Efficient Process Reward Model Training via Active Learning
作者: Keyu Duan, Zichen Liu, Xin Mao, Tianyu Pang, Changyu Chen, Qiguang Chen, Michael Qizhe Shieh, Longxu Dou
分类: cs.LG, cs.AI
发布日期: 2025-04-14
备注: 15 pages, 4 figures
💡 一句话要点
提出ActPRM主动学习方法,高效训练过程奖励模型,降低标注成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 过程奖励模型 主动学习 大型语言模型 数据标注 数学推理 不确定性估计 模型训练
📋 核心要点
- 大规模语言模型的过程奖励模型训练需要大量标注数据,人工和LLM标注成本高昂。
- ActPRM通过主动学习,选择模型不确定性高的样本进行标注,降低数据标注量。
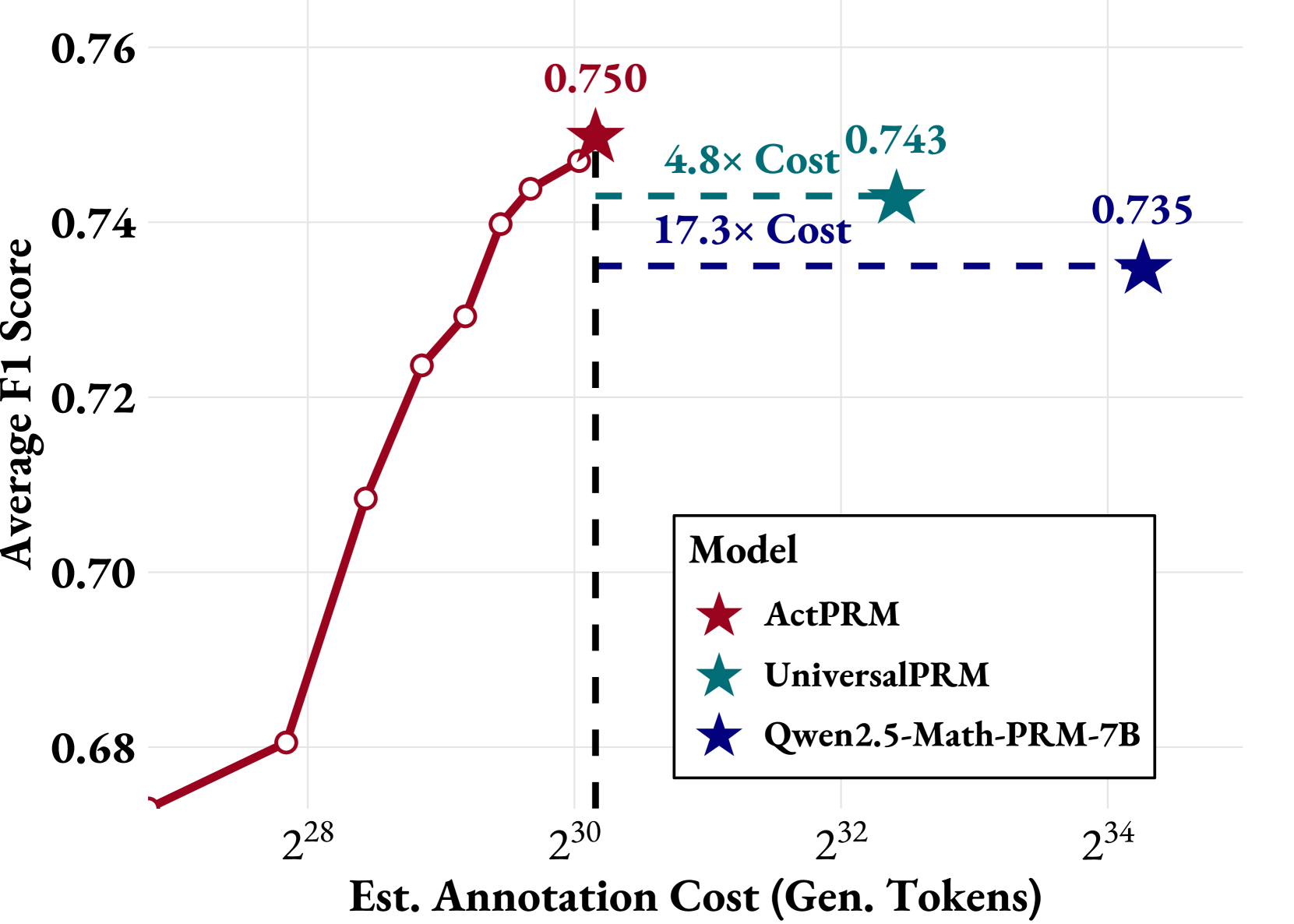
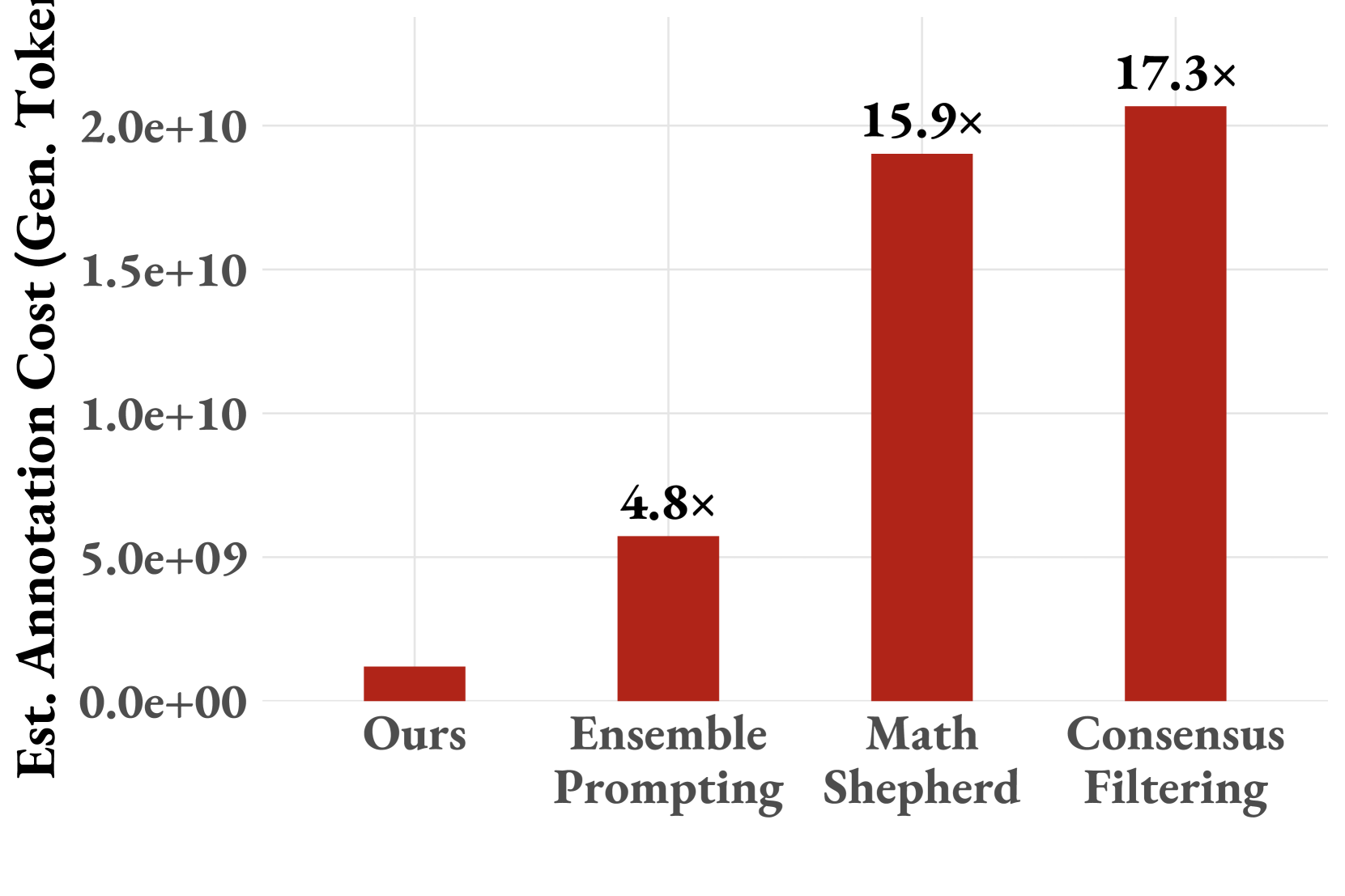
- 实验表明,ActPRM在减少50%标注的情况下,性能与传统微调相当甚至更好,并在数学推理任务上取得SOTA。
📝 摘要(中文)
过程奖励模型(PRM)为大型语言模型(LLM)提供步骤级别的监督,但扩展训练数据标注对人类和LLM来说仍然具有挑战性。为了解决这个限制,我们提出了一种主动学习方法ActPRM,它主动选择最不确定的样本进行训练,从而大大降低了标注成本。在训练过程中,我们使用PRM在前向传播后估计不确定性,只保留高度不确定的数据。然后,一个能力强但成本高昂的推理模型会标注这些数据。然后,我们计算关于标签的损失并更新PRM的权重。在一个基于池的主动学习设置中,我们将ActPRM与vanilla微调进行比较,结果表明ActPRM减少了50%的标注,但实现了相当甚至更好的性能。除了标注效率之外,我们还通过ActPRM过滤了超过100万条数学推理轨迹,保留了60%的数据,从而进一步提升了经过主动训练的PRM。随后对该选择的数据集进行训练,在ProcessBench (75.0%)和PRMBench (65.5%)上产生了新的最先进(SOTA)的PRM,与相同大小的模型相比。
🔬 方法详解
问题定义:论文旨在解决过程奖励模型(PRM)训练中数据标注成本高的问题。现有的PRM训练方法通常需要大量人工或LLM标注数据,这限制了PRM在实际应用中的扩展性。尤其是在复杂任务中,标注过程的每一步骤都需要耗费大量资源。
核心思路:论文的核心思路是利用主动学习,选择对PRM模型来说最具有信息量的样本进行标注。具体来说,就是选择模型预测不确定性最高的样本。这样可以最大限度地利用有限的标注资源,提高PRM模型的训练效率。
技术框架:ActPRM的整体框架包含以下几个主要阶段: 1. PRM预测: 使用当前的PRM模型对所有候选样本进行预测。 2. 不确定性估计: 基于PRM的预测结果,估计每个样本的不确定性。 3. 样本选择: 选择不确定性最高的样本子集进行标注。 4. 标注: 使用高成本但高质量的标注模型(例如更强大的LLM)对选定的样本进行标注。 5. PRM更新: 使用标注后的数据更新PRM模型的权重。
关键创新:ActPRM的关键创新在于将主动学习引入到PRM的训练过程中。与传统的被动学习方法不同,ActPRM能够根据模型自身的学习状态,动态地选择最有价值的样本进行标注。这种方法能够显著提高标注效率,降低训练成本。
关键设计:ActPRM的关键设计包括: 1. 不确定性度量: 如何准确地估计样本的不确定性是关键。论文可能采用了例如熵、方差等指标来衡量不确定性。 2. 样本选择策略: 如何选择不确定性最高的样本。可以选择固定数量的样本,也可以设置一个不确定性阈值。 3. 标注模型: 选择合适的标注模型也很重要。需要权衡标注质量和标注成本。论文中使用了一个能力强但成本高昂的推理模型进行标注。 4. 损失函数: 使用标注后的数据更新PRM模型时,需要选择合适的损失函数。常见的选择包括交叉熵损失、均方误差损失等。具体选择取决于PRM模型的输出形式和任务目标。
🖼️ 关键图片

📊 实验亮点
ActPRM在ProcessBench和PRMBench上取得了显著的性能提升。实验结果表明,ActPRM能够减少50%的标注量,同时保持甚至提升模型性能。通过ActPRM过滤并训练后的PRM在ProcessBench上达到了75.0%的准确率,在PRMBench上达到了65.5%的准确率,刷新了同等规模模型在该任务上的SOTA记录。
🎯 应用场景
ActPRM可应用于各种需要过程奖励模型进行步骤级监督的场景,例如数学推理、代码生成、机器人任务规划等。通过降低标注成本,ActPRM使得PRM能够更容易地应用于实际问题,并提升LLM在复杂任务中的表现。该方法在教育、自动化等领域具有广泛的应用前景。
📄 摘要(原文)
Process Reward Models (PRMs) provide step-level supervision to large language models (LLMs), but scaling up training data annotation remains challenging for both humans and LLMs. To address this limitation, we propose an active learning approach, ActPRM, which proactively selects the most uncertain samples for training, substantially reducing labeling costs. During training, we use the PRM to estimate uncertainty after the forward pass, retaining only highly uncertain data. A capable yet costly reasoning model then labels this data. Then we compute the loss with respect to the labels and update the PRM's weights. We compare ActPRM vs. vanilla fine-tuning, on a pool-based active learning setting, demonstrating that ActPRM reduces 50% annotation, but achieving the comparable or even better performance. Beyond annotation efficiency, we further advance the actively trained PRM by filtering over 1M+ math reasoning trajectories with ActPRM, retaining 60% of the data. A subsequent training on this selected dataset yields a new state-of-the-art (SOTA) PRM on ProcessBench (75.0%) and PRMBench (65.5%) compared with same sized models.