A Minimalist Approach to LLM Reasoning: from Rejection Sampling to Reinforce
作者: Wei Xiong, Jiarui Yao, Yuhui Xu, Bo Pang, Lei Wang, Doyen Sahoo, Junnan Li, Nan Jiang, Tong Zhang, Caiming Xiong, Hanze Dong
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-04-15 (更新: 2025-06-12)
💡 一句话要点
提出Reinforce-Rej,一种极简的LLM推理方法,提升KL效率和稳定性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 强化学习 推理微调 拒绝采样 策略梯度
📋 核心要点
- 现有基于强化学习的LLM推理微调方法,如GRPO,其有效性来源尚不明确,且算法复杂。
- 论文提出Reinforce-Rej,通过拒绝采样过滤完全正确和完全错误的样本,简化了策略梯度算法。
- 实验表明,Reinforce-Rej在KL效率和稳定性方面有所提升,是一种轻量级且有效的替代方案。
📝 摘要(中文)
强化学习(RL)已成为在大语言模型(LLM)上微调复杂推理任务的主流方法。在最近的方法中,GRPO因其在训练DeepSeek-R1等模型方面的经验性成功而脱颖而出,但其有效性的来源仍然知之甚少。本文从类似Reinforce算法的角度重新审视GRPO,并分析其核心组成部分。令人惊讶的是,我们发现一个简单的拒绝采样基线RAFT,仅在积极奖励的样本上进行训练,就能产生与GRPO和PPO相当的性能。我们的消融研究表明,GRPO的主要优势在于丢弃完全不正确响应的提示,而不是来自其奖励归一化。受此启发,我们提出了Reinforce-Rej,它是策略梯度的最小扩展,可以过滤完全不正确和完全正确的样本。Reinforce-Rej提高了KL效率和稳定性,是更复杂的RL算法的一种轻量级但有效的替代方案。我们提倡RAFT作为一种稳健且可解释的基线,并建议未来的研究应侧重于更原则性的负样本合并设计,而不是不加选择地依赖它们。我们的发现为未来基于奖励的LLM后训练工作提供了指导。
🔬 方法详解
问题定义:现有基于强化学习的LLM推理微调方法,例如GRPO,虽然在经验上取得了成功,但其有效性的来源并不完全清楚。此外,这些方法通常比较复杂,计算成本较高,并且可能存在训练不稳定等问题。论文旨在寻找一种更简单、更高效、更稳定的方法来微调LLM进行推理任务。
核心思路:论文的核心思路是,通过分析现有方法的关键组成部分,发现GRPO的优势主要来自于丢弃完全不正确的样本,而不是复杂的奖励归一化。因此,论文提出了一种基于拒绝采样的策略梯度算法Reinforce-Rej,该算法不仅丢弃完全不正确的样本,还丢弃完全正确的样本,从而更有效地利用数据,提高训练效率和稳定性。这样设计的目的是为了让模型更多地关注那些需要学习的“中间地带”的样本,避免过度拟合简单样本。
技术框架:Reinforce-Rej算法的整体流程如下:1) 使用LLM生成多个候选响应;2) 使用奖励模型对每个响应进行评分;3) 根据评分,使用拒绝采样策略,过滤掉完全正确和完全错误的样本;4) 使用剩余的样本,通过策略梯度算法更新LLM的参数。该框架的核心在于拒绝采样策略,它决定了哪些样本被用于训练。
关键创新:论文的关键创新在于提出了Reinforce-Rej算法,该算法是对传统策略梯度算法的最小扩展,但通过简单的拒绝采样策略,实现了与更复杂的算法相当甚至更好的性能。与现有方法相比,Reinforce-Rej更加简单、高效、稳定,并且更容易理解和解释。此外,论文还强调了RAFT(仅使用正样本训练)作为一种强大的基线,并指出未来研究应更注重负样本的原则性设计,而不是盲目地使用它们。
关键设计:Reinforce-Rej的关键设计在于拒绝采样的阈值设置。论文中需要确定一个阈值来判断哪些样本是“完全正确”和“完全错误”的。这个阈值的选择会影响算法的性能。此外,损失函数仍然是标准的策略梯度损失函数,但只在经过拒绝采样过滤后的样本上计算。
🖼️ 关键图片
📊 实验亮点
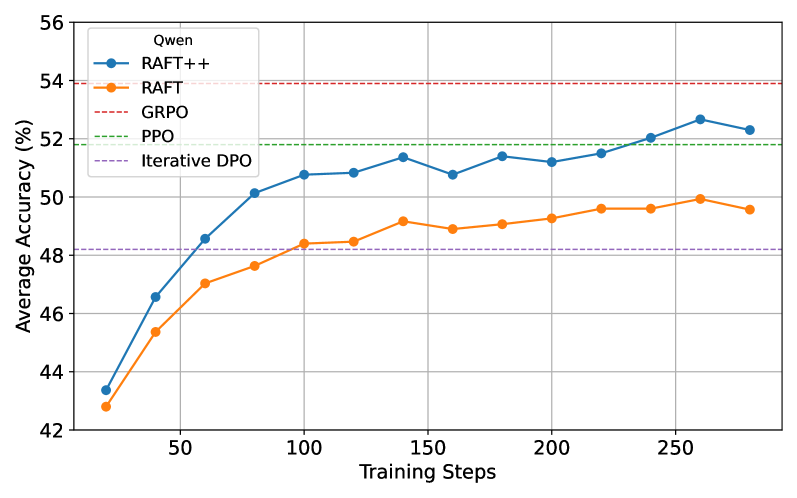
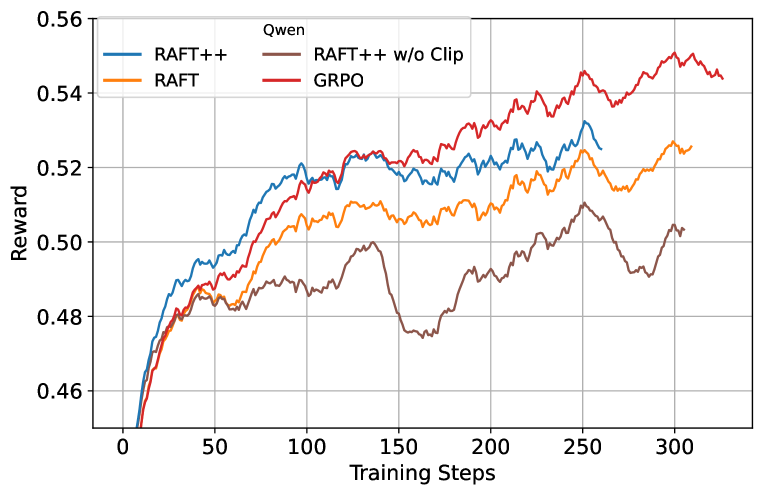
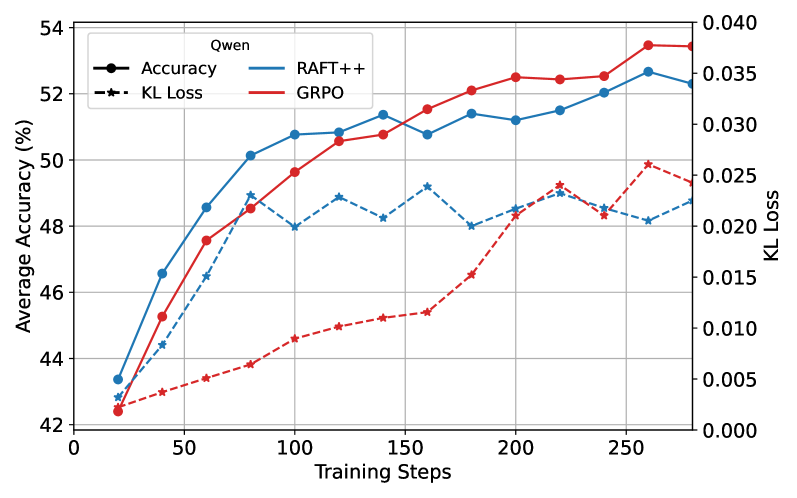
实验结果表明,简单的拒绝采样基线RAFT可以达到与GRPO和PPO相当的性能。Reinforce-Rej算法通过过滤完全正确和完全错误的样本,提高了KL效率和稳定性,成为更复杂的RL算法的一种轻量级但有效的替代方案。消融实验表明,GRPO的主要优势在于丢弃完全不正确响应的提示。
🎯 应用场景
该研究成果可应用于各种需要LLM进行推理的任务,例如问答、数学问题求解、代码生成等。通过使用Reinforce-Rej算法,可以更高效、更稳定地微调LLM,提高其推理能力。该方法具有轻量级的特点,易于部署和应用,有望推动LLM在实际场景中的广泛应用。
📄 摘要(原文)
Reinforcement learning (RL) has become a prevailing approach for fine-tuning large language models (LLMs) on complex reasoning tasks. Among recent methods, GRPO stands out for its empirical success in training models such as DeepSeek-R1, yet the sources of its effectiveness remain poorly understood. In this work, we revisit GRPO from a reinforce-like algorithm perspective and analyze its core components. Surprisingly, we find that a simple rejection sampling baseline, RAFT, which trains only on positively rewarded samples, yields competitive performance than GRPO and PPO. Our ablation studies reveal that GRPO's main advantage arises from discarding prompts with entirely incorrect responses, rather than from its reward normalization. Motivated by this insight, we propose Reinforce-Rej, a minimal extension of policy gradient that filters both entirely incorrect and entirely correct samples. Reinforce-Rej improves KL efficiency and stability, serving as a lightweight yet effective alternative to more complex RL algorithms. We advocate RAFT as a robust and interpretable baseline, and suggest that future advances should focus on more principled designs for incorporating negative samples, rather than relying on them indiscriminately. Our findings provide guidance for future work in reward-based LLM post-training.