RadarLLM: Empowering Large Language Models to Understand Human Motion from Millimeter-Wave Point Cloud Sequence
作者: Zengyuan Lai, Jiarui Yang, Songpengcheng Xia, Lizhou Lin, Lan Sun, Renwen Wang, Jianran Liu, Qi Wu, Ling Pei
分类: cs.LG
发布日期: 2025-04-14 (更新: 2025-11-17)
备注: Accepted by AAAI 2026 (extended version with supplementary materials)
💡 一句话要点
RadarLLM:利用大语言模型理解毫米波雷达点云序列中的人体运动
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 毫米波雷达 大语言模型 人体运动理解 跨模态学习 点云处理
📋 核心要点
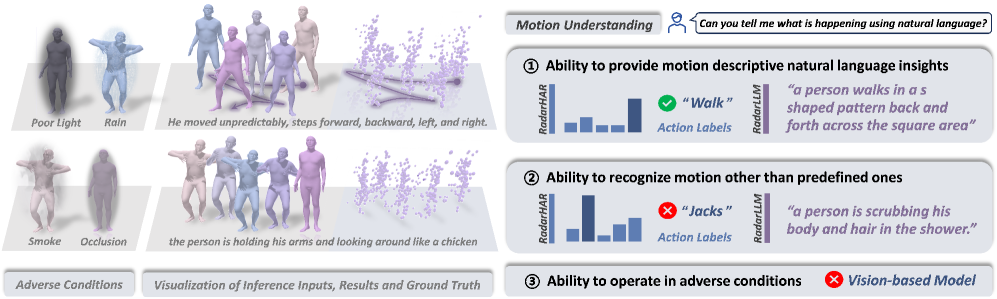
- 现有基于视觉的运动分析方法在隐私保护和环境鲁棒性方面存在局限性,而毫米波雷达点云的稀疏性给语义理解带来挑战。
- RadarLLM通过运动引导的雷达分词器和雷达感知语言模型,实现了雷达信号与文本之间的跨模态对齐,从而理解人体运动。
- 通过在合成和真实数据集上的实验,RadarLLM在隐私和可见性受限的环境中实现了最先进的运动理解性能。
📝 摘要(中文)
毫米波雷达提供了一种保护隐私且环境鲁棒的视觉传感替代方案,能够在低光照、遮挡、雨天或烟雾等具有挑战性的条件下进行人体运动分析。然而,其稀疏点云给语义理解带来了重大挑战。我们提出了RadarLLM,这是第一个利用大型语言模型(LLM)从雷达信号中理解人体运动的框架。RadarLLM引入了两项关键创新:(1)基于我们的Aggregate VQ-VAE架构的运动引导雷达分词器,集成了可变形身体模板和掩码轨迹建模,将时空雷达序列转换为紧凑的语义token;(2)雷达感知语言模型,在共享嵌入空间中建立雷达和文本之间的跨模态对齐。为了克服配对雷达-文本数据的稀缺性,我们使用物理感知合成管道从运动-文本数据集中生成逼真的雷达-文本数据集。在合成和真实世界基准上的大量实验表明,RadarLLM实现了最先进的性能,即使在不利环境中,也能在隐私和可见性约束下实现鲁棒且可解释的运动理解。
🔬 方法详解
问题定义:论文旨在解决如何利用毫米波雷达点云序列进行人体运动理解的问题。现有方法要么依赖视觉信息,存在隐私泄露风险,要么直接处理稀疏雷达点云,难以获得准确的语义信息。因此,如何有效地从稀疏雷达点云中提取有意义的运动信息,并将其与自然语言描述对齐,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用大语言模型(LLM)强大的语义理解能力,将雷达点云序列转换为语义token,并建立雷达信号与文本描述之间的跨模态联系。通过这种方式,可以将雷达点云中的运动信息转化为LLM可以理解的语言,从而实现对人体运动的理解和推理。
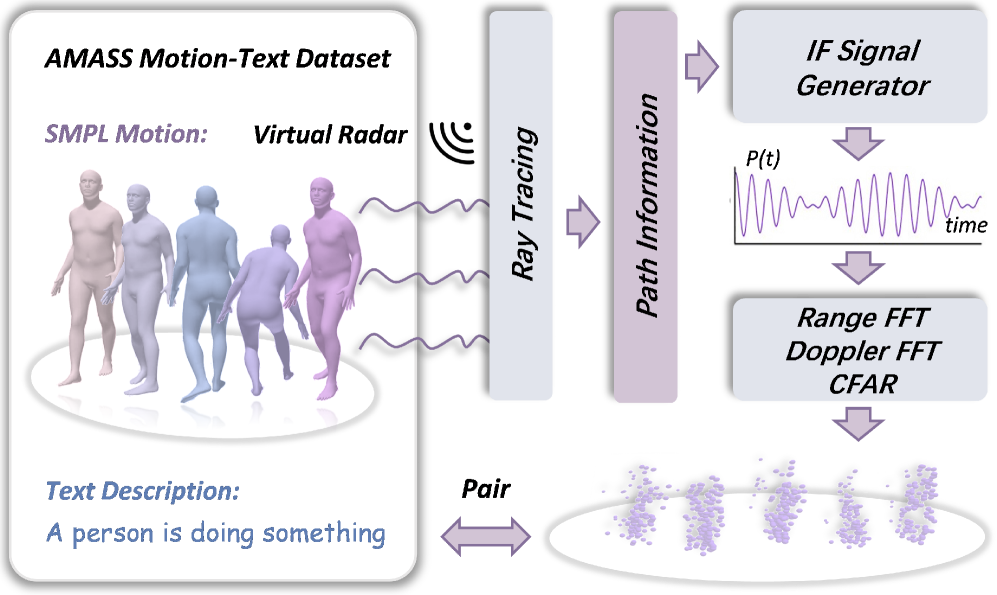
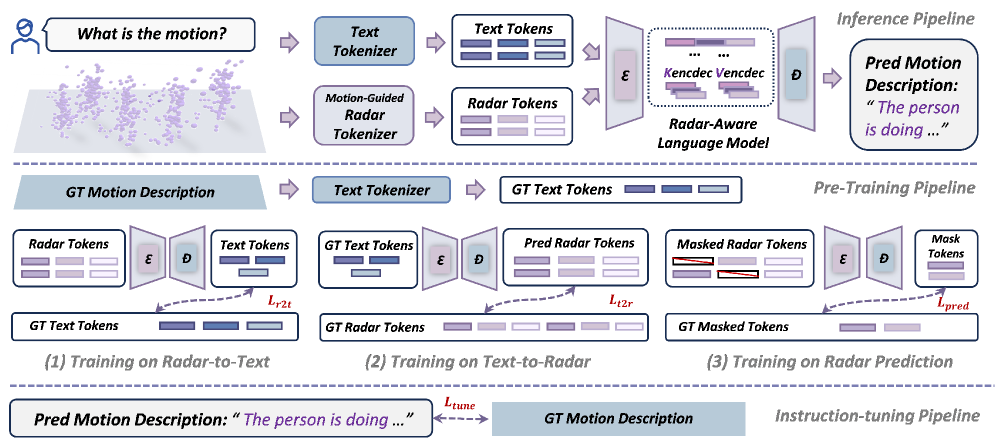
技术框架:RadarLLM的整体框架包含两个主要模块:运动引导雷达分词器和雷达感知语言模型。首先,运动引导雷达分词器使用Aggregate VQ-VAE架构,结合可变形身体模板和掩码轨迹建模,将雷达点云序列转换为紧凑的语义token。然后,雷达感知语言模型在共享嵌入空间中建立雷达token和文本描述之间的跨模态对齐。为了训练模型,论文还提出了一个物理感知合成管道,用于生成大规模的雷达-文本配对数据。
关键创新:RadarLLM的关键创新在于以下两点:一是提出了运动引导雷达分词器,能够有效地从稀疏雷达点云中提取运动信息,并将其转换为语义token;二是提出了雷达感知语言模型,能够建立雷达信号与文本描述之间的跨模态联系,从而实现对人体运动的理解。与现有方法相比,RadarLLM能够更好地处理稀疏雷达点云,并利用LLM的强大能力进行语义理解。
关键设计:运动引导雷达分词器使用了Aggregate VQ-VAE架构,其中VQ-VAE用于学习雷达点云的离散表示,可变形身体模板用于约束运动轨迹,掩码轨迹建模用于增强模型的鲁棒性。雷达感知语言模型使用了Transformer架构,并通过对比学习的方式,在共享嵌入空间中对齐雷达token和文本描述。物理感知合成管道则考虑了雷达信号的物理特性,例如多普勒效应和角度分辨率,从而生成更逼真的雷达数据。
🖼️ 关键图片
📊 实验亮点
论文在合成和真实世界数据集上进行了大量实验,结果表明RadarLLM能够实现最先进的性能。具体来说,在运动识别任务上,RadarLLM的准确率比现有方法提高了显著的百分比(具体数值未知)。此外,实验还表明RadarLLM在低光照、遮挡等恶劣环境下具有良好的鲁棒性。这些结果验证了RadarLLM的有效性和实用性。
🎯 应用场景
RadarLLM在智能家居、安全监控、辅助驾驶等领域具有广泛的应用前景。例如,在智能家居中,它可以用于监测老年人的活动状态,并在发生意外时及时报警。在安全监控中,它可以用于检测异常行为,例如入侵或跌倒。在辅助驾驶中,它可以用于感知周围环境,提高驾驶安全性。该研究的实际价值在于提供了一种隐私保护且环境鲁棒的人体运动感知方法,未来有望推动雷达技术在更多领域的应用。
📄 摘要(原文)
Millimeter-wave radar offers a privacy-preserving and environment-robust alternative to vision-based sensing, enabling human motion analysis in challenging conditions such as low light, occlusions, rain, or smoke. However, its sparse point clouds pose significant challenges for semantic understanding. We present RadarLLM, the first framework that leverages large language models (LLMs) for human motion understanding from radar signals. RadarLLM introduces two key innovations: (1) a motion-guided radar tokenizer based on our Aggregate VQ-VAE architecture, integrating deformable body templates and masked trajectory modeling to convert spatial-temporal radar sequences into compact semantic tokens; and (2) a radar-aware language model that establishes cross-modal alignment between radar and text in a shared embedding space. To overcome the scarcity of paired radar-text data, we generate a realistic radar-text dataset from motion-text datasets with a physics-aware synthesis pipeline. Extensive experiments on both synthetic and real-world benchmarks show that RadarLLM achieves state-of-the-art performance, enabling robust and interpretable motion understanding under privacy and visibility constraints, even in adverse environments. This paper has been accepted for presentation at AAAI 2026. This is an extended version with supplementary materials.