On the Value of Cross-Modal Misalignment in Multimodal Representation Learning
作者: Yichao Cai, Yuhang Liu, Erdun Gao, Tianjiao Jiang, Zhen Zhang, Anton van den Hengel, Javen Qinfeng Shi
分类: cs.LG, cs.CV
发布日期: 2025-04-14 (更新: 2025-09-26)
备注: NeurIPS 2025 camera-ready version (with checklist removed for presentation clarity)
💡 一句话要点
通过建模跨模态不对齐,提升多模态表征学习的性能与可解释性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表征学习 跨模态不对齐 对比学习 潜在变量模型 选择偏差 扰动偏差 图像文本对齐
📋 核心要点
- 现有MMCL方法假设模态对齐,但现实数据存在不对齐问题,导致表征学习效果下降。
- 论文提出基于潜在变量模型的跨模态不对齐建模方法,区分选择偏差和扰动偏差。
- 理论分析和实验验证表明,MMCL学习到的表征能捕捉对不对齐偏差不变的语义信息。
📝 摘要(中文)
多模态表征学习,例如使用图像-文本对的多模态对比学习(MMCL),旨在通过对齐跨模态线索来学习强大的表征。这种方法依赖于一个核心假设,即示例图像-文本对构成同一概念的两种表征。然而,最近的研究表明,真实世界的数据集通常表现出跨模态不对齐。关于如何解决这个问题存在两种不同的观点:一种建议缓解不对齐,另一种建议利用它。本文旨在调和这些看似对立的观点,并为从业者提供实践指南。通过使用潜在变量模型,本文通过引入两种特定机制来形式化跨模态不对齐:选择偏差(文本中缺少某些语义变量)和扰动偏差(语义变量被改变)——这两种偏差都会导致数据对中的不对齐。理论分析表明,在温和的假设下,MMCL学习到的表征精确地捕捉了与对选择和扰动偏差不变的语义变量子集相关的信息。这为理解不对齐提供了一个统一的视角。基于此,本文进一步提供了关于不对齐如何指导真实世界ML系统设计的可行性见解。通过在合成数据和真实图像-文本数据集上的大量实证研究,验证了理论发现,揭示了跨模态不对齐对多模态表征学习的细微影响。
🔬 方法详解
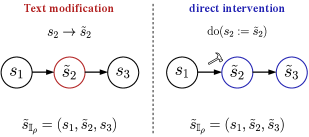
问题定义:多模态对比学习(MMCL)依赖于模态对齐的假设,但在实际应用中,图像-文本数据对往往存在不对齐现象。这种不对齐可能是由于文本描述不完整(选择偏差)或描述错误(扰动偏差)造成的。现有方法要么试图消除不对齐,要么直接利用不对齐,但缺乏对不对齐本质的深入理解。
核心思路:论文的核心思路是通过引入潜在变量模型来形式化地描述跨模态不对齐。该模型将图像和文本视为潜在语义变量的不同观测结果,并使用选择偏差和扰动偏差来模拟不对齐现象。通过分析该模型,论文旨在揭示MMCL在存在不对齐的情况下实际学习到的信息。
技术框架:论文构建了一个包含图像、文本和潜在语义变量的生成模型。该模型包含以下几个关键部分: 1. 潜在语义变量:表示图像和文本所描述的真实世界概念。 2. 选择偏差:模拟文本中缺失某些语义变量的情况。 3. 扰动偏差:模拟文本中语义变量被改变的情况。 4. 图像和文本生成器:将潜在语义变量映射到图像和文本模态。
关键创新:论文最重要的创新在于对跨模态不对齐进行了形式化的建模,并从理论上分析了MMCL在存在不对齐的情况下学习到的表征。具体来说,论文证明了MMCL学习到的表征能够捕捉到对选择偏差和扰动偏差不变的语义变量子集。这一发现为理解和处理跨模态不对齐提供了一个新的视角。
关键设计:论文的关键设计包括: 1. 使用潜在变量模型来表示图像和文本之间的关系。 2. 引入选择偏差和扰动偏差来模拟不对齐现象。 3. 通过理论分析推导出MMCL学习到的表征的性质。 4. 使用合成数据和真实数据集进行实验验证。
🖼️ 关键图片


📊 实验亮点
论文通过理论分析和实验验证,揭示了跨模态不对齐对多模态表征学习的影响。在合成数据集上,实验验证了理论分析的正确性。在真实图像-文本数据集上,实验表明,通过考虑不对齐因素,可以提升多模态表征学习的性能。具体提升幅度未知,论文侧重理论分析。
🎯 应用场景
该研究成果可应用于各种多模态表征学习任务,例如图像-文本检索、视觉问答、多模态情感分析等。通过更好地理解和处理跨模态不对齐,可以提升这些任务的性能和鲁棒性。此外,该研究还可以指导多模态数据集的构建和清洗,从而提高数据质量。
📄 摘要(原文)
Multimodal representation learning, exemplified by multimodal contrastive learning (MMCL) using image-text pairs, aims to learn powerful representations by aligning cues across modalities. This approach relies on the core assumption that the exemplar image-text pairs constitute two representations of an identical concept. However, recent research has revealed that real-world datasets often exhibit cross-modal misalignment. There are two distinct viewpoints on how to address this issue: one suggests mitigating the misalignment, and the other leveraging it. We seek here to reconcile these seemingly opposing perspectives, and to provide a practical guide for practitioners. Using latent variable models we thus formalize cross-modal misalignment by introducing two specific mechanisms: Selection bias, where some semantic variables are absent in the text, and perturbation bias, where semantic variables are altered -- both leading to misalignment in data pairs. Our theoretical analysis demonstrates that, under mild assumptions, the representations learned by MMCL capture exactly the information related to the subset of the semantic variables invariant to selection and perturbation biases. This provides a unified perspective for understanding misalignment. Based on this, we further offer actionable insights into how misalignment should inform the design of real-world ML systems. We validate our theoretical findings via extensive empirical studies on both synthetic data and real image-text datasets, shedding light on the nuanced impact of cross-modal misalignment on multimodal representation learning.