Can LLMs Revolutionize the Design of Explainable and Efficient TinyML Models?
作者: Christophe El Zeinaty, Wassim Hamidouche, Glenn Herrou, Daniel Menard, Merouane Debbah
分类: cs.LG, cs.AI
发布日期: 2025-04-13
💡 一句话要点
利用LLM驱动的神经架构搜索设计高效可解释的TinyML模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: TinyML 神经架构搜索 大型语言模型 知识蒸馏 Pareto优化 嵌入式设备 模型压缩
📋 核心要点
- 现有TinyML模型在精度、效率和可解释性之间难以取得平衡,尤其是在资源受限的嵌入式设备上。
- 利用LLM进行神经架构搜索,结合Pareto优化和知识蒸馏,在精度、计算成本和内存占用间寻找最优解。
- 实验表明,提出的模型在CIFAR-100数据集上超越了现有SOTA模型,同时满足TinyML平台的资源约束。
📝 摘要(中文)
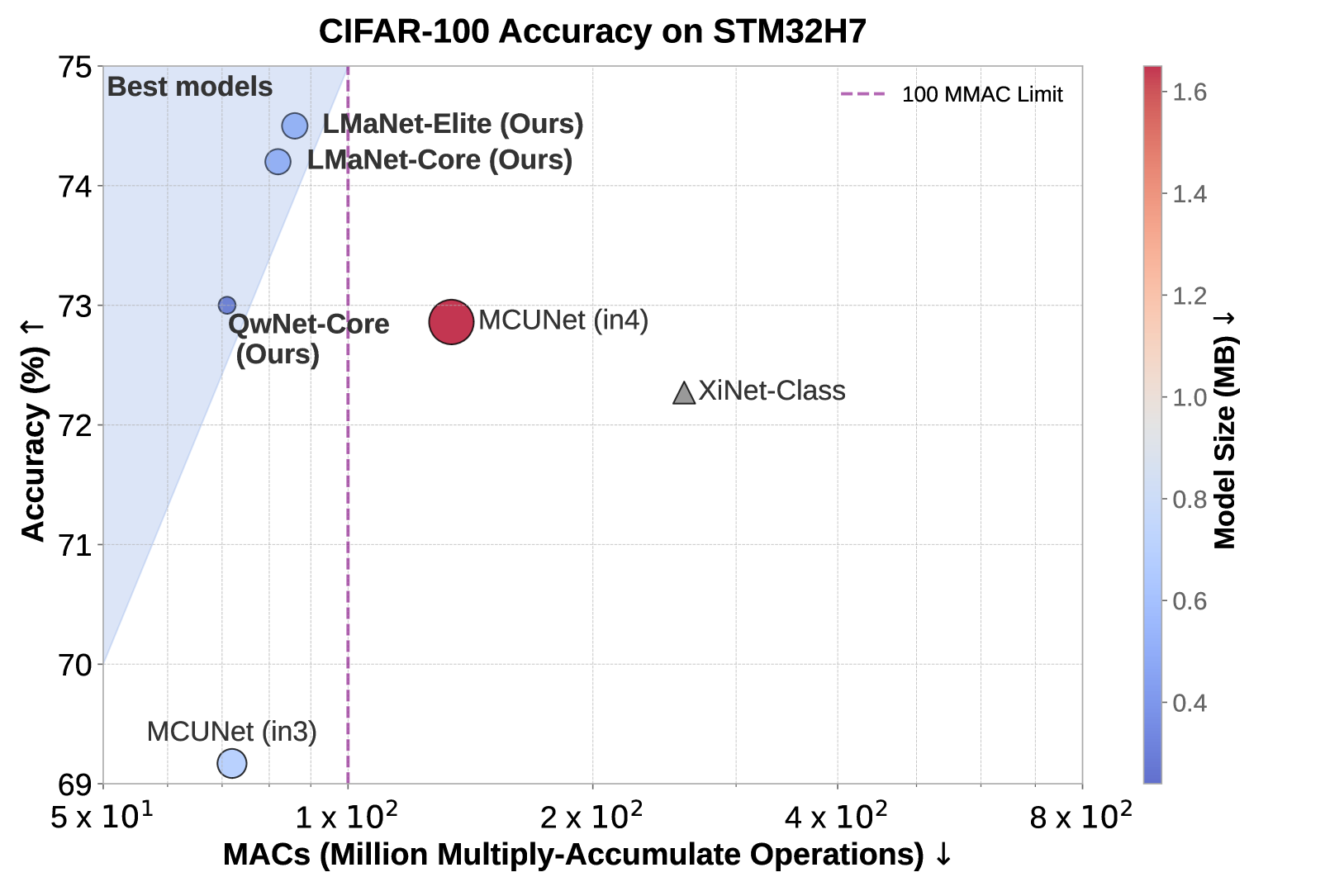
本文提出了一种新颖的框架,用于设计专为TinyML平台量身定制的高效神经网络架构。该方法利用大型语言模型(LLM)进行神经架构搜索(NAS),采用基于视觉Transformer(ViT)的知识蒸馏(KD)策略,并集成了一个可解释性模块,从而在准确性、计算效率和内存使用之间实现了最佳平衡。LLM引导的搜索探索了一个分层搜索空间,通过基于准确性、乘法累加运算(MACs)和内存指标的Pareto优化来改进候选架构。使用预训练的ViT-B/16模型,通过基于logits的KD进一步微调性能最佳的架构,从而在不增加模型大小的情况下增强泛化能力。在CIFAR-100数据集上评估并在STM32H7微控制器(MCU)上部署后,三个提出的模型LMaNet-Elite、LMaNet-Core和QwNet-Core分别实现了74.50%、74.20%和73.00%的准确率。这三个模型都超过了当前最先进的模型,如MCUNet-in3/in4(69.62%/72.86%)和XiNet(72.27%),同时保持了低于1亿MACs的低计算成本,并符合严格的320KB静态随机存取存储器(SRAM)约束。这些结果证明了所提出的TinyML平台框架的效率和性能,突出了结合LLM驱动的搜索、Pareto优化、KD和可解释性来开发准确、高效和可解释模型的潜力。这种方法为NAS开辟了新的可能性,能够设计特别适合TinyML的高效架构。
🔬 方法详解
问题定义:本文旨在解决TinyML模型设计中准确率、计算效率和内存占用之间的矛盾。现有方法通常难以在资源受限的嵌入式设备上实现高性能,并且缺乏可解释性,限制了其在实际应用中的部署。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大搜索能力,在预定义的搜索空间内寻找最优的神经网络架构。通过结合Pareto优化,在多个目标(准确率、MACs、内存占用)之间进行权衡,并使用知识蒸馏进一步提升模型性能。
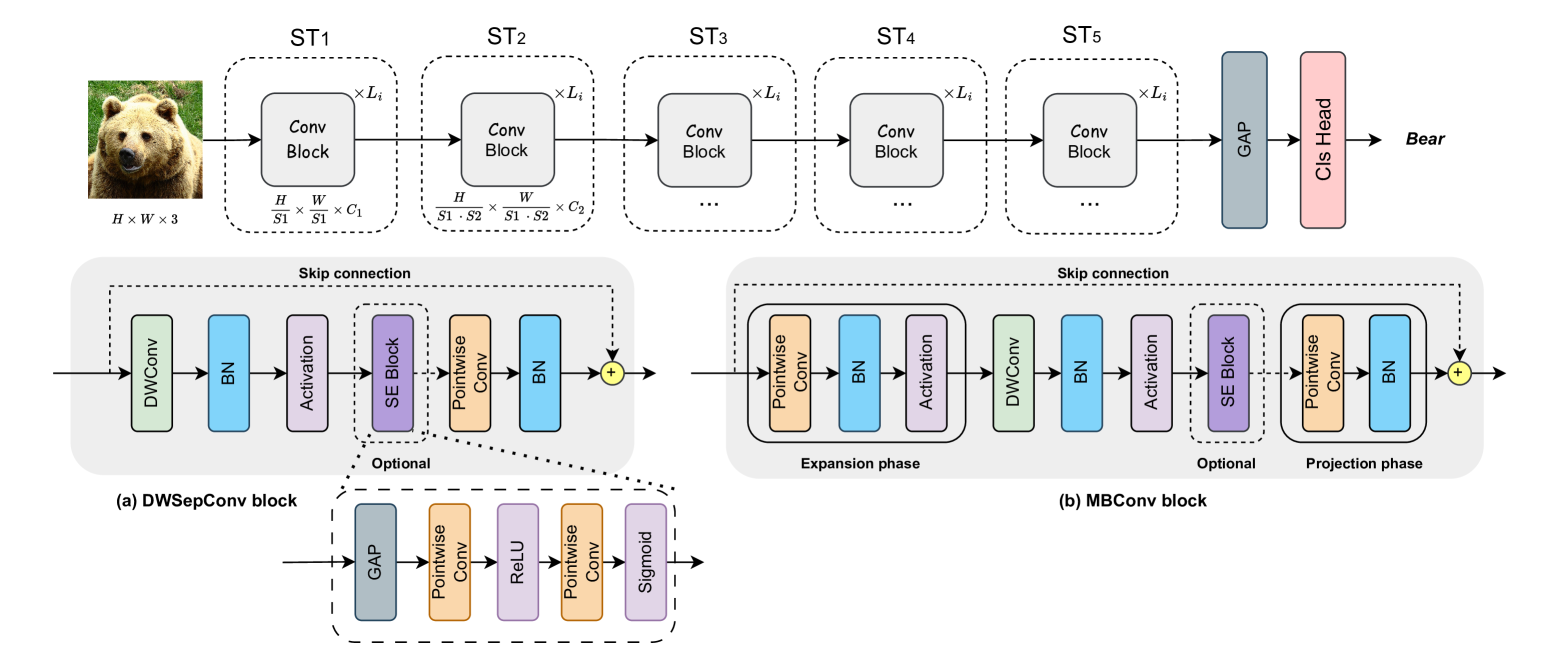
技术框架:该框架包含三个主要模块:1) LLM驱动的神经架构搜索:使用LLM探索分层搜索空间,生成候选架构。2) Pareto优化:基于准确率、MACs和内存指标,对候选架构进行评估和筛选,选择Pareto最优解。3) 知识蒸馏:使用预训练的ViT-B/16模型作为教师模型,通过logits-based KD微调学生模型,提升泛化能力。
关键创新:最重要的技术创新点在于将LLM引入神经架构搜索,利用LLM的语义理解和生成能力,更有效地探索搜索空间。与传统的NAS方法相比,LLM能够更好地理解架构设计的约束和目标,从而生成更符合TinyML平台需求的模型。
关键设计:关键设计包括:1) 分层搜索空间的设计,允许LLM逐步细化架构。2) Pareto优化中各个目标的权重设置,需要根据具体应用场景进行调整。3) 知识蒸馏中温度参数的选择,影响蒸馏效果。4) 网络结构中使用了深度可分离卷积等高效算子,降低计算复杂度。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的LMaNet-Elite、LMaNet-Core和QwNet-Core模型在CIFAR-100数据集上分别取得了74.50%、74.20%和73.00%的准确率,超越了当前SOTA模型MCUNet-in3/in4(69.62%/72.86%)和XiNet(72.27%),同时保持了低于1亿MACs的计算成本和320KB的SRAM占用。
🎯 应用场景
该研究成果可广泛应用于资源受限的嵌入式设备,例如智能传感器、可穿戴设备和物联网设备。通过设计高效且可解释的TinyML模型,可以实现本地化的智能分析和决策,降低对云端计算的依赖,提高数据安全性和隐私性。未来,该方法有望推动TinyML技术在医疗健康、工业自动化和智能家居等领域的应用。
📄 摘要(原文)
This paper introduces a novel framework for designing efficient neural network architectures specifically tailored to tiny machine learning (TinyML) platforms. By leveraging large language models (LLMs) for neural architecture search (NAS), a vision transformer (ViT)-based knowledge distillation (KD) strategy, and an explainability module, the approach strikes an optimal balance between accuracy, computational efficiency, and memory usage. The LLM-guided search explores a hierarchical search space, refining candidate architectures through Pareto optimization based on accuracy, multiply-accumulate operations (MACs), and memory metrics. The best-performing architectures are further fine-tuned using logits-based KD with a pre-trained ViT-B/16 model, which enhances generalization without increasing model size. Evaluated on the CIFAR-100 dataset and deployed on an STM32H7 microcontroller (MCU), the three proposed models, LMaNet-Elite, LMaNet-Core, and QwNet-Core, achieve accuracy scores of 74.50%, 74.20% and 73.00%, respectively. All three models surpass current state-of-the-art (SOTA) models, such as MCUNet-in3/in4 (69.62% / 72.86%) and XiNet (72.27%), while maintaining a low computational cost of less than 100 million MACs and adhering to the stringent 320 KB static random-access memory (SRAM) constraint. These results demonstrate the efficiency and performance of the proposed framework for TinyML platforms, underscoring the potential of combining LLM-driven search, Pareto optimization, KD, and explainability to develop accurate, efficient, and interpretable models. This approach opens new possibilities in NAS, enabling the design of efficient architectures specifically suited for TinyML.