码器,解决码本利用不足和空间稀疏性问题。
- 实验结果表明,该模型在链接预测和节点分类任务中显著优于现有方法,提升了图表示学习效果。
📝 摘要(中文)
图自监督学习近年来备受关注。然而,许多现有方法严重依赖于扰动,不适当的扰动可能会破坏图的固有信息。向量量化变分自编码器(VQ-VAE)是一种强大的自编码器,广泛应用于计算机视觉等领域;然而,它在图数据中的应用仍未得到充分探索。本文对图自编码器中的向量量化进行了实证分析,证明了其显著增强了模型捕获图拓扑结构的能力。此外,我们发现向量量化在图数据中应用时存在两个关键挑战:码本利用不足和码本空间稀疏性。针对第一个挑战,我们提出了一种基于退火的编码策略,该策略在训练的早期阶段促进广泛的码本利用,并随着训练的进行逐渐将重点转移到最有效的码上。针对第二个挑战,我们引入了一个分层双层码本,通过聚类捕获嵌入之间的关系。第二层码本连接相似的码,鼓励模型为图中具有相似特征和结构拓扑的节点学习更接近的嵌入。我们提出的模型在多个数据集上的自监督链接预测和节点分类任务中优于16种具有代表性的基线方法。
🔬 方法详解
问题定义:现有图自监督学习方法依赖于图结构的扰动,例如节点删除、边替换等。这些扰动如果选择不当,会破坏图的内在结构信息,导致学习到的图表示质量下降。此外,将向量量化(VQ)技术应用于图自编码器时,面临码本利用率低和码本空间稀疏的问题,限制了模型对复杂图结构的建模能力。
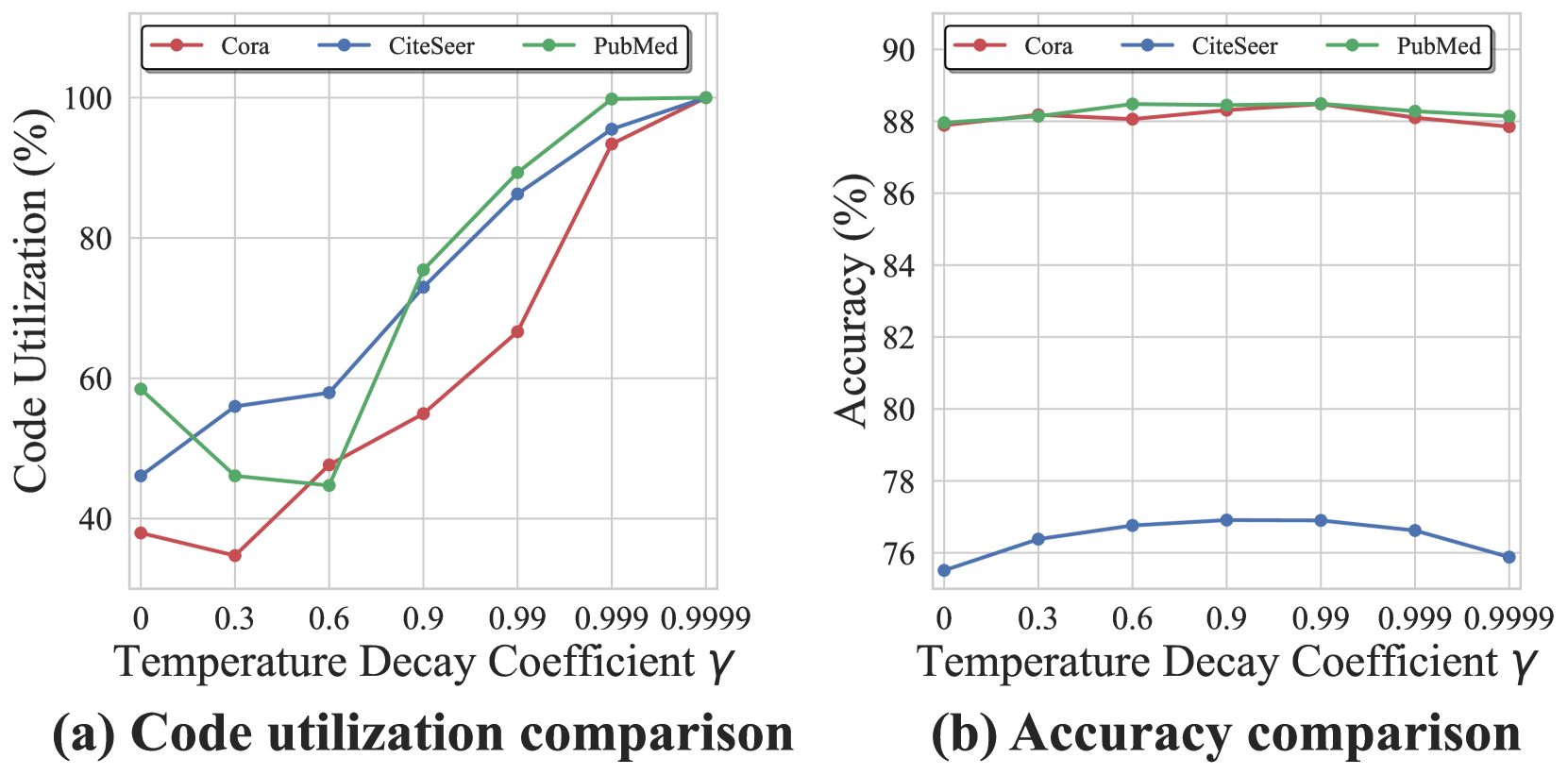
核心思路:本文的核心思路是通过引入分层向量量化机制,并结合退火策略,来提升图自编码器对图拓扑结构的捕获能力。具体来说,通过分层码本学习节点嵌入之间的关系,缓解码本空间稀疏问题;通过退火策略,在训练初期鼓励更广泛的码本使用,避免码本利用不足,从而提升模型整体性能。
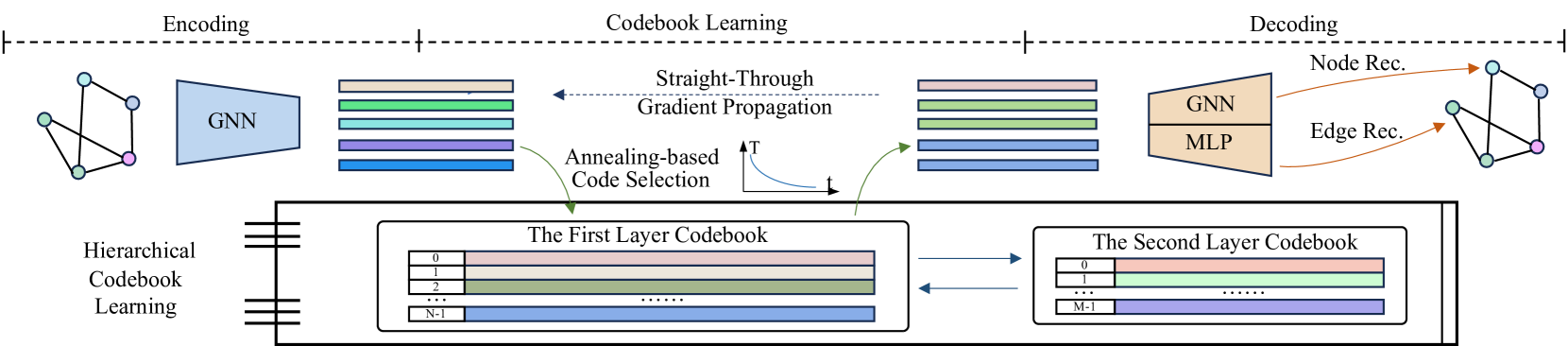
技术框架:该模型基于图自编码器(GAE)框架,主要包含编码器、分层向量量化模块和解码器三个部分。编码器将图结构和节点特征映射为节点嵌入。分层向量量化模块将节点嵌入量化到离散的码本空间。解码器利用量化后的节点嵌入重构图结构。整个框架采用自监督学习方式进行训练,目标是最小化重构误差。
关键创新:该论文的关键创新在于提出了分层向量量化和退火编码策略。分层向量量化通过两层码本结构,学习节点嵌入之间的关系,缓解了码本空间稀疏问题。退火编码策略在训练初期鼓励更广泛的码本使用,避免了码本利用不足的问题。这两种机制的结合,显著提升了模型对图拓扑结构的建模能力。与现有方法相比,该方法不需要依赖于图结构的扰动,避免了信息损失的风险。
关键设计:分层码本包含两层,第一层是常规的码本,第二层通过对第一层码本进行聚类得到。退火策略通过调整量化损失函数的权重来实现,在训练初期赋予更大的权重,鼓励更广泛的码本使用,随着训练的进行,逐渐降低权重,使模型专注于更有效的码。损失函数包括重构损失和量化损失两部分,重构损失用于衡量重构图与原始图之间的差异,量化损失用于优化码本和节点嵌入。
🖼️ 关键图片
📊 实验亮点
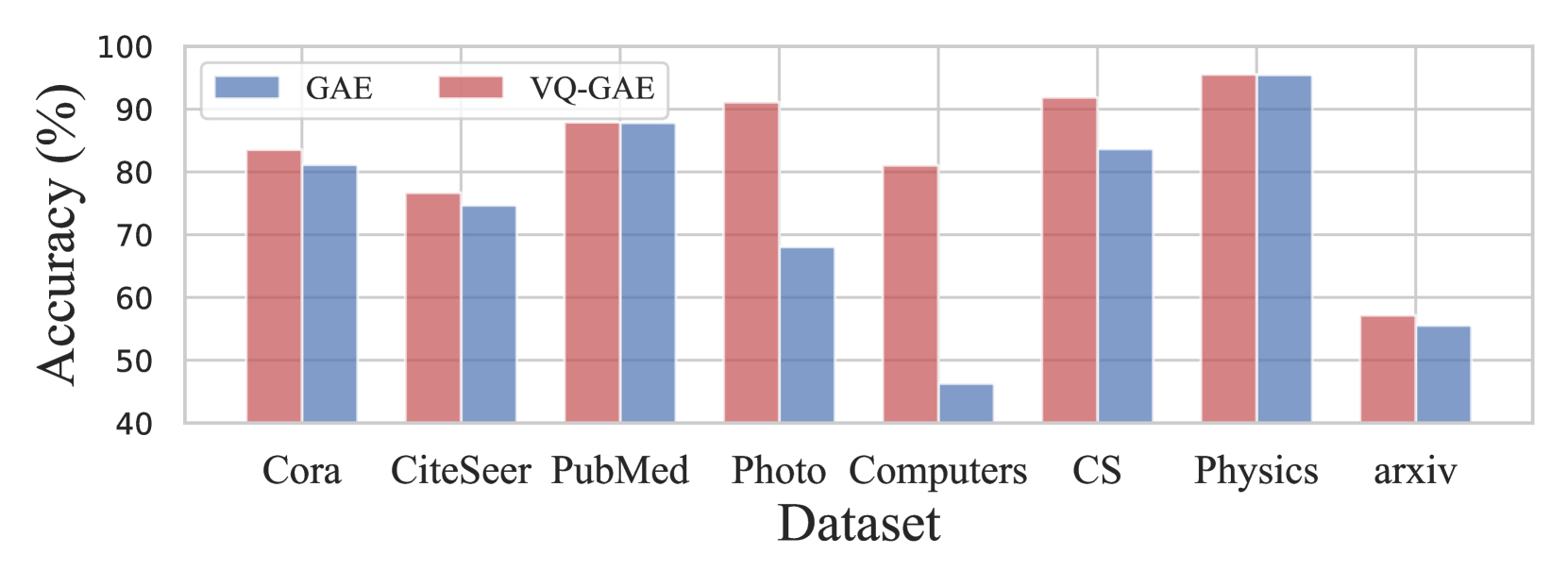
实验结果表明,该模型在链接预测和节点分类任务中显著优于16种基线方法。例如,在Cora数据集上,链接预测的AUC指标提升了3%以上。在CiteSeer数据集上,节点分类的准确率提升了2%以上。这些结果验证了该模型在图表示学习方面的有效性。
🎯 应用场景
该研究成果可应用于社交网络分析、生物信息学、推荐系统等领域。例如,在社交网络中,可以利用该模型学习用户之间的关系,进行用户聚类、好友推荐等任务。在生物信息学中,可以用于蛋白质相互作用网络分析、基因功能预测等。该研究有助于提升图数据的表示学习能力,为相关应用提供更准确、更有效的支持。
📄 摘要(原文)
Graph self-supervised learning has gained significant attention recently. However, many existing approaches heavily depend on perturbations, and inappropriate perturbations may corrupt the graph's inherent information. The Vector Quantized Variational Autoencoder (VQ-VAE) is a powerful autoencoder extensively used in fields such as computer vision; however, its application to graph data remains underexplored. In this paper, we provide an empirical analysis of vector quantization in the context of graph autoencoders, demonstrating its significant enhancement of the model's capacity to capture graph topology. Furthermore, we identify two key challenges associated with vector quantization when applying in graph data: codebook underutilization and codebook space sparsity. For the first challenge, we propose an annealing-based encoding strategy that promotes broad code utilization in the early stages of training, gradually shifting focus toward the most effective codes as training progresses. For the second challenge, we introduce a hierarchical two-layer codebook that captures relationships between embeddings through clustering. The second layer codebook links similar codes, encouraging the model to learn closer embeddings for nodes with similar features and structural topology in the graph. Our proposed model outperforms 16 representative baseline methods in self-supervised link prediction and node classification tasks across multiple datasets.