M1: Towards Scalable Test-Time Compute with Mamba Reasoning Models
作者: Junxiong Wang, Wen-Ding Li, Daniele Paliotta, Daniel Ritter, Alexander M. Rush, Tri Dao
分类: cs.LG
发布日期: 2025-04-14 (更新: 2025-09-09)
备注: Code is available https://github.com/jxiw/M1
💡 一句话要点
提出基于Mamba的混合线性RNN推理模型M1,提升测试时计算效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Mamba 线性RNN 推理模型 知识蒸馏 强化学习 长链思维 自洽性投票
📋 核心要点
- Transformer模型在扩展上下文长度时面临计算复杂度和内存需求的限制,阻碍了其在复杂推理任务中的应用。
- 论文提出基于Mamba架构的混合线性RNN推理模型M1,通过知识蒸馏和强化学习训练,实现内存高效的推理。
- 实验结果表明,M1在推理速度和准确率上均优于现有模型,尤其是在固定时间预算下,通过自洽性投票实现了更高的准确率。
📝 摘要(中文)
本文提出了一种新型的混合线性RNN推理模型M1,该模型基于Mamba架构,旨在实现内存高效的推理,从而扩展测试时计算规模。该方法利用现有推理模型的知识蒸馏,并通过强化学习训练进一步提升性能。在AIME和MATH基准测试上的实验结果表明,M1不仅优于之前的线性RNN模型,而且在相似规模下,性能与最先进的Deepseek R1蒸馏推理模型相媲美。与高性能通用推理引擎vLLM相比,M1的生成速度提高了3倍以上。凭借吞吐量加速,M1在使用自洽性投票的情况下,在固定的生成时间预算下,实现了比DeepSeek R1蒸馏Transformer推理模型更高的准确率。总而言之,我们引入了一种混合Mamba推理模型,并提供了一种更有效的方法来扩展使用自洽性或长链思维推理的测试时生成。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)通过扩展测试时计算,例如使用长链思维(Chain-of-Thought)推理,在解决复杂的数学问题方面取得了显著进展。然而,基于Transformer的模型由于其二次计算复杂度和线性内存需求,在扩展上下文长度方面存在固有的局限性,这限制了它们在需要长程依赖的推理任务中的应用。
核心思路:本文的核心思路是利用Mamba架构构建一种新型的混合线性RNN推理模型M1,Mamba架构具有线性复杂度,从而能够更有效地处理长序列。通过结合知识蒸馏和强化学习,M1能够学习到现有推理模型的知识,并进一步优化其推理能力。这种设计旨在克服Transformer模型的局限性,实现更高效、更准确的推理。
技术框架:M1的整体框架包括以下几个主要阶段:首先,使用知识蒸馏从现有的推理模型中学习知识。然后,使用强化学习对M1进行微调,以优化其在特定推理任务上的性能。最后,使用自洽性投票等技术来进一步提高推理的准确性。该框架的核心是Mamba架构,它允许M1以线性复杂度处理长序列,从而实现内存高效的推理。
关键创新:本文最重要的技术创新点在于将Mamba架构应用于推理模型。与Transformer模型相比,Mamba架构具有线性复杂度,这使得M1能够更有效地处理长序列,从而在需要长程依赖的推理任务中表现更好。此外,通过结合知识蒸馏和强化学习,M1能够学习到现有推理模型的知识,并进一步优化其推理能力。
关键设计:M1的关键设计包括:1) 使用Mamba架构作为其核心组件,以实现线性复杂度的推理;2) 使用知识蒸馏从现有的推理模型中学习知识;3) 使用强化学习对M1进行微调,以优化其在特定推理任务上的性能;4) 使用自洽性投票等技术来进一步提高推理的准确性。具体的参数设置、损失函数和网络结构等细节在论文中进行了详细描述,但此处无法完全展开。
🖼️ 关键图片
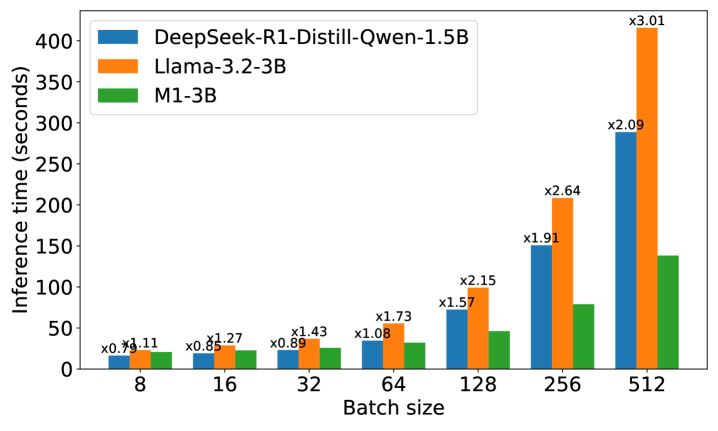
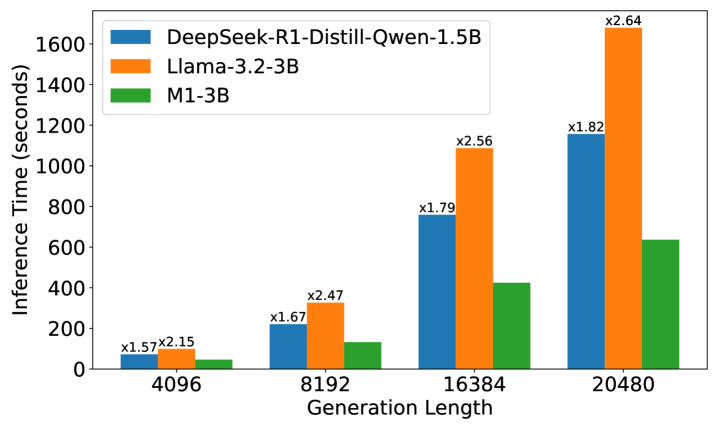
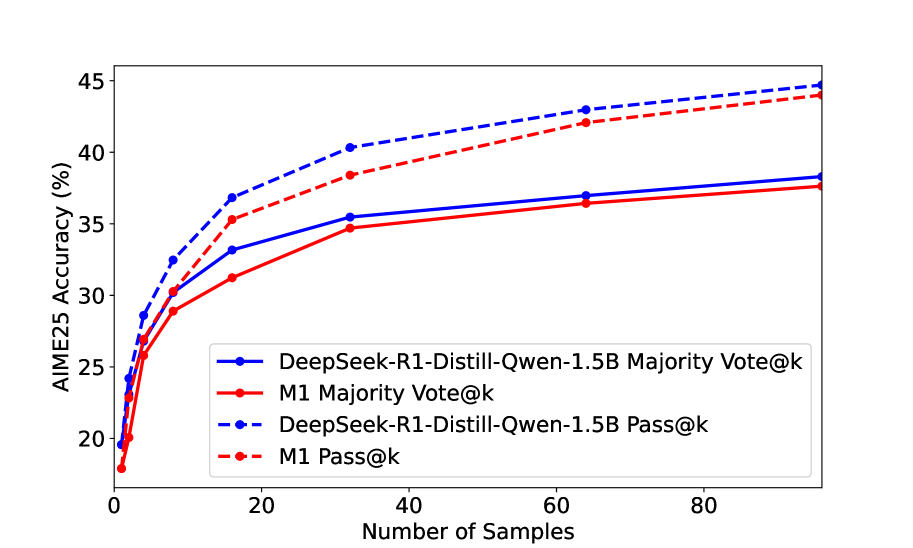
📊 实验亮点
M1在AIME和MATH基准测试中表现出色,不仅超越了之前的线性RNN模型,而且在相似规模下与最先进的Deepseek R1蒸馏推理模型相媲美。更重要的是,M1的生成速度比同等规模的Transformer模型快3倍以上,并且在固定生成时间预算下,通过自洽性投票实现了更高的准确率。
🎯 应用场景
该研究成果可应用于需要复杂推理和长程依赖的各种领域,例如数学问题求解、代码生成、自然语言理解等。通过提高推理效率和准确性,M1有望在这些领域实现更强大的AI应用,例如自动定理证明、智能编程助手和更高级的对话系统。
📄 摘要(原文)
Effective reasoning is crucial to solving complex mathematical problems. Recent large language models (LLMs) have boosted performance by scaling test-time computation through long chain-of-thought reasoning. However, transformer-based models are inherently limited in extending context length due to their quadratic computational complexity and linear memory requirements. In this paper, we introduce a novel hybrid linear RNN reasoning model, M1, built on the Mamba architecture, which allows memory-efficient inference. Our approach leverages a distillation process from existing reasoning models and is further enhanced through RL training. Experimental results on the AIME and MATH benchmarks show that M1 not only outperforms previous linear RNN models but also matches the performance of state-of-the-art Deepseek R1 distilled reasoning models at a similar scale. We also compare our generation speed with a highly performant general purpose inference engine, vLLM, and observe more than a 3x speedup compared to a same size transformer. With throughput speedup, we are able to achieve higher accuracy compared to DeepSeek R1 distilled transformer reasoning models under a fixed generation time budget using self-consistency voting. Overall, we introduce a hybrid Mamba reasoning model and provide a more effective approach to scaling test-time generation using self-consistency or long chain of thought reasoning.