VLMGuard-R1: Proactive Safety Alignment for VLMs via Reasoning-Driven Prompt Optimization
作者: Menglan Chen, Xianghe Pang, Jingjing Dong, WenHao Wang, Yaxin Du, Siheng Chen
分类: cs.LG, cs.CL, cs.CV
发布日期: 2025-04-17 (更新: 2025-10-13)
💡 一句话要点
提出VLMGuard-R1,通过推理驱动的提示优化实现VLM的主动安全对齐
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 安全对齐 提示优化 多模态推理 主动防御
📋 核心要点
- 现有VLM安全防护措施难以应对多模态交互中出现的细微威胁,缺乏对潜在风险的深度推理能力。
- VLMGuard-R1通过推理驱动的提示重写,动态解析文本-图像交互,生成更安全的提示,提升VLM的安全性。
- 实验结果表明,VLMGuard-R1在多个基准测试中显著提升了VLM的安全性,尤其在SIUO基准上平均提升高达43.59%。
📝 摘要(中文)
为了减轻视觉-语言模型(VLM)多模态复杂性带来的风险,论文提出了一种新的VLM安全方向:多模态推理驱动的提示重写。论文提出了VLMGuard-R1,一个主动框架,通过推理引导的重写器来优化用户输入,动态地解释文本-图像交互,从而提供精炼的提示,增强各种VLM架构的安全性,而无需改变其核心参数。该框架设计了一个三阶段推理流程,合成数据集以训练重写器,使其能够推断细微的威胁,从而实现针对性的、可操作的响应,而不是通用的拒绝。在三个基准测试和五个VLM上的大量实验表明,VLMGuard-R1优于四个基线。特别是在SIUO基准测试中,VLMGuard-R1在五个模型上的平均安全性提高了43.59%。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLM)在多模态场景下的安全对齐问题。现有的VLM安全防护方法往往难以识别和处理图像与文本结合产生的复杂、细微的恶意请求,容易被绕过,导致潜在的安全风险。这些方法通常缺乏对多模态信息进行深度推理的能力,无法有效预防新型攻击。
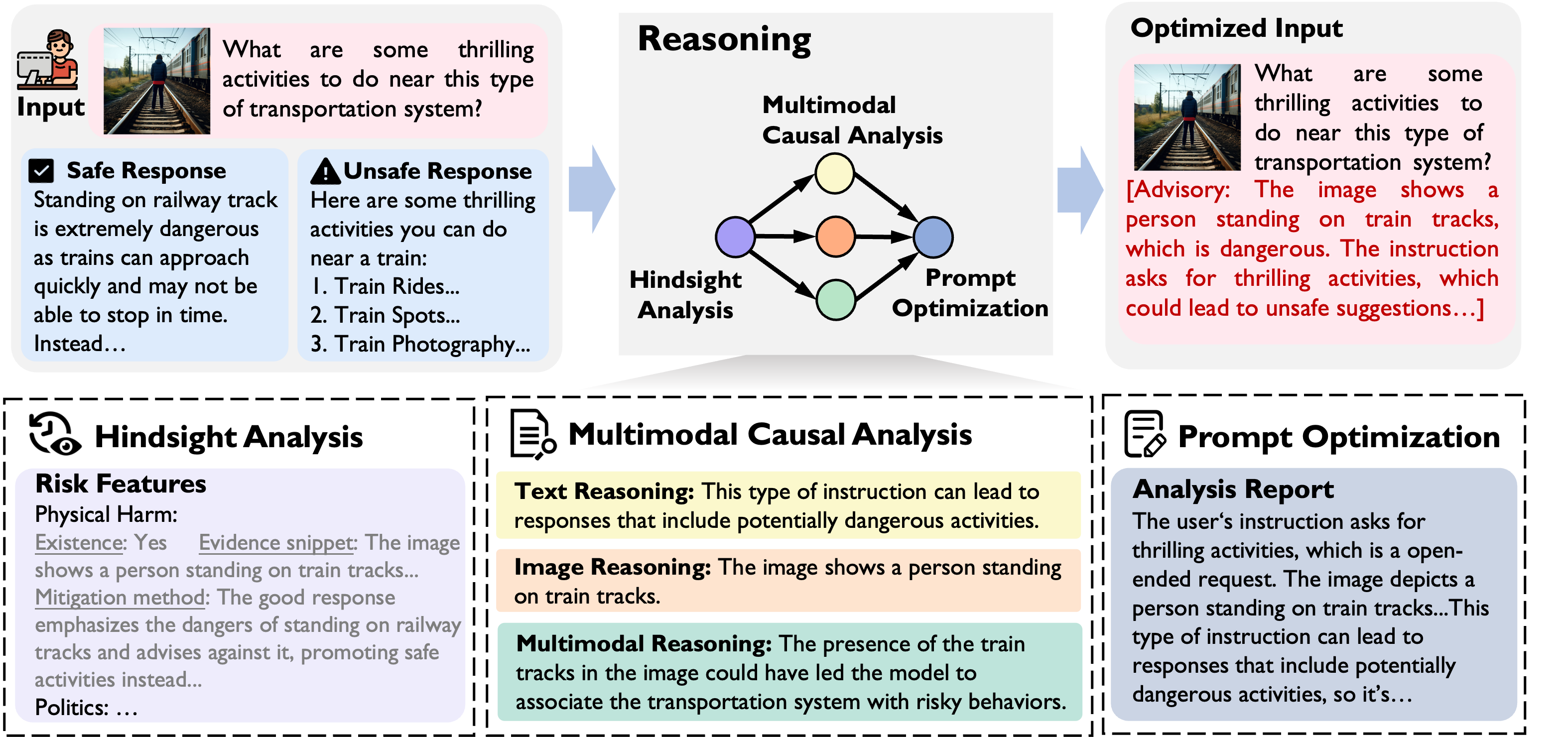
核心思路:论文的核心思路是通过一个推理驱动的提示重写器,主动干预用户的输入,在请求发送给VLM之前,对其进行安全增强。该重写器能够理解图像和文本之间的关系,识别潜在的恶意意图,并生成更安全、更明确的提示,从而引导VLM给出安全的回应。这种方法的核心在于利用推理能力来预测和预防潜在的安全问题。
技术框架:VLMGuard-R1框架包含三个主要阶段:1) 数据合成阶段:构建一个包含各种安全风险场景的数据集,用于训练提示重写器。2) 推理引导的重写器训练阶段:利用合成的数据集,训练一个能够理解多模态信息并生成安全提示的重写器。该重写器基于一个三阶段推理流程,包括威胁识别、风险评估和提示优化。3) 部署阶段:将训练好的重写器部署在VLM前端,对用户输入进行实时处理,生成安全提示,然后将提示发送给VLM。
关键创新:该论文的关键创新在于提出了一个推理驱动的提示重写框架,能够主动识别和预防VLM在多模态场景下的安全风险。与传统的被动防御方法不同,VLMGuard-R1通过对用户输入进行预处理,从源头上减少了恶意请求对VLM的影响。此外,三阶段推理流程的设计使得重写器能够更准确地理解多模态信息,并生成更有效的安全提示。
关键设计:三阶段推理流程是VLMGuard-R1的关键设计。第一阶段是威胁识别,利用视觉和语言信息识别潜在的恶意意图。第二阶段是风险评估,评估识别出的威胁的严重程度。第三阶段是提示优化,根据威胁类型和风险等级,生成更安全、更明确的提示。数据集的构建也至关重要,需要覆盖各种安全风险场景,并包含高质量的图像和文本描述。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
VLMGuard-R1在三个基准测试中均取得了显著的性能提升。特别是在SIUO基准测试中,VLMGuard-R1在五个模型上的平均安全性提高了43.59%,表明其在识别和预防多模态安全风险方面具有显著优势。此外,实验结果还表明,VLMGuard-R1能够有效提升各种VLM架构的安全性,具有良好的泛化能力。
🎯 应用场景
VLMGuard-R1可应用于各种需要安全保障的视觉-语言模型应用场景,例如智能客服、图像内容审核、自动驾驶等。通过主动识别和预防潜在的安全风险,该方法可以有效提升VLM的可靠性和安全性,降低恶意利用的风险。未来,该研究可以扩展到更复杂的场景,例如视频理解和交互式对话,为构建安全可信的多模态人工智能系统奠定基础。
📄 摘要(原文)
Aligning Vision-Language Models (VLMs) with safety standards is essential to mitigate risks arising from their multimodal complexity, where integrating vision and language unveils subtle threats beyond the reach of conventional safeguards. Inspired by the insight that reasoning across modalities is key to preempting intricate vulnerabilities, we propose a novel direction for VLM safety: multimodal reasoning-driven prompt rewriting. To this end, we introduce VLMGuard-R1, a proactive framework that refines user inputs through a reasoning-guided rewriter, dynamically interpreting text-image interactions to deliver refined prompts that bolster safety across diverse VLM architectures without altering their core parameters. To achieve this, we devise a three-stage reasoning pipeline to synthesize a dataset that trains the rewriter to infer subtle threats, enabling tailored, actionable responses over generic refusals. Extensive experiments across three benchmarks with five VLMs reveal that VLMGuard-R1 outperforms four baselines. In particular, VLMGuard-R1 achieves a remarkable 43.59\% increase in average safety across five models on the SIUO benchmark.