Federated Learning with Layer Skipping: Efficient Training of Large Language Models for Healthcare NLP
作者: Lihong Zhang, Yue Li
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-04-13
💡 一句话要点
提出层跳跃联邦学习,高效训练医疗NLP大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 医疗NLP 层跳跃 隐私保护
📋 核心要点
- 现有联邦学习训练大型语言模型时,面临通信开销大和数据异构性的挑战。
- 提出层跳跃联邦学习,仅微调预训练LLM的部分层,显著降低通信成本。
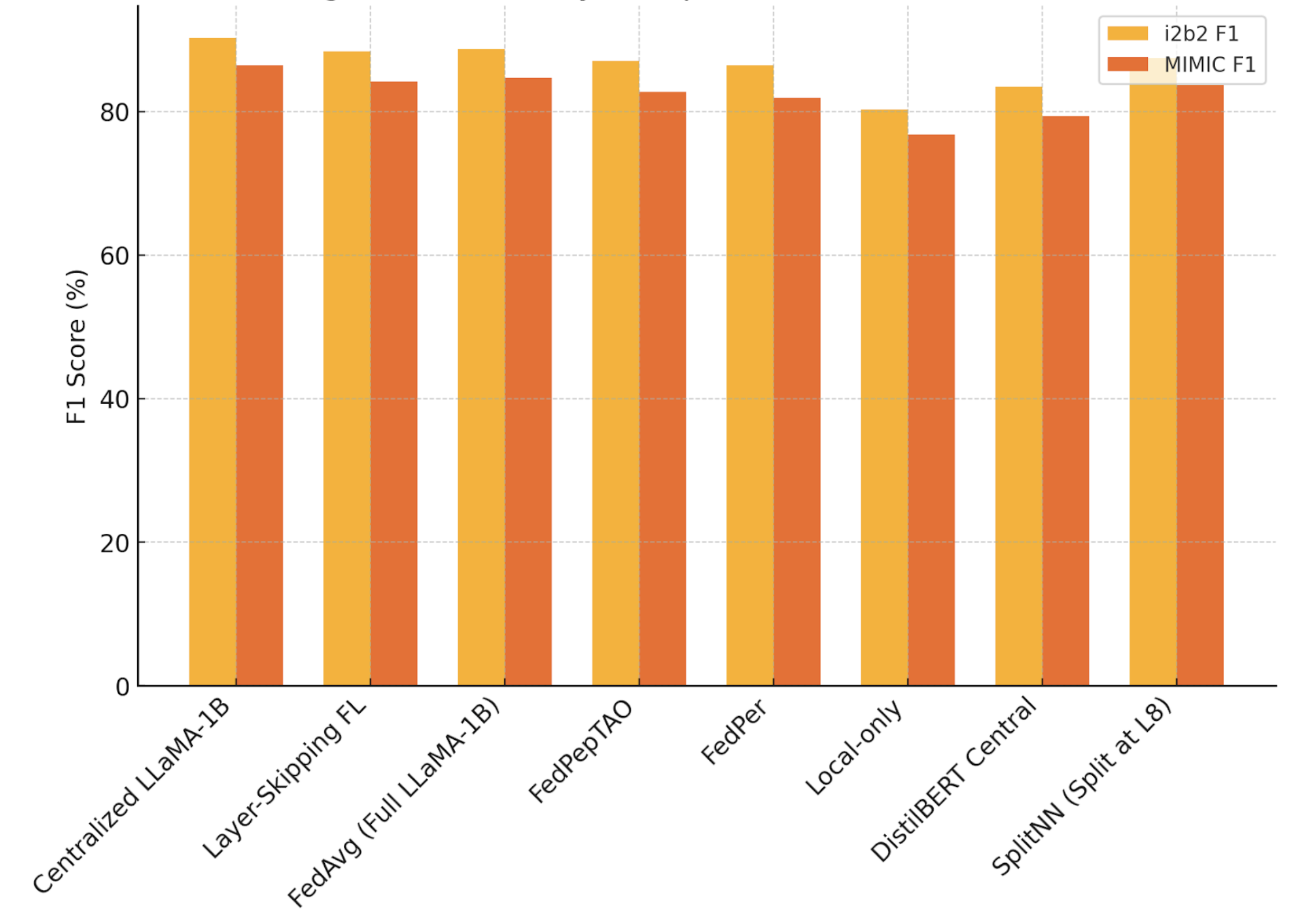
- 实验表明,该方法在临床任务上优于基线,且对非独立同分布数据和差分隐私具有鲁棒性。
📝 摘要(中文)
联邦学习(FL)允许跨组织协作训练模型,无需共享原始数据,解决了医疗自然语言处理(NLP)中关键的隐私问题。然而,在联邦环境中训练大型语言模型(LLM)面临着通信开销和数据异构等重大挑战。我们提出了层跳跃联邦学习,其中预训练LLM的仅选择的层在客户端之间进行微调,而其他层保持冻结。应用于LLaMA 3.2-1B,我们的方法将通信成本降低了约70%,同时保持了与集中式训练相差2%以内的性能。我们使用i2b2和MIMIC-III数据集在临床NER和分类任务上评估了我们的方法。我们的实验表明,层跳跃联邦学习优于有竞争力的基线,有效地处理了非独立同分布(non-IID)临床数据分布,并且在与差分隐私结合使用时表现出鲁棒性。这种方法代表了医疗NLP中保护隐私的协作学习的实用解决方案。
🔬 方法详解
问题定义:论文旨在解决在医疗NLP领域,使用联邦学习训练大型语言模型时面临的通信开销过大和数据异构性问题。传统的联邦学习方法需要传输整个模型的更新,这对于参数量巨大的LLM来说,通信成本非常高昂。此外,医疗数据通常具有非独立同分布的特性,这会进一步影响联邦学习的性能。
核心思路:论文的核心思路是只对LLM的部分层进行微调,而冻结其他层。通过选择性地更新模型参数,可以显著减少通信量,从而降低通信开销。同时,该方法可以更好地适应不同客户端的数据分布,提高模型的泛化能力。
技术框架:整体框架基于标准的联邦学习流程,包括服务器和多个客户端。每个客户端拥有本地的医疗数据,并使用这些数据对LLM的部分层进行微调。服务器负责收集客户端的更新,并进行聚合,然后将更新后的模型参数发送回客户端。关键在于客户端只上传和下载选定层的参数,而不是整个模型。
关键创新:最重要的创新点在于提出了“层跳跃”的概念,即选择性地更新LLM的某些层,而冻结其他层。这种方法与传统的联邦学习方法不同,后者通常需要更新整个模型。层跳跃联邦学习可以显著减少通信量,提高训练效率,同时保持模型的性能。
关键设计:论文使用了LLaMA 3.2-1B作为基础模型,并选择了一部分层进行微调。具体的层选择策略未知,但可能是基于对模型各层重要性的分析。损失函数使用了标准的交叉熵损失函数,优化器使用了AdamW。差分隐私通过在上传的梯度中添加噪声来实现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,层跳跃联邦学习在通信成本降低约70%的情况下,性能仅比集中式训练下降2%以内。在i2b2和MIMIC-III数据集上的临床NER和分类任务中,该方法优于其他联邦学习基线。此外,该方法在处理非独立同分布数据和结合差分隐私时表现出良好的鲁棒性。
🎯 应用场景
该研究成果可应用于医疗领域的各种NLP任务,例如命名实体识别、文本分类、关系抽取等。通过联邦学习,不同的医疗机构可以在保护患者隐私的前提下,协作训练高性能的LLM,从而提高医疗服务的质量和效率。该方法还可以推广到其他数据敏感的领域,例如金融、法律等。
📄 摘要(原文)
Federated learning (FL) enables collaborative model training across organizations without sharing raw data, addressing crucial privacy concerns in healthcare natural language processing (NLP). However, training large language models (LLMs) in federated settings faces significant challenges, including communication overhead and data heterogeneity. We propose Layer-Skipping Federated Learning, where only selected layers of a pre-trained LLM are fine-tuned across clients while others remain frozen. Applied to LLaMA 3.2-1B, our approach reduces communication costs by approximately 70% while maintaining performance within 2% of centralized training. We evaluate our method on clinical NER and classification tasks using i2b2 and MIMIC-III datasets. Our experiments demonstrate that Layer-Skipping FL outperforms competitive baselines, handles non-IID clinical data distributions effectively, and shows robustness when combined with differential privacy. This approach represents a practical solution for privacy-preserving collaborative learning in healthcare NLP.