KeepKV: Achieving Periodic Lossless KV Cache Compression for Efficient LLM Inference
作者: Yuxuan Tian, Zihan Wang, Yebo Peng, Aomufei Yuan, Zhiming Wang, Bairen Yi, Xin Liu, Yong Cui, Tong Yang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-14 (更新: 2025-11-27)
备注: 14 pages, 20 figures
💡 一句话要点
KeepKV:实现LLM高效推理的周期性无损KV缓存压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 大型语言模型 LLM推理 无损压缩 注意力机制 模型优化 内存优化
📋 核心要点
- 现有KV缓存压缩方法,如选择性删除或合并策略,存在信息丢失或注意力分布不一致的问题,影响LLM生成质量。
- KeepKV通过引入选举票机制和零推理扰动合并方法,自适应调整注意力分数并补偿注意力损失,实现无损压缩。
- 实验表明,KeepKV在大幅降低内存占用的同时,显著提升了LLM推理吞吐量,并保持了较高的生成质量。
📝 摘要(中文)
大型语言模型(LLM)推理效率受日益增长的键值(KV)缓存限制,KV缓存压缩成为关键研究方向。传统方法选择性地删除不重要的KV缓存条目,导致信息丢失和幻觉。最近,基于合并的策略通过合并将被丢弃的KV对来保留更多信息;然而,这些方法不可避免地引入了合并前后注意力分布的不一致性,导致生成质量下降。为了克服这一挑战,我们提出了KeepKV,一种新颖的自适应KV缓存合并方法,旨在在严格的内存约束下保持性能,实现单步无损压缩,并为多步压缩提供误差界限。KeepKV引入了选举票机制,记录合并历史并自适应地调整注意力分数。此外,它还利用了一种新颖的零推理扰动合并方法,补偿由缓存合并导致的注意力损失。在各种基准和LLM架构上的大量实验表明,KeepKV在显著降低内存使用量的同时,成功地保留了必要的上下文信息,实现了超过2倍的推理吞吐量提升,即使在只有10% KV缓存预算的情况下也能保持卓越的生成质量。
🔬 方法详解
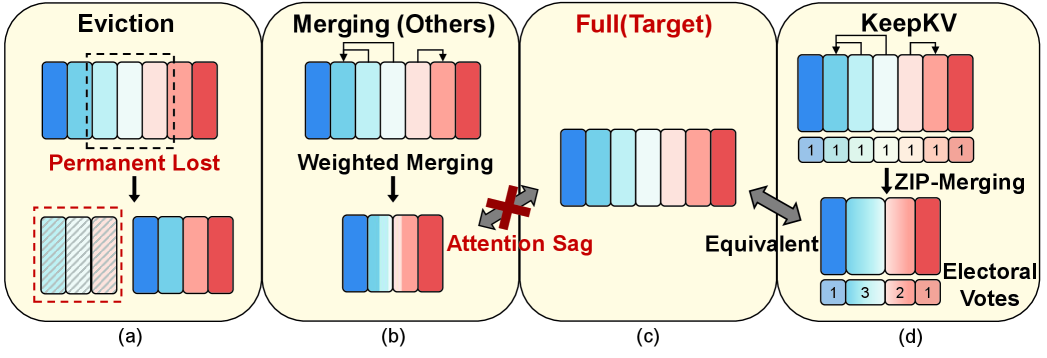
问题定义:论文旨在解决大型语言模型(LLM)推理过程中,KV缓存占用内存过大导致推理效率降低的问题。现有方法,如KV缓存选择性删除或合并,要么丢失信息,要么引入注意力分布不一致,从而影响生成质量。
核心思路:KeepKV的核心思路是在压缩KV缓存的同时,尽可能保留原始信息,并保证合并前后注意力分布的一致性。通过引入选举票机制记录合并历史,并自适应调整注意力分数,从而减少信息损失。同时,采用零推理扰动合并方法,补偿合并导致的注意力损失。
技术框架:KeepKV主要包含两个核心模块:选举票机制和零推理扰动合并。选举票机制记录KV对的合并历史,用于后续注意力分数的调整。零推理扰动合并则通过补偿注意力损失,保证合并前后注意力分布的相似性。整体流程为:首先利用选举票机制选择待合并的KV对,然后进行合并,最后利用零推理扰动合并补偿注意力损失。
关键创新:KeepKV的关键创新在于其无损压缩的特性。与传统方法不同,KeepKV旨在保留所有信息,并通过自适应调整注意力分数和补偿注意力损失,保证生成质量。选举票机制和零推理扰动合并是实现这一目标的关键技术。
关键设计:选举票机制的设计需要考虑如何有效地记录合并历史,并将其用于注意力分数的调整。零推理扰动合并需要设计合适的补偿策略,以最小化合并导致的注意力损失。具体的参数设置和损失函数需要根据不同的LLM架构和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
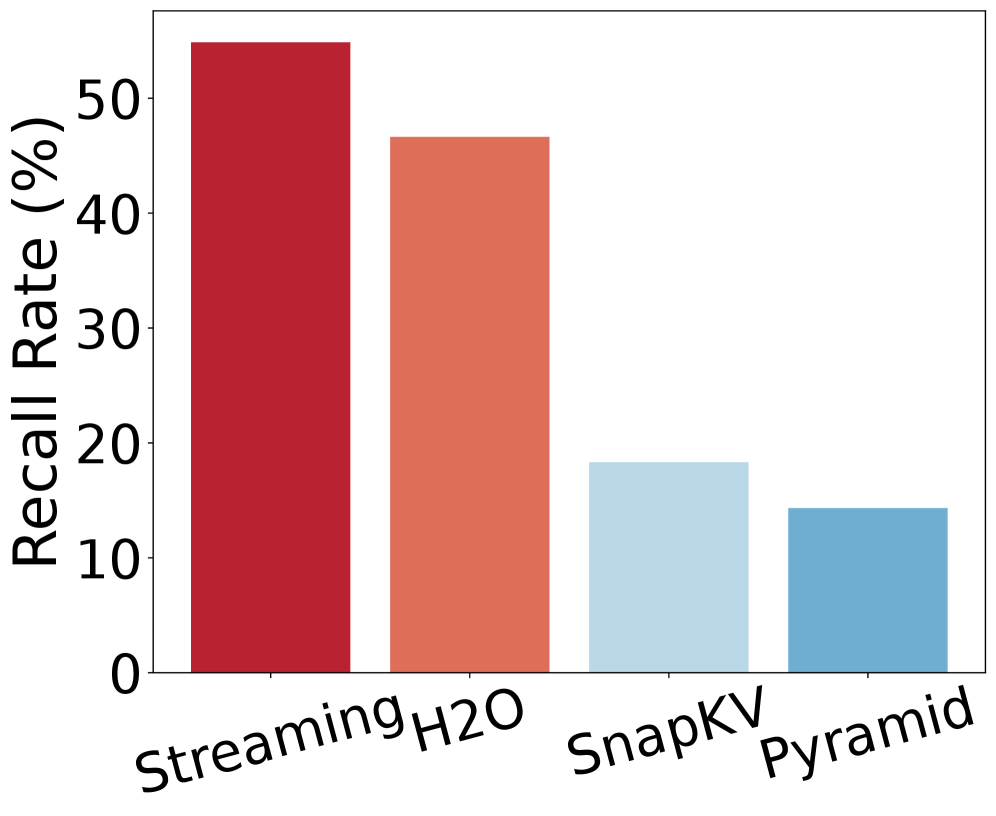
实验结果表明,KeepKV在各种基准测试和LLM架构上都表现出色。在内存占用仅为10%的情况下,KeepKV能够实现超过2倍的推理吞吐量提升,并保持与原始模型相当的生成质量。与现有KV缓存压缩方法相比,KeepKV在性能和生成质量方面都具有显著优势。
🎯 应用场景
KeepKV可应用于各种需要高效LLM推理的场景,例如移动设备上的本地LLM部署、资源受限的边缘计算环境以及大规模LLM服务。通过降低内存占用和提高推理吞吐量,KeepKV能够显著降低LLM部署和运行的成本,并促进LLM在更广泛的应用场景中的普及。
📄 摘要(原文)
Efficient inference of large language models (LLMs) is hindered by an ever-growing key-value (KV) cache, making KV cache compression a critical research direction. Traditional methods selectively evict less important KV cache entries, which leads to information loss and hallucinations. Recently, merging-based strategies have been explored to retain more information by merging KV pairs that would be discarded; however, these existing approaches inevitably introduce inconsistencies in attention distributions before and after merging, causing degraded generation quality. To overcome this challenge, we propose KeepKV, a novel adaptive KV cache merging method designed to preserve performance under strict memory constraints, achieving single-step lossless compression and providing error bounds for multi-step compression. KeepKV introduces the Electoral Votes mechanism that records merging history and adaptively adjusts attention scores. Moreover, it further leverages a novel Zero Inference-Perturbation Merging method, compensating for attention loss resulting from cache merging. Extensive experiments on various benchmarks and LLM architectures demonstrate that KeepKV substantially reduces memory usage while successfully retaining essential context information, achieving over 2x inference throughput improvement and maintaining superior generation quality even with only 10% KV cache budgets.