Watermarking Needs Input Repetition Masking
作者: David Khachaturov, Robert Mullins, Ilia Shumailov, Sumanth Dathathri
分类: cs.LG, cs.CL, cs.CR
发布日期: 2025-04-16
💡 一句话要点
LLM水印易被模仿:输入重复掩码是关键,需降低误报率并增加种子序列长度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 水印技术 模仿攻击 误报率 文本生成 安全性 鲁棒性
📋 核心要点
- 现有LLM水印技术易受“模仿”攻击,人类和未加水印的LLM可能无意中模仿水印信号,降低检测可靠性。
- 论文提出“模仿”概念,研究人类和LLM在对话中模仿水印信号的程度,揭示了现有水印技术的脆弱性。
- 研究表明,现有水印技术的误报率需要显著降低,并应使用更长的单词序列来提高水印的鲁棒性。
📝 摘要(中文)
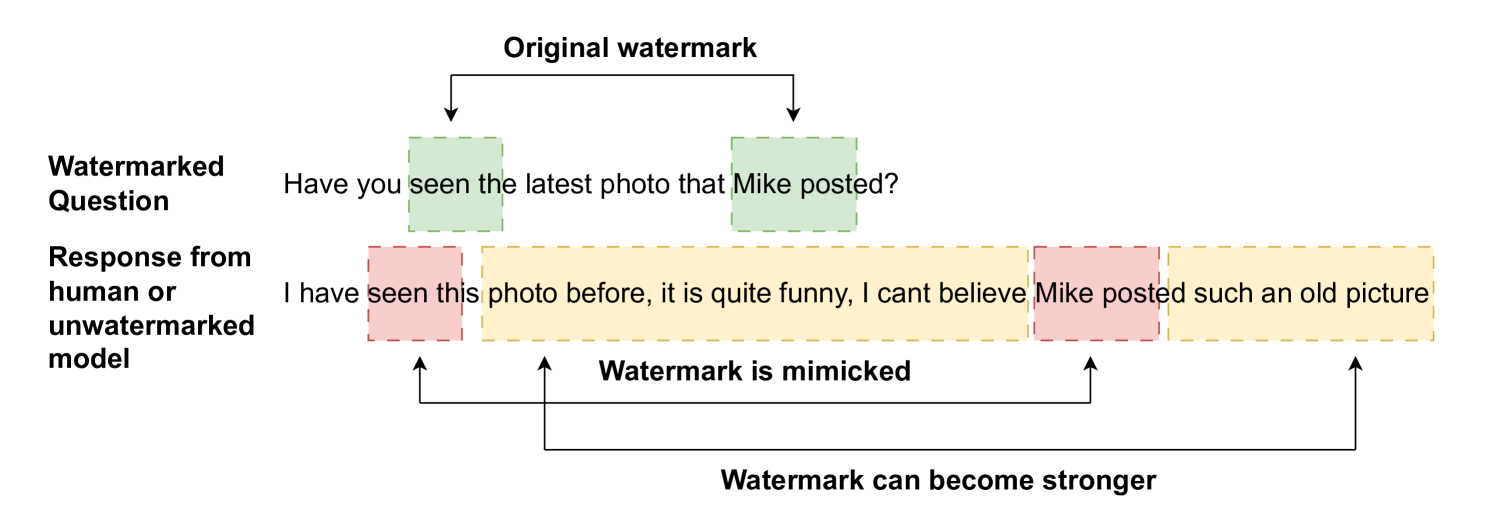
大型语言模型(LLM)的快速发展引发了对其潜在滥用的担忧,例如传播虚假信息。为了应对这一问题,出现了两种对策:基于机器学习的检测器,用于预测文本是否为合成文本;以及LLM水印技术,该技术巧妙地标记生成的文本以进行识别和归属。然而,众所周知,人类会在句法和词汇上调整语言以适应他们的对话伙伴。这意味着,人类或未加水印的LLM可能会无意中模仿LLM生成文本的属性,从而使对策变得不可靠。本文研究了这种对话适应发生的程度,称之为“模仿”,并证明人类和LLM最终都会进行模仿,甚至在看似不可能的情况下也会模仿水印信号。这挑战了当前学术界的假设,并表明为了使长期水印技术可靠,需要显著降低误报的可能性,同时应使用更长的单词序列来播种水印机制。
🔬 方法详解
问题定义:论文关注的是当前LLM水印技术在实际应用中面临的可靠性问题。现有的水印检测方法容易受到“模仿”攻击,即人类或未加水印的LLM可能会在不知情的情况下模仿已加水印文本的统计特征,从而导致误报,降低水印检测的准确性。这种模仿行为使得区分真实生成文本和被模仿的文本变得困难,威胁了水印技术的有效性。
核心思路:论文的核心思路是研究并量化“模仿”行为对LLM水印技术的影响。通过实验证明,人类和LLM都可能在对话中无意识地模仿水印信号,从而导致水印检测器产生误报。基于此,论文提出需要重新评估现有水印技术的安全性,并提出改进建议,以提高水印的鲁棒性和可靠性。
技术框架:论文主要通过实验来研究模仿行为。首先,设计实验场景,让人类和LLM在对话中进行交互,并观察他们是否会模仿水印文本的统计特征。然后,使用现有的水印检测器来检测这些文本,并评估误报率。最后,分析实验结果,提出改进水印技术的建议。没有明确的新的技术框架,更多的是一种实验分析和问题揭示。
关键创新:论文的关键创新在于首次提出了“模仿”这一概念,并证明了其对LLM水印技术的潜在威胁。以往的研究主要关注水印算法本身的设计,而忽略了实际应用中可能存在的模仿行为。通过实验,论文揭示了现有水印技术在面对模仿攻击时的脆弱性,为未来的研究方向提供了新的视角。
关键设计:论文的关键设计在于实验场景的设计,需要模拟真实的对话环境,并控制变量,以便准确地评估模仿行为的影响。具体的实验设置细节在摘要中没有详细描述,例如如何量化模仿程度,如何选择对话参与者,以及如何设计水印检测器等,这些都是影响实验结果的关键因素。此外,如何选择合适的水印算法和检测器也是一个重要的设计考虑。
🖼️ 关键图片


📊 实验亮点
论文通过实验证明,人类和LLM都可能在对话中无意识地模仿水印信号,导致现有水印检测器产生误报。这一发现挑战了当前学术界的假设,并表明现有水印技术在实际应用中可能存在严重的可靠性问题。具体的性能数据(如误报率)和对比基线在摘要中未给出,但研究结果强调了降低误报率和增加种子序列长度的重要性。
🎯 应用场景
该研究成果对LLM水印技术的实际应用具有重要意义。通过揭示“模仿”攻击的威胁,提醒研究人员和开发者重新评估现有水印技术的安全性,并开发更鲁棒的水印算法。这有助于提高LLM生成内容的溯源能力,防止恶意使用,并促进LLM技术的健康发展。未来的研究可以进一步探索更有效的防御模仿攻击的方法,例如设计更难以模仿的水印信号,或开发能够识别模仿行为的检测器。
📄 摘要(原文)
Recent advancements in Large Language Models (LLMs) raised concerns over potential misuse, such as for spreading misinformation. In response two counter measures emerged: machine learning-based detectors that predict if text is synthetic, and LLM watermarking, which subtly marks generated text for identification and attribution. Meanwhile, humans are known to adjust language to their conversational partners both syntactically and lexically. By implication, it is possible that humans or unwatermarked LLMs could unintentionally mimic properties of LLM generated text, making counter measures unreliable. In this work we investigate the extent to which such conversational adaptation happens. We call the concept $\textit{mimicry}$ and demonstrate that both humans and LLMs end up mimicking, including the watermarking signal even in seemingly improbable settings. This challenges current academic assumptions and suggests that for long-term watermarking to be reliable, the likelihood of false positives needs to be significantly lower, while longer word sequences should be used for seeding watermarking mechanisms.