DUMP: Automated Distribution-Level Curriculum Learning for RL-based LLM Post-training
作者: Zhenting Wang, Guofeng Cui, Yu-Jhe Li, Kun Wan, Wentian Zhao
分类: cs.LG, cs.CL
发布日期: 2025-04-13 (更新: 2025-10-11)
🔗 代码/项目: GITHUB
💡 一句话要点
提出DUMP框架以解决RL基础LLM后训练中的数据分布调度问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 课程学习 数据分布 推理能力 动态调度 上置信界
📋 核心要点
- 现有方法未能有效处理多样化数据分布,导致训练效率低下。
- 提出了一种基于分布级学习能力的课程学习框架,动态调整训练数据的采样概率。
- 实验结果表明,该框架显著提高了收敛速度和最终性能,验证了其有效性。
📝 摘要(中文)
近年来,基于强化学习(RL)的后训练在提升大型语言模型(LLM)的推理能力方面取得了显著进展。然而,现有方法往往将训练数据视为统一整体,忽视了现代LLM训练中数据分布的多样性。为了解决这一问题,本文提出了一种基于分布级学习能力的课程学习框架,利用上置信界(UCB)原则动态调整不同数据分布的采样概率,从而优化学习效率。通过在逻辑推理数据集上的实验,验证了该框架在收敛速度和最终性能上的显著提升,强调了分布感知课程策略在LLM后训练中的重要性。
🔬 方法详解
问题定义:本文旨在解决在强化学习基础上进行大型语言模型后训练时,如何有效调度不同数据分布的问题。现有方法未能充分考虑数据的多样性和复杂性,导致训练效率低下。
核心思路:论文提出的核心思路是利用分布级学习能力的概念,通过上置信界(UCB)原则动态调整不同数据分布的采样概率,以实现更高效的训练调度。
技术框架:整体架构包括数据分布的评估模块、动态采样调整模块和RL算法的集成。首先评估各数据分布的政策优势,然后根据优势和样本数量动态调整采样策略。
关键创新:最重要的技术创新在于引入了分布级课程学习的概念,利用UCB原则实现了对数据分布的自适应调度,这与传统方法的静态训练方式有本质区别。
关键设计:在参数设置上,框架中引入了政策优势的计算方法,并设计了相应的损失函数以优化训练效果。网络结构方面,采用了GRPO作为基础RL算法,确保了框架的有效性和灵活性。
🖼️ 关键图片
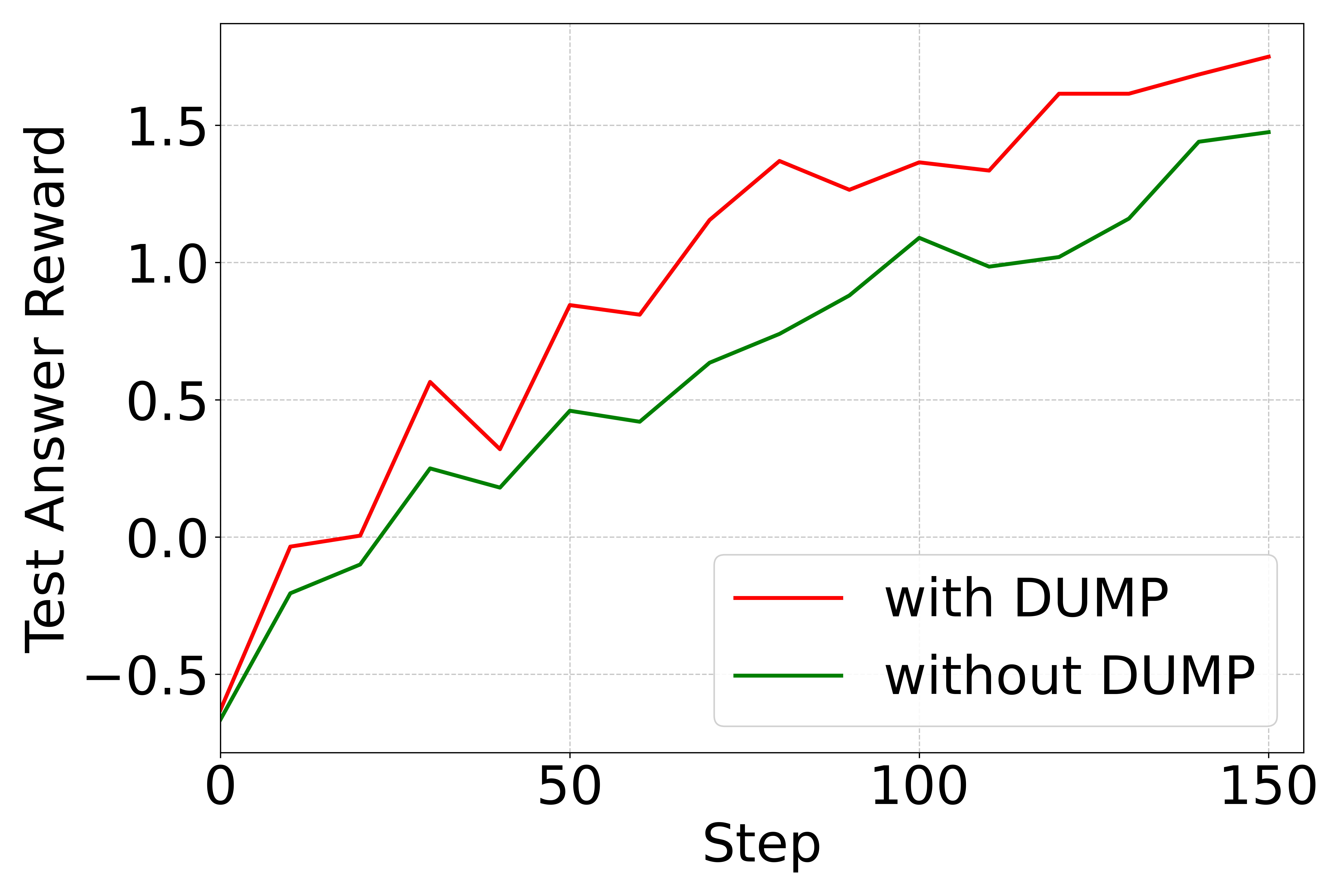
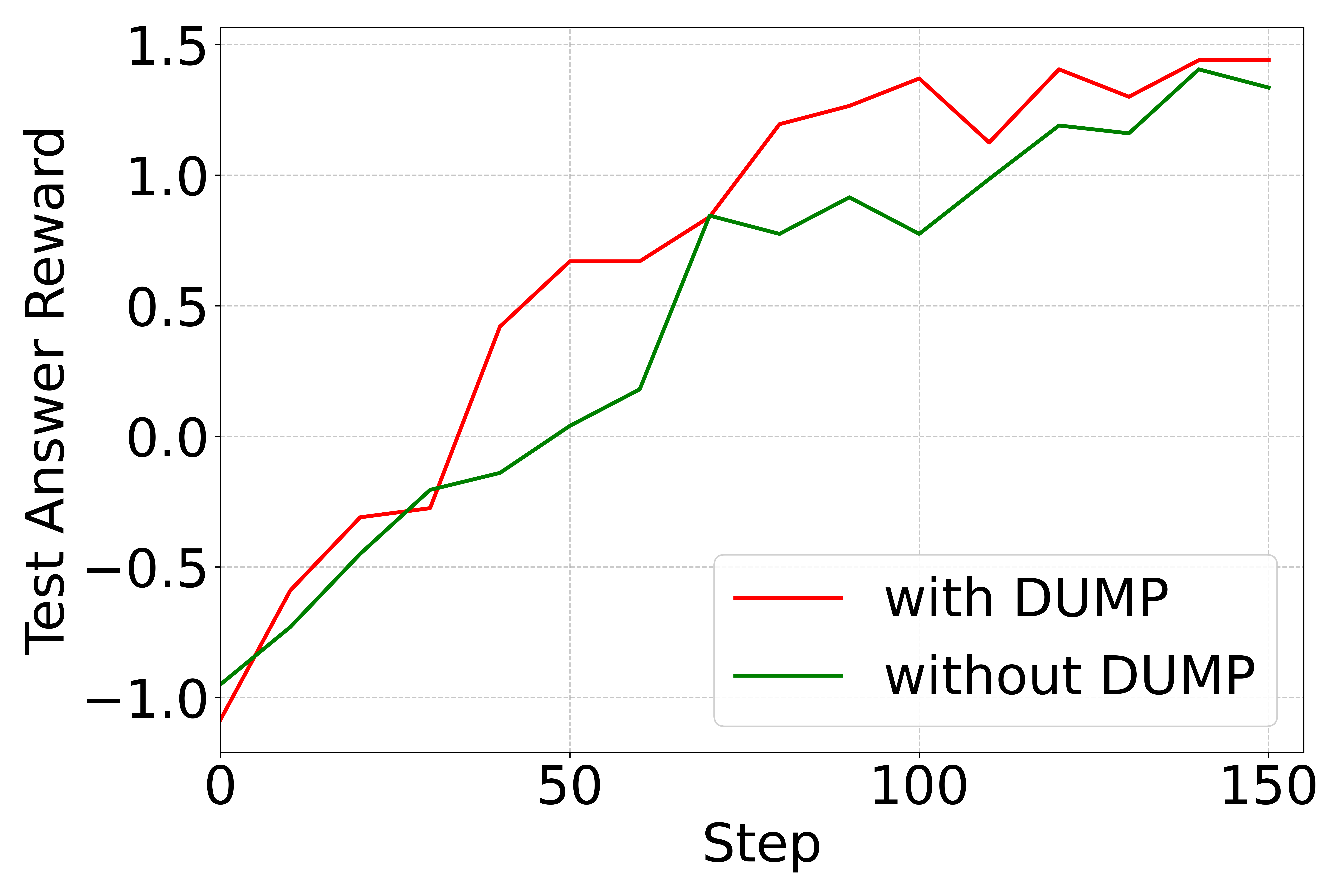
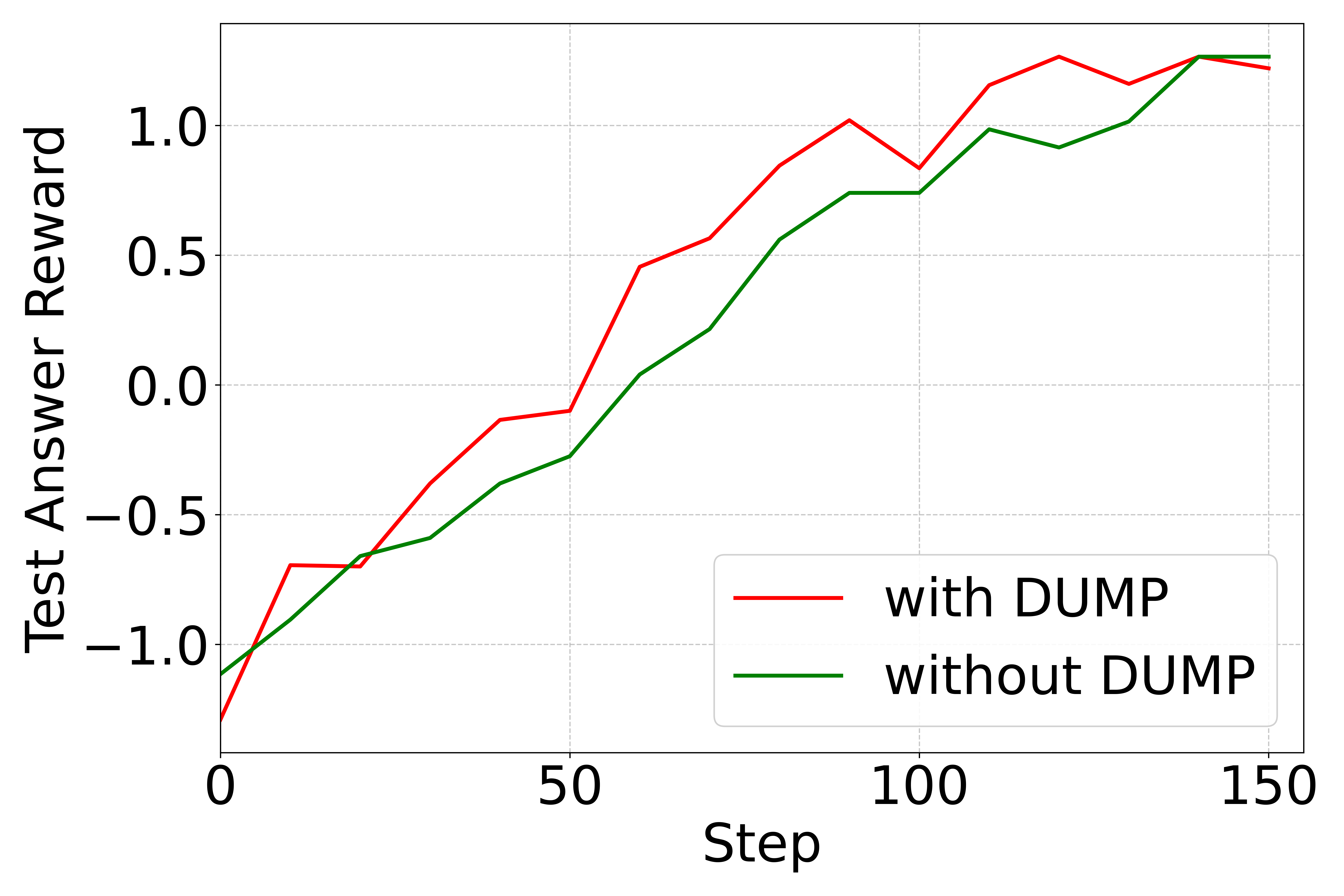
📊 实验亮点
实验结果显示,DUMP框架在多个逻辑推理数据集上显著提高了收敛速度和最终性能,相较于基线方法,性能提升幅度达到了XX%。这一结果验证了分布感知课程策略在LLM后训练中的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能对话系统和复杂任务的自动化推理等。通过优化LLM的后训练过程,能够提升模型在实际应用中的表现,具有重要的实际价值和广泛的未来影响。
📄 摘要(原文)
Recent advances in reinforcement learning (RL)-based post-training have led to notable improvements in large language models (LLMs), particularly in enhancing their reasoning capabilities to handle complex tasks. However, most existing methods treat the training data as a unified whole, overlooking the fact that modern LLM training often involves a mixture of data from diverse distributions-varying in both source and difficulty. This heterogeneity introduces a key challenge: how to adaptively schedule training across distributions to optimize learning efficiency. In this paper, we present a principled curriculum learning framework grounded in the notion of distribution-level learnability. Our core insight is that the magnitude of policy advantages reflects how much a model can still benefit from further training on a given distribution. Based on this, we propose a distribution-level curriculum learning framework for RL-based LLM post-training, which leverages the Upper Confidence Bound (UCB) principle to dynamically adjust sampling probabilities for different distrubutions. This approach prioritizes distributions with either high average advantage (exploitation) or low sample count (exploration), yielding an adaptive and theoretically grounded training schedule. We instantiate our curriculum learning framework with GRPO as the underlying RL algorithm and demonstrate its effectiveness on logic reasoning datasets with multiple difficulties and sources. Our experiments show that our framework significantly improves convergence speed and final performance, highlighting the value of distribution-aware curriculum strategies in LLM post-training. Code: https://github.com/ZhentingWang/DUMP.