Improving Controller Generalization with Dimensionless Markov Decision Processes
作者: Valentin Charvet, Sebastian Stein, Roderick Murray-Smith
分类: cs.LG
发布日期: 2025-04-14
备注: 11 pages, 5 figures
💡 一句话要点
提出基于无量纲MDP的强化学习方法,提升控制器在不同环境下的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 泛化能力 无量纲化 白金汉Π定理 模型预测控制
📋 核心要点
- 强化学习训练的控制器通常过于专门化,当测试环境与训练环境不同时,泛化能力较差。
- 论文提出在无量纲状态-动作空间中训练世界模型和策略,使策略对环境变化具有等变性。
- 在模拟的受控摆和倒立摆系统中,验证了该方法的有效性,提升了策略的泛化能力。
📝 摘要(中文)
本文提出了一种基于模型的强化学习方法,旨在提高控制器在测试环境与训练环境不同时的泛化能力。该方法在无量纲的状态-动作空间中训练世界模型和策略。为此,我们引入了无量纲马尔可夫决策过程($Π$-MDP),它是上下文MDP的扩展,其中状态和动作空间通过白金汉$Π$定理进行无量纲化。该过程使得策略对于底层动力学上下文的变化具有等变性。我们为该方法提供了一个通用框架,并将其应用于使用高斯过程模型的基于模型的策略搜索算法。在模拟的受控摆和倒立摆系统中,我们证明了该方法的适用性,其中在单个环境中训练的策略对于上下文分布的变化具有鲁棒性。
🔬 方法详解
问题定义:强化学习控制器在训练环境和测试环境存在差异时,泛化能力不足。现有方法难以适应环境参数的变化,导致性能下降。例如,在训练时使用特定长度的摆杆,测试时摆杆长度发生变化,控制器可能无法正常工作。
核心思路:利用白金汉$Π$定理进行无量纲化,将状态和动作空间转换为无量纲空间。这样,策略学习不再依赖于具体的物理量纲,而是学习量纲之间的关系。通过在无量纲空间中进行训练,策略能够更好地适应环境参数的变化,从而提高泛化能力。
技术框架:该方法基于模型,整体流程如下:1. 使用白金汉$Π$定理对状态和动作空间进行无量纲化,构建无量纲MDP($Π$-MDP)。2. 在$Π$-MDP中,使用高斯过程模型学习世界模型。3. 使用基于模型的策略搜索算法,在学习到的世界模型中训练策略。4. 将训练好的策略部署到实际环境中。
关键创新:引入了无量纲马尔可夫决策过程($Π$-MDP),将白金汉$Π$定理应用于强化学习,实现了状态和动作空间的无量纲化。与传统的上下文MDP相比,$Π$-MDP更加关注物理量纲之间的关系,从而提高了策略的泛化能力。
关键设计:论文使用高斯过程模型作为世界模型,用于预测无量纲状态的转移概率。策略搜索算法的具体实现未知,但强调了在无量纲空间中进行策略优化。白金汉$Π$定理的应用需要根据具体问题进行分析,确定合适的无量纲变量。
🖼️ 关键图片
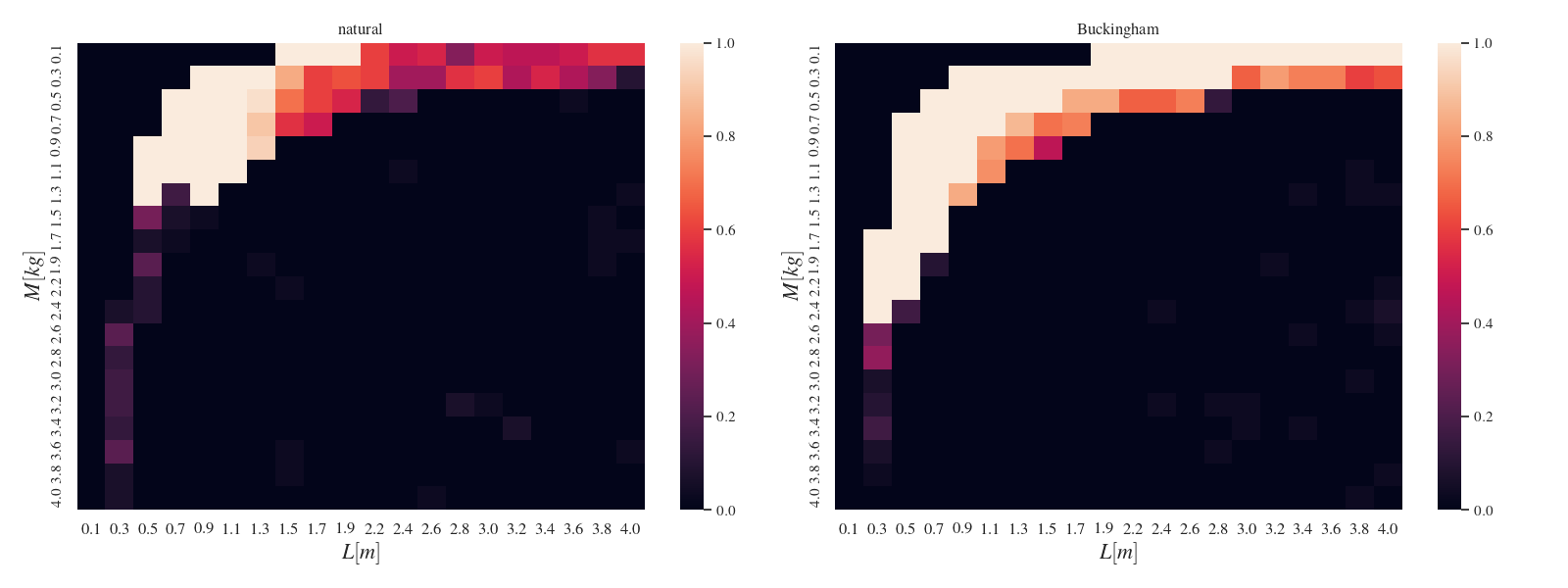

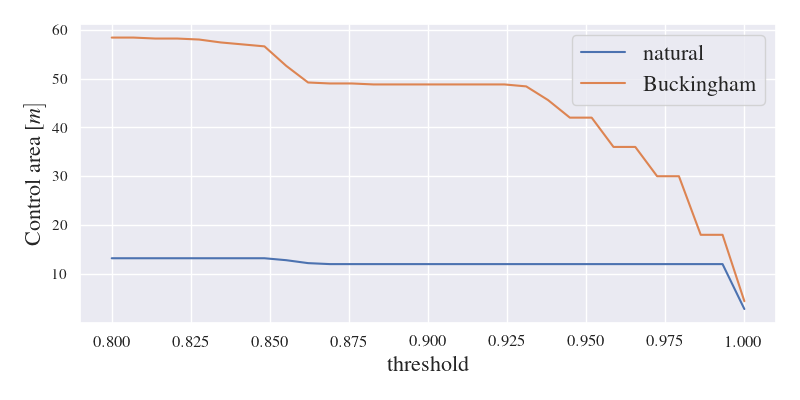
📊 实验亮点
论文在模拟的受控摆和倒立摆系统中验证了该方法的有效性。实验结果表明,使用该方法训练的策略对于环境参数的变化具有很强的鲁棒性。具体性能数据未知,但论文强调了该方法在提高泛化能力方面的优势,尤其是在上下文分布发生变化时。
🎯 应用场景
该研究成果可应用于机器人控制、自动化等领域,尤其适用于需要在不同环境下部署控制器的场景。例如,可以用于训练能够在不同负载下工作的机器人手臂控制器,或者能够在不同风力条件下工作的无人机控制器。通过提高控制器的泛化能力,可以降低部署成本,提高系统的鲁棒性。
📄 摘要(原文)
Controllers trained with Reinforcement Learning tend to be very specialized and thus generalize poorly when their testing environment differs from their training one. We propose a Model-Based approach to increase generalization where both world model and policy are trained in a dimensionless state-action space. To do so, we introduce the Dimensionless Markov Decision Process ($Π$-MDP): an extension of Contextual-MDPs in which state and action spaces are non-dimensionalized with the Buckingham-$Π$ theorem. This procedure induces policies that are equivariant with respect to changes in the context of the underlying dynamics. We provide a generic framework for this approach and apply it to a model-based policy search algorithm using Gaussian Process models. We demonstrate the applicability of our method on simulated actuated pendulum and cartpole systems, where policies trained on a single environment are robust to shifts in the distribution of the context.