Enhancing Ultra-Low-Bit Quantization of Large Language Models Through Saliency-Aware Partial Retraining
作者: Deyu Cao, Samin Aref
分类: cs.LG, cs.CL
发布日期: 2025-04-14 (更新: 2025-07-30)
备注: This is a post-peer-review accepted manuscript from the proceedings of the 22nd International Conference on Modeling Decisions for Artificial Intelligence (MDAI'25). The publisher authenticated version and full citation details are available on Springer's website (LNAI 15957). https://doi.org/10.1007/978-3-032-00891-6_28
DOI: 10.1007/978-3-032-00891-6_28
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于显著性感知的局部重训练方法,提升大语言模型超低比特量化性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 量化 超低比特量化 模型压缩 显著性感知 局部重训练 正则化 LLaMA
📋 核心要点
- 现有大语言模型量化方法在超低比特设置下存在显著的精度损失,限制了其在资源受限环境中的部署。
- 提出一种基于显著性感知的局部重训练方法,通过正则化项优先保留量化过程中最重要的参数,从而提升精度。
- 实验结果表明,该方法在LLaMA 7B和13B模型上,显著降低了超低比特量化带来的精度损失。
📝 摘要(中文)
大型语言模型的广泛应用引发了对其推理过程中资源消耗的环境和经济担忧。为了降低能耗,量化等模型压缩技术通过用低精度量化值替换高精度参数来缩小模型尺寸,但可能导致性能下降。ApiQ方法在最小的内存和时间开销下实现了卓越的精度保持。本文研究了两种思路,以扩展超低比特量化中的性能,超越ApiQ的水平。首先,将现有的量化感知训练技术与ApiQ的局部训练相结合,结果表明在有限的训练数据和冻结权重下,其性能并未超过基线ApiQ方法。其次,提出了一种基于ApiQ的超低比特量化方法,该方法依赖于一个显著性感知正则化项,该正则化项优先保留量化期间影响最大的参数。在LLaMA 7B和13B基准测试上的实验表明,该方法分别将ApiQ的精度下降降低了10.85%和7.54%。
🔬 方法详解
问题定义:现有的大语言模型量化方法,尤其是在超低比特量化(例如,低于4比特)时,会遭受显著的精度损失。ApiQ虽然是一种有效的量化方法,但在极低比特设置下仍然存在性能下降的问题。现有的量化感知训练方法通常需要大量的计算资源和时间,并且可能需要完整模型的重新训练,这对于大型语言模型来说是不切实际的。
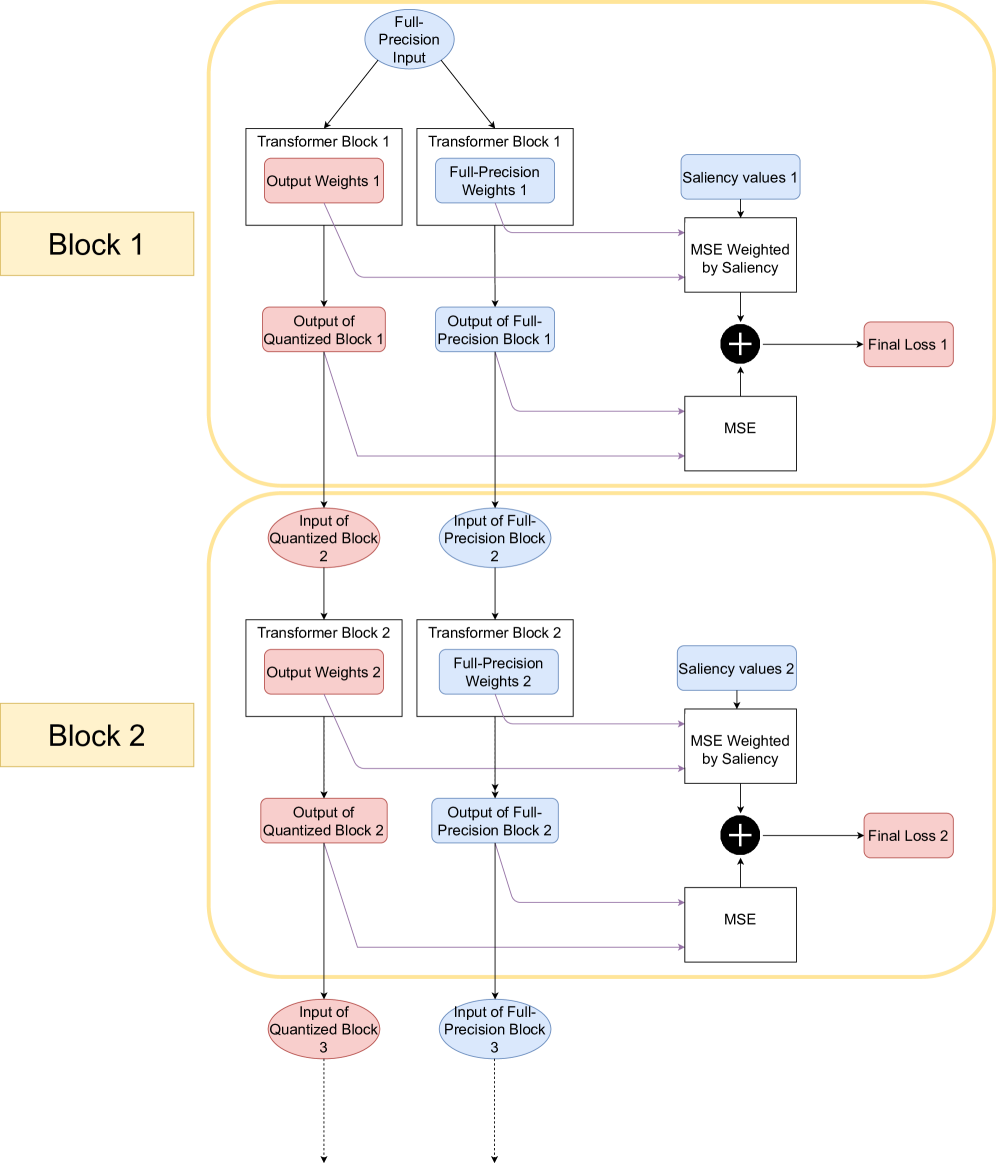
核心思路:本文的核心思路是利用参数的显著性(saliency)来指导量化过程,从而在超低比特量化中更好地保留模型的关键信息。通过引入一个显著性感知的正则化项,使得在量化过程中,对模型性能影响较大的参数能够得到更好的保护,从而减少精度损失。这种方法避免了完全重新训练模型,降低了计算成本。
技术框架:该方法建立在ApiQ的基础上,主要包含以下几个阶段:1) 使用ApiQ进行初始量化;2) 计算模型参数的显著性得分;3) 在ApiQ的局部训练过程中,引入一个基于显著性得分的正则化项,该正则化项惩罚对显著性高的参数的量化误差;4) 进行局部重训练,优化量化后的模型参数。
关键创新:该方法最重要的技术创新点在于引入了显著性感知的正则化项。与传统的量化方法不同,该方法不是平等地对待所有参数,而是根据其对模型性能的影响程度进行差异化处理。通过优先保留对模型性能影响最大的参数,从而在超低比特量化中实现了更好的精度保持。
关键设计:显著性得分的计算方式是一个关键设计。论文中可能使用了某种梯度相关的度量来评估参数的显著性。正则化项的设计也至关重要,它需要能够有效地惩罚对显著性高的参数的量化误差,同时避免过度正则化。具体的损失函数形式和正则化系数的选择会影响最终的量化效果。此外,局部重训练的训练数据选择和训练轮数也是需要仔细调整的超参数。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在LLaMA 7B和13B模型上,分别将ApiQ的精度下降降低了10.85%和7.54%。这意味着在相同的量化比特数下,该方法能够显著提高模型的性能,使其更接近于原始模型的精度。该方法在不需要完全重新训练模型的情况下,实现了显著的性能提升,具有很高的实用价值。
🎯 应用场景
该研究成果可应用于各种资源受限的场景,例如移动设备、边缘计算设备等。通过对大型语言模型进行超低比特量化,可以在这些设备上部署计算密集型的AI应用,例如智能助手、机器翻译、文本摘要等,从而提高用户体验并降低能耗。此外,该方法还可以用于降低云计算中心的推理成本,提高资源利用率。
📄 摘要(原文)
The growing use of large language models has raised environmental and economic concerns about their intensity of resource usage during inference. Serving these models to each user requires substantial energy and water for cooling. Model compression techniques like quantization can shrink large language models and make them more resource efficient at the cost of potential performance degradation. Quantization methods compress model size through replacing their high-precision parameters by quantized values of lower precision. Among existing methods, the ApiQ method achieves superior accuracy preservation at minimal memory and time overhead. We investigate two ideas to extend performance in ultra-low-bit quantization beyond ApiQ's level. First, we look into combining existing quantization-aware training techniques with ApiQ's partial training. We show that this does not outperform the baseline ApiQ method with limited training data and frozen weights. This leads to two key insights: (1) The substantial representational capacity that is gained through full retraining is unlikely to be feasible through partial training. (2) This gain may depend on using a large and diverse dataset in quantization-aware training. Second, through a novel approach informed by the two insights, we propose an ultra-low-bit quantization method that builds upon ApiQ and extends its performance without the need for full retraining. This publicly available method relies on a saliency-aware regularization term that prioritizes preserving the most impactful parameters during quantization. Our experiments on LLaMA 7B and 13B benchmarks demonstrate that our method reduces the ApiQ's accuracy degradation by 10.85% and 7.54% respectively. A Python implementation of the proposed quantization method is publicly available on GitHub https://github.com/TokuyuSou/ULB-SAPR.