Offline Learning and Forgetting for Reasoning with Large Language Models
作者: Tianwei Ni, Allen Nie, Sapana Chaudhary, Yao Liu, Huzefa Rangwala, Rasool Fakoor
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-15 (更新: 2025-10-28)
备注: Published in Transactions on Machine Learning Research (TMLR), 2025. Code: https://github.com/twni2016/llm-reasoning-uft
💡 一句话要点
通过离线学习与遗忘,提升大语言模型在复杂推理问题上的效率与准确率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 离线学习 推理时搜索 微调 学习与遗忘
📋 核心要点
- 大语言模型推理时搜索虽然提升了复杂问题求解能力,但计算成本和推理时间显著增加。
- 通过在成功和失败的推理路径上微调模型,将搜索能力直接融入模型,避免推理时搜索。
- 实验表明,该方法在提升成功率的同时,显著降低了推理时间,优于传统微调方法。
📝 摘要(中文)
本文提出了一种有效的方法,通过在从不同搜索方法中获得的未配对的成功(学习)和失败(遗忘)推理路径上微调大型语言模型,将搜索能力直接集成到模型中,从而增强模型解决复杂数学和推理问题的能力。一个关键的挑战是,简单的微调会降低模型的搜索能力;本文表明,可以通过较小的学习率来缓解这个问题。在具有挑战性的24点游戏和倒计时算术谜题上的大量实验表明,用搜索生成的数据替换CoT生成的数据进行离线微调,可以使成功率比推理时搜索基线提高约23%,同时将推理时间减少180倍。此外,本文提出的学习和遗忘目标始终优于监督微调和基于偏好的方法。
🔬 方法详解
问题定义:现有的大语言模型在解决复杂推理问题时,通常采用推理时搜索的方法,即生成并评估多个候选解决方案,以找到可行的推理路径。然而,这种方法显著增加了计算成本和推理时间,限制了其在实际应用中的部署。因此,如何降低推理成本,同时保持甚至提升模型的推理能力,是本文要解决的核心问题。
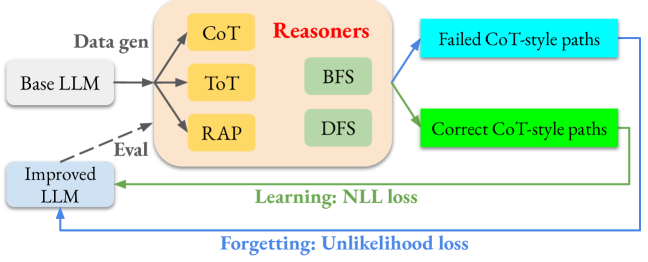
核心思路:本文的核心思路是将推理时搜索的能力通过离线微调的方式直接嵌入到模型中。具体来说,通过收集成功和失败的推理路径,并利用这些数据对模型进行微调,使模型能够学习到有效的推理策略,从而在推理时减少搜索的需要。这种方法的关键在于如何有效地利用成功和失败的推理路径,以及如何避免微调过程中可能出现的性能下降。
技术框架:该方法主要包含以下几个阶段:1) 数据收集:利用不同的搜索方法(例如,蒙特卡洛树搜索)生成大量的推理路径,并根据结果将其分为成功和失败两类。2) 数据预处理:对收集到的数据进行清洗和格式化,使其符合模型微调的要求。3) 模型微调:使用成功和失败的推理路径对预训练的大语言模型进行微调。微调的目标是使模型能够更好地识别和生成成功的推理路径,同时避免生成失败的推理路径。4) 模型评估:在测试集上评估微调后的模型的性能,包括成功率和推理时间。
关键创新:本文最重要的技术创新点在于提出了一个“学习与遗忘”的目标函数,即利用成功的推理路径进行学习,同时利用失败的推理路径进行遗忘。这种方法能够有效地提升模型的推理能力,并且避免了传统微调方法可能出现的性能下降问题。此外,本文还发现,使用较小的学习率进行微调可以进一步提升模型的性能。
关键设计:在模型微调阶段,本文采用了交叉熵损失函数作为学习目标,并对成功和失败的推理路径赋予不同的权重。具体来说,对于成功的推理路径,目标是最大化其出现的概率;对于失败的推理路径,目标是最小化其出现的概率。此外,本文还采用了较小的学习率(例如,1e-5)进行微调,以避免模型过拟合。在实验中,本文使用了预训练的GPT-3模型作为基础模型,并在Game-of-24和Countdown算术谜题数据集上进行了评估。
🖼️ 关键图片

📊 实验亮点
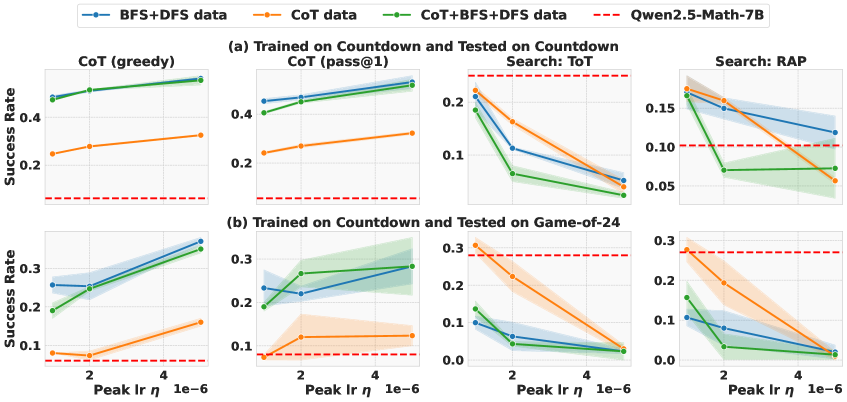
实验结果表明,使用搜索生成的数据进行离线微调,可以使成功率比推理时搜索基线提高约23%,同时将推理时间减少180倍。此外,本文提出的学习和遗忘目标始终优于监督微调和基于偏好的方法,证明了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的场景,例如数学问题求解、代码生成、游戏AI等。通过将推理能力嵌入到模型中,可以显著降低推理成本,提高响应速度,从而使大语言模型能够更好地服务于实际应用。
📄 摘要(原文)
Leveraging inference-time search in large language models has proven effective in further enhancing a trained model's capability to solve complex mathematical and reasoning problems. However, this approach significantly increases computational costs and inference time, as the model must generate and evaluate multiple candidate solutions to identify a viable reasoning path. To address this, we propose an effective approach that integrates search capabilities directly into the model by fine-tuning it on unpaired successful (learning) and failed reasoning paths (forgetting) derived from diverse search methods. A key challenge we identify is that naive fine-tuning can degrade the model's search capability; we show this can be mitigated with a smaller learning rate. Extensive experiments on the challenging Game-of-24 and Countdown arithmetic puzzles show that, replacing CoT-generated data with search-generated data for offline fine-tuning improves success rates by around 23% over inference-time search baselines, while reducing inference time by 180$\times$. On top of this, our learning and forgetting objective consistently outperforms both supervised fine-tuning and preference-based methods.